Clear Sky Science · nl
Een aanpak voor het omgaan met ongelijke datasets met behulp van grensverschuiving
Waarom zeldzame gevallen ertoe doen in alledaagse data
Van bankfraude en medische diagnose tot het voorspellen van klantverloop: veel beslissingen die we computers laten nemen hangen af van het herkennen van zeldzame maar cruciale gebeurtenissen. In de meeste echte datasets worden deze belangrijke gevallen sterk overtroffen door gewone voorbeelden. Een model dat vooral "business as usual" ziet, kan blind worden voor precies die situaties waarin we het meest geïnteresseerd zijn. Dit artikel presenteert een nieuwe manier om zulke scheve data te herbalanceren, zodat leeralgoritmen voldoende aandacht besteden aan de zeldzame, hoog‑impactgevallen.
De verborgen valkuil van scheve data
Als het ene type voorbeeld het andere sterk overtreft, neigen standaard machine‑learningmethoden ertoe zich op de meerderheid te concentreren en de minderheid stilletjes te verwaarlozen. Een churn‑voorspellingssysteem kan bijvoorbeeld bijna iedereen als trouwe klant bestempelen en toch een hoge nauwkeurigheid melden, simpelweg omdat echte vertrekkers zo zeldzaam zijn. Vergelijkbare problemen doen zich voor bij ongevallenherkenning, fraudebewaking en medische screening, waar positieve gevallen schaars maar kostbaar zijn om te missen. Traditionele oplossingen vallen in twee categorieën: het aanpassen van het leeralgoritme zodat het meer om de minderheid geeft, of het herstructureren van de data zelf door ofwel sommige meerderheidscases te verwijderen (undersampling) of extra minderheidscases te creëren (oversampling). Populaire oversamplingtools zoals SMOTE genereren synthetische minderheidsexemplaren, maar ze kunnen onbedoeld de delicate grenszone waar de twee klassen elkaar ontmoeten vervuilen.
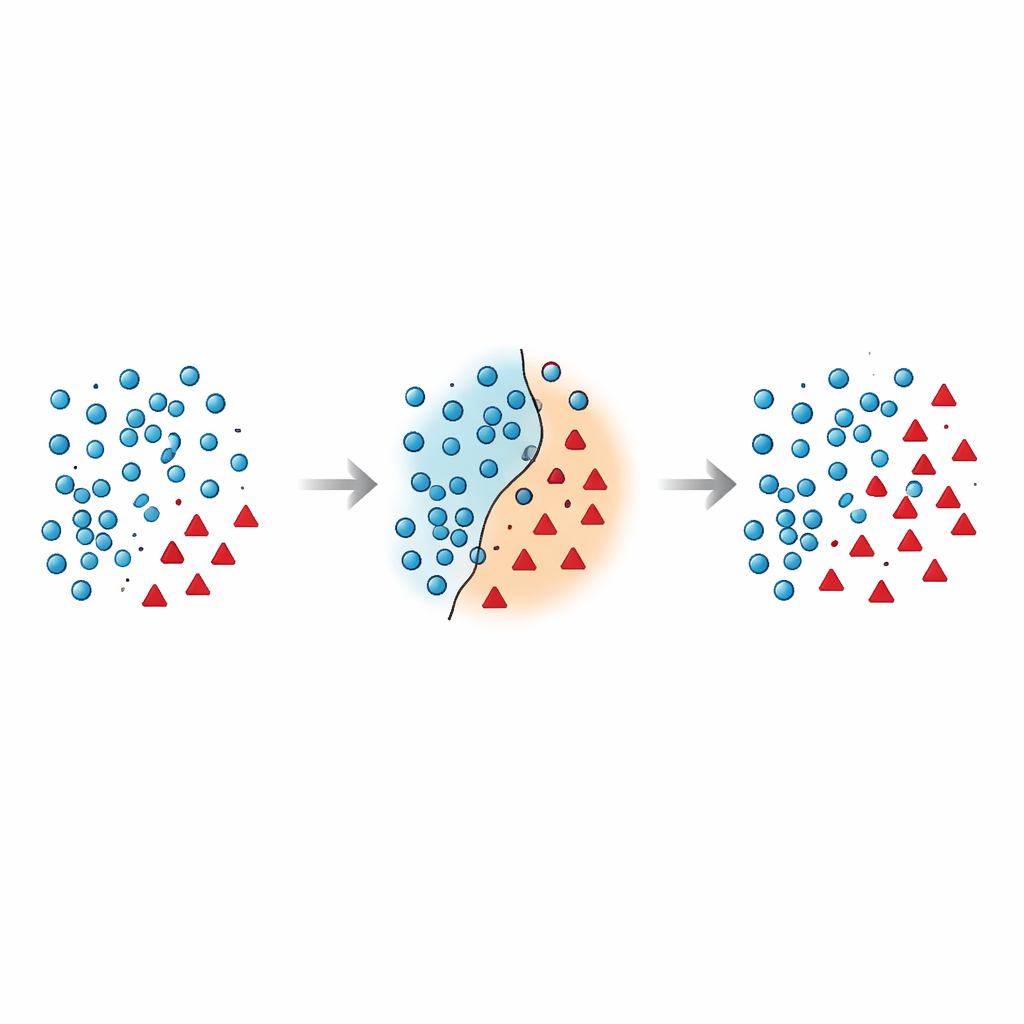
Waarom de grens tussen groepen zo kwetsbaar is
De auteurs betogen dat de gevaarlijkste fouten zich voordoen dicht bij de beslissingsgrens – de zone waar meerderheid en minderheid overlappen in de feature‑ruimte. Veel bestaande technieken voegen synthetische punten in dit risicovolle gebied toe zonder het op te schonen, of ze verwijderen agressief data en raken per ongeluk informatieve voorbeelden kwijt. Recente onderzoeken proberen dit te temmen met geometrische beperkingen, lokale dichtheidsschattingen of ruisfilters, maar de meeste methoden behandelen minderheidspunten op hun plaats en heroverwegen zelden hoe meerderheidspunten nabij die grens behandeld zouden moeten worden. Dit laat een hardnekkig probleem achter: overlappende en lawaaierige voorbeelden die de classifier verwarren en leiden tot onstabiele voorspellingen, vooral op nieuwe data.
Een tweestapsmethode om de grens op te ruimen
