Clear Sky Science · nl
Een methode om geografische objecten op satelliet afbeeldingskaarten samen te stellen op basis van vectorkaartgegevens via deep learning
Waarom het belangrijk is wat kaarten tonen
Online kaarten voelen vaak als ramen naar de echte wereld, maar wat je van boven ziet is zorgvuldig ontworpen. Satellietbeeldkaarten worden gewaardeerd omdat ze op echte plaatsen lijken, maar soms moeten we gevoelige locaties verbergen, rommelige scènes opschonen of ervoor zorgen dat verschillende kaarttypen overeenkomen. Dit artikel presenteert een nieuwe manier om satellietbeelden automatisch te "bewerken" met kunstmatige intelligentie, zodat gebouwen en wegen verwijderd, toegevoegd, verschoven of van vorm veranderd kunnen worden terwijl de afbeelding er nog steeds natuurlijk en overtuigend uitziet. 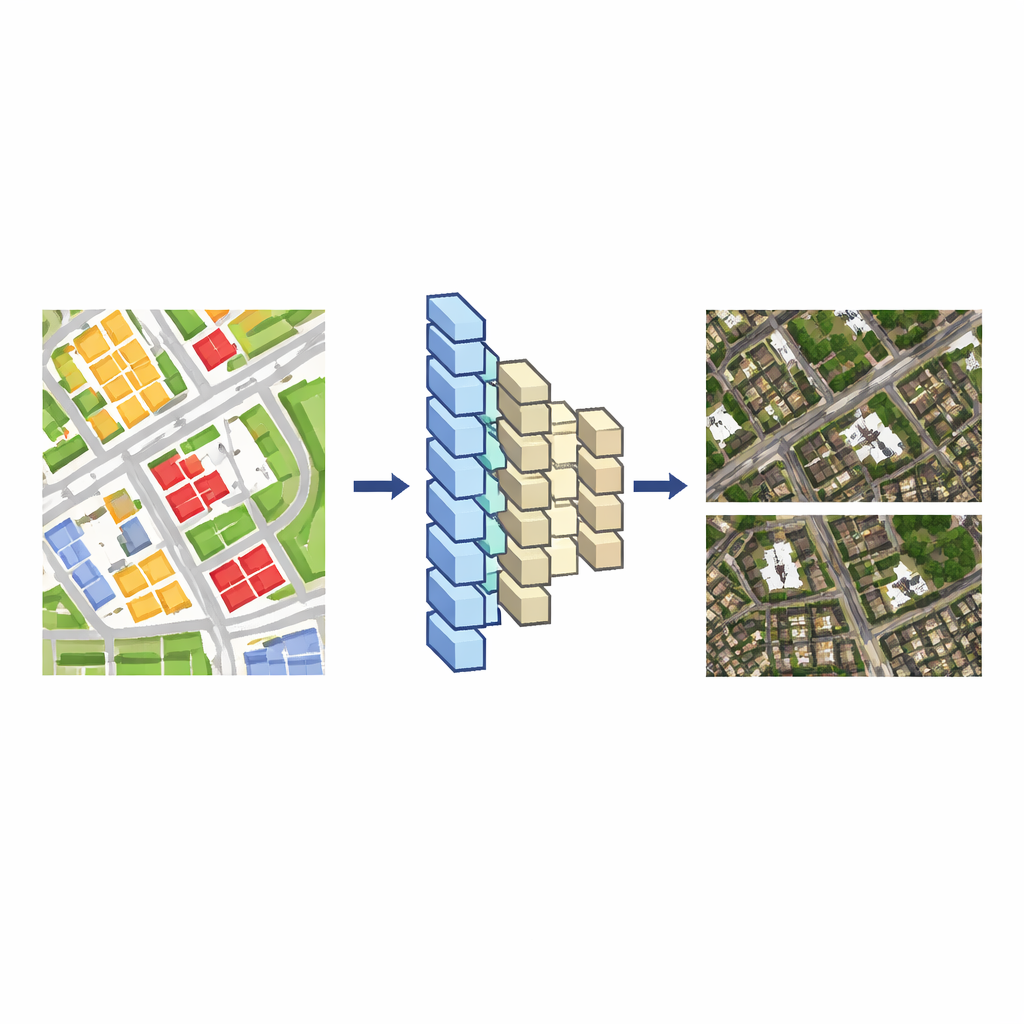
Van eenvoudige tekeningen naar realistische weergaven
Moderne kaartsystemen bevatten gewoonlijk twee soorten geografische gegevens. De ene is de satellietfoto zelf, een dicht mozaïek van pixels. De andere is een vectorkaart, een schonere tekening van lijnen en vormen die wegen, gebouwen, rivieren en meer markeren. De vectorkaart bewerken is relatief eenvoudig, maar de bijpassende satellietfoto handmatig aanpassen is traag en arbeidsintensief, omdat de pixels van elk gebouw overlopen in schaduwen, bomen en nabijgelegen structuren. Het kernidee van de auteurs is een deep-learningmodel te leren vertalen van deze vectortekeningen naar realistische satellietbeelden. Zodra het model deze koppeling heeft geleerd, kan elke wijziging in de vectorkaart automatisch worden omgezet in een consistente wijziging in de satellietweergave.
