Clear Sky Science · nl
Grote taalmodellen tonen Dunning-Kruger-achtige effecten bij meertalige factchecking
Waarom slimme factchecking belangrijk is voor iedereen
Misinfo verspreidt zich nu sneller dan ooit en bepaalt wat mensen geloven over gezondheid, politiek, wetenschap en het dagelijks leven. Veel platforms en redacties vertrouwen steeds meer op kunstmatige intelligentie—vooral grote taalmodellen (LLM’s)—om te helpen beoordelen of virale beweringen waar of onwaar zijn. Deze studie stelt een ogenschijnlijk simpele maar cruciale vraag: als we deze systemen feiten laten beoordelen, hoe vaak hebben ze dan gelijk, hoe zeker gedragen ze zich, en verandert dat tussen talen en regio’s in de wereld?
Hoe de onderzoekers AI testten tegen echte geruchten
In plaats van kunstmatige voorbeelden te verzinnen, bouwden de auteurs hun tests op basis van 5.000 echte beweringen die professionele factcheckorganisaties wereldwijd al hadden onderzocht. Deze beweringen besloegen 47 talen en kwamen zowel uit het Globale Noorden als het Globale Zuiden, en weerspiegelden zo de rommelige, multiculturele realiteit van online geruchten. Alleen uitspraken met duidelijke "waar"- of "onwaar"-uitspraken—waarover meerdere factcheckers het eens waren—werden opgenomen, wat een sterke grondwaarheid voor vergelijking opleverde.
Vervolgens lieten ze negen veelgebruikte taalmodellen draaien, van kleinere open-source systemen tot geavanceerde commerciële modellen, op elke bewering. Om te spiegelen hoe mensen daadwerkelijk met chatbots praten, waren de meeste prompts eenvoudige vragen zoals “Is dit waar?” of “Is dit onwaar?”, geschreven in dezelfde taal als de bewering. Een vierde, meer professionele opzet gebruikte een gedetailleerde instructie in het Engels die het model veranderde in een virtuele factchecker en om gestructureerde outputs vroeg. Menselijke annotatoren lazen de antwoorden van de modellen zorgvuldig en labelden ze als stellend dat de bewering waar was, onwaar, of weigerend een duidelijke uitspraak te doen.
Niet alleen goed of fout meten, maar ook weten wanneer te zeggen: “Ik weet het niet”
Het team telde meer dan hits en misses. Ze gebruikten drie kernmaatregelen om het gedrag van de modellen te vangen. Ten eerste keek “selectieve nauwkeurigheid” hoe vaak een model correct was wanneer het daadwerkelijk een standpunt innam en een bewering als waar of onwaar bestempelde. Ten tweede beschouwde “onthoudingsvriendelijke nauwkeurigheid” het als acceptabel, zelfs wenselijk, dat het model onzekerheid toegaf in plaats van te gissen—wat cruciaal is in gevoelige domeinen zoals de geneeskunde of verkiezingen. Ten derde volgde de “zekerheidsratio” hoe vaak een model überhaupt een definitief antwoord gaf, als ruwe maat voor hoe zelfverzekerd het zich gedroeg.
De professionele prompt, met stapsgewijze instructies, verhoogde consequent de nauwkeurigheid over alle modellen heen. Maar het toonde ook een afweging: kleinere modellen werden vaak besluitvaardiger zonder betrouwbaarder te worden, terwijl grotere modellen de structuur gebruikten om minder, maar betere, antwoorden te geven. Alledaagse, chatachtige prompts leidden tot voorzichtiger gedrag, vooral bij zwakkere modellen, maar verlaagden ook enigszins hun nauwkeurigheid.