Het artikel introduceert Borderline Shifting Oversampling (BSO), een meerfasige data‑herstructureringsmethode die expliciet deze problematische grenszone target. Eerst scant het de buurt van ieder meerderheidsexemplaar om te bepalen of het zich in een veilige zone, op de grens, of op een duidelijk verkeerde plaats (ruis) bevindt. Meerderheidspunten die omringd zijn door minderheidsburen worden ofwel naar de minderheidszijde hergeclassificeerd of als ruis gemarkeerd en verwijderd, waarmee de grens effectief wordt schoongemaakt en verschoven zodat deze de onderliggende structuur beter weerspiegelt. In de tweede fase genereert de methode nieuwe synthetische minderheidspunten met een SMOTE‑achtige interpolatie, maar alleen rond minderheidsexemplaren nabij de verfijnde grens. Door nieuwe data te concentreren waar ze het meest informatief is en duidelijk lawaaierige plekken te vermijden, bouwt BSO een trainingsset die zowel meer in balans qua omvang als schoner van structuur is.
De methode op de proef gesteld
Om te zien hoe dit in de praktijk werkt, evalueerden de onderzoekers BSO op 30 benchmarkdatasets met verschillende graden van ongelijkheid en overlap. Ze vergeleken het met zeven veelgebruikte alternatieven, waaronder Random Over‑ en Under‑Sampling, SMOTE, Borderline‑SMOTE, NearMiss en twee hybride methoden die oversampling met ruisopschoning combineren (SMOTE‑Tomek en SMOTE‑ENN). Drie gangbare classifiers – Support Vector Machines, Naïve Bayes en Random Forests – werden getraind op elk geresampled dataset. In plaats van te vertrouwen op ruwe nauwkeurigheid, gebruikte de studie metrics die onder ongelijkheid informatiever zijn, zoals F1‑score, G‑mean, recall, precision en het gebied onder de ROC‑curve (AUC). Over bijna alle datasets en classifiers behaalde BSO hogere of vergelijkbare scores en toonde het minder variatie, wat betekent dat de voordelen consistent waren in plaats van gebonden aan een specifiek model of instelling.
Wat dit betekent voor beslissingen in de echte wereld
In dagelijkse termen werkt de Borderline Shifting‑aanpak als een zorgvuldige redacteur voor rommelige data: hij ruimt verwarrende voorbeelden op dicht bij de scheidslijn tussen klassen en voegt vervolgens precies genoeg realistische minderheidscases toe op de juiste plekken. Het resultaat is dat leeralgoritmen beter worden in het herkennen van zeldzame maar belangrijke gebeurtenissen zonder misleid te worden door lawaaierige overlappingen. Voor toepassingen zoals fraudedetectie, ongevallensvoorspelling of medische triage — waar het missen van een minderheidscasus kostbaar kan zijn — biedt deze methode een praktische manier om modellen eerlijker, gevoeliger en betrouwbaarder te maken, met slechts een bescheiden extra rekenkundige overhead.
Bronvermelding: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Trefwoorden: klasse-ongelijkheid, oversampling, beslissingsgrens, anomaliedetectie, robuustheid van machine learning