Een AI leren steden voor te stellen
Om deze vertaler te bouwen, beginnen de onderzoekers met gebieden waar een vectorkaart en een satellietbeeld dezelfde regio op vergelijkbare schaal beslaan. Ze knippen beide in veel kleine tegels, koppelen elke vectortegel aan de overeenkomstige afbeeldingstegel en gebruiken deze paren als trainingsdata. Een encoder–decoder neuraal netwerk—vergelijkbaar met gereedschap dat wordt gebruikt voor image-to-image translation—leert hoe de rangschikking van gekleurde vlakken en lijnen in de vectortegel zich verhoudt tot daken, straten en begroeiing in de satelliettegel. Ze vergelijken twee veelgebruikte netwerkontwerpen, UNet++ en Pix2Pix, en concluderen dat Pix2Pix satellietachtige beelden produceert die nauwer bij de werkelijkheid aansluiten en betrouwbaar trainen, zodat het hun basismodel wordt.
Het model richten op de te wijzigen plekken
Alleen leren van de hele stad is niet genoeg wanneer je specifieke objecten nauwkeurig wilt aanpassen. Om de vaardigheid van het model rond doelgebieden aan te scherpen, gebruiken de auteurs transfer learning. Ze halen extra trainingstegels uit die de gebouwen of wegen omringen die ze van plan zijn te bewerken en voeren een korte extra trainingsfase uit met alleen deze lokale voorbeelden. Deze fine-tuningstap verbetert sterk hoe goed het model die buurten reproduceert, waardoor latere bewerkingen scherper en preciezer ogen. 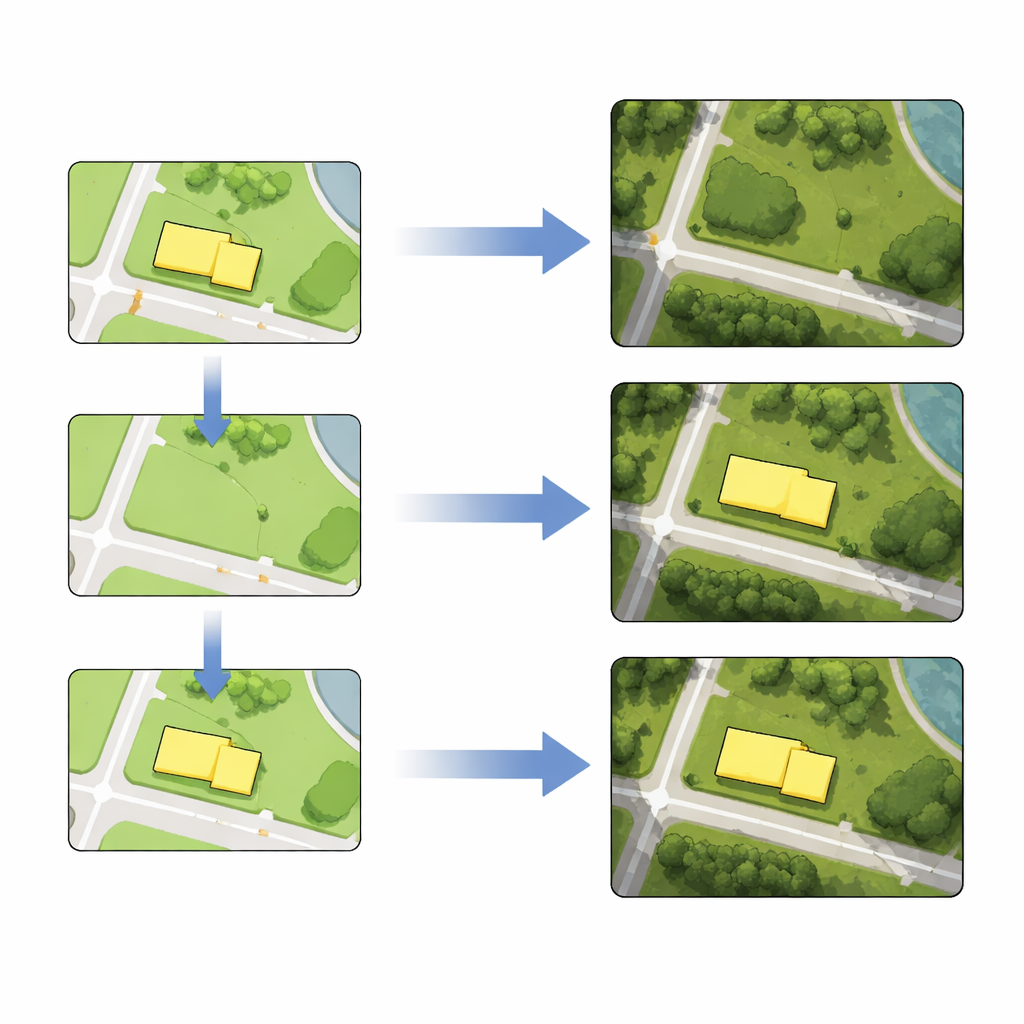
Gebouwen en wegen bewerken als kaartlagen