Wanneer minder capabele systemen zich zelfverzekerder gedragen
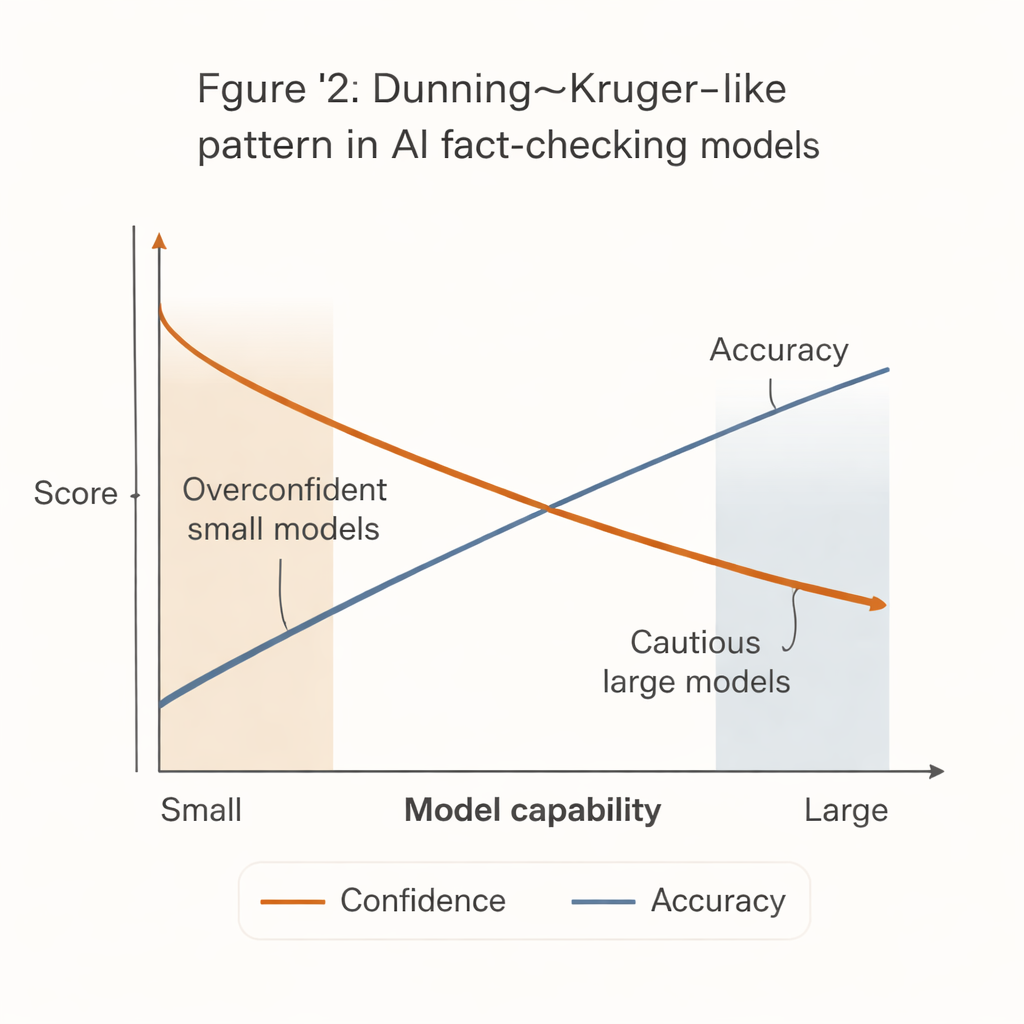
Er ontstond een opvallend patroon dat lijkt op het bekende Dunning–Kruger-effect uit de psychologie: de minst capabele systemen gedroegen zich het meest zelfverzekerd. Kleine, goedkope modellen gaven doorgaans stellige uitspraken bij een groot deel van de beweringen, maar met duidelijk lagere nauwkeurigheid. Daarentegen waren de krachtigste modellen—zoals geavanceerde GPT-versies—veel nauwkeuriger wanneer ze wel een uitspraak deden, maar waren ze ook veel eerder geneigd te onthouden, vooral bij moeilijke of ambigue uitspraken.
Deze "zekerheid–bekwaamheidskloof" heeft echte gevolgen. Veel krappe redacties, maatschappelijke organisaties en lokale factcheckers kunnen zich de krachtigste AI-systemen niet veroorloven. Zij zullen eerder kleinere, goedkopere modellen gebruiken die besluitvaardig lijken maar vaker fout zitten. Als deze tools zonder zorgvuldige waarborgen in workflows of community-moderatiesystemen worden ingebouwd, zouden ze desinformatie juist kunnen versterken door zelfverzekerde maar incorrecte factchecks te produceren.
Ongelijke prestaties tussen talen en regio’s
De studie laat ook zien dat deze systemen niet voor iedereen even goed presteren. Over meerdere grote talen presteerden modellen over het algemeen het best op Engelse beweringen en iets minder goed op Portugees en Hindi. Grotere modellen reageerden doorgaans terughoudender in niet-Engelse talen, maar waren nog steeds nauwkeuriger dan kleinere modellen. Toen de auteurs beweringen vergeleken die verbonden waren aan het Globale Noorden versus het Globale Zuiden, struikelden de meeste modellen vaker bij het laatstgenoemde. Kleinere systemen bleven vaak zelfverzekerd terwijl hun nauwkeurigheid afnam, terwijl grote modellen grotere dalingen in zekerheid maar kleinere dalingen in correctheid lieten zien, wat suggereert dat ze hun eigen onzekerheid aanvoelden en zich terughoudend opstelden.
Wat dit betekent voor de toekomst van betrouwbare AI-tools
Voor een niet-specialist is de kernboodschap helder: de huidige AI-factcheckers zijn verre van gelijkwaardig, en de meest toegankelijke kunnen het misleidendst zijn. Krachtige modellen kunnen voorzichtig en nauwkeurig zijn, maar ze zijn duur en soms te terughoudend. Zwakkere modellen zijn dapper maar vaker fout, vooral buiten het Engels en bij verhalen uit het Globale Zuiden. De auteurs stellen dat AI menselijke factcheckers moet ondersteunen, niet vervangen, en dat beleids- en ontwerpkeuzen moeten streven naar betere calibratie—systemen leren wanneer ze stil moeten blijven—en eerlijkere toegang tot hoogwaardige tools. Anders kan dezelfde technologie die is gebouwd om desinformatie te bestrijden, de informatieongelijkheden die ze wil oplossen juist verdiepen.
Bronvermelding: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Trefwoorden: misinformatie, factchecking, grote taalmodellen, AI-zekerheid, meertalige vooringenomenheid