Met het getunede model is het samenstellen van satellietbeeldkaarten een recept in drie stappen. Ten eerste bewerkt een cartograaf de vectorkaart: een gebouw verwijderen, een nieuwe weg tekenen, een blok van vorm veranderen of een object naar een nieuwe positie verplaatsen. Ten tweede worden de bewerkte tegels van de vectorkaart in het getrainde netwerk gevoed, dat nieuwe satelliettegels genereert die de bedoelde wijziging weerspiegelen terwijl omliggende details en textuur behouden blijven. Ten derde vervangen deze gegenereerde tegels de oorspronkelijke afbeeldingstegels. Met echte gegevens uit Berlijn demonstreren de auteurs alle vier bewerkingen—verwijdering, invoeging, vervorming en verplaatsing—zowel voor gebouwcontouren als voor weglijnen, afzonderlijk of in batches. Metingen tonen aan dat de posities van bewerkte objecten in de gegenereerde beelden slechts enkele pixels afwijken van hun vector-tegenhangers, een nauwkeurigheid die voor veel kaartwerkzaamheden acceptabel is.
Wat dit betekent voor toekomstige kaarten
In eenvoudige bewoordingen toont de studie dat zodra een AI heeft geleerd hoe vectorkaarten en satellietbeelden overeenkomen, je de eenvoudige tekening kunt bewerken en het model een geloofwaardige luchtfoto kunt laten herschilderen om overeen te komen. Dit opent de deur naar satellietbeeldkaarten die op maat gemaakt kunnen worden: het verbergen van gevoelige locaties, het verduidelijken van complexe scènes of het mengen van echte en ingebeelde ruimtes zoals spelwerelden en virtuele omgevingen. Tegelijkertijd benadrukt het de kracht—en het risico—van "deepfake"-geografie, waarbij realistisch ogende luchtbeelden mogelijk niet langer directe foto’s van de wereld zoals die is.
Bronvermelding: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Trefwoorden: satellietbeelden, deep learning, kaartbewerking, remote sensing, deepfake-cartografie