Clear Sky Science · nl
Een humanoïde besturingsstrategie gebaseerd op deep reinforcement learning voor verbeterd comfort in revalidatierobots voor de onderste ledematen
Robots die mensen helpen weer te lopen
Wanneer iemand na een beroerte of ruggenmergletsel moeite heeft met lopen, kan de therapie traag, vermoeiend en onaangenaam zijn. Revalidatierobots voor de onderste ledematen zijn ontworpen om de benen van een patiënt te ondersteunen en te begeleiden tijdens het oefenen, maar de huidige machines voelen vaak stijf en “robotachtig” aan. Deze studie onderzoekt hoe het geven van een mensachtiger ‘brein’ aan deze robots — met behulp van geavanceerde leeralgoritmen — de training zachter, natuurlijker en uiteindelijk effectiever voor patiënten kan maken.
Waarom loopoefening natuurlijk moet aanvoelen
Naarmate de bevolking vergrijst, leven meer mensen met ernstige loopproblemen en wenden velen zich tot robotgeassisteerde revalidatie. Traditionele robots volgen voorgeprogrammeerde beenbanen en gebruiken eenvoudige regelregels om de gewrichten te bewegen. Hoewel betrouwbaar, hebben deze methoden moeite met de rommelige realiteit van menselijke beweging: ieders gang is net iets anders, en een stijve robot kan trekken of duwen op manieren die ongemakkelijk of zelfs pijnlijk aanvoelen. De auteurs beargumenteren dat voor effectieve revalidatie de robot niet alleen de patiënt rechtop en in beweging moet houden, maar ook moet aanpassen aan natuurlijke looppatronen en de krachten die hij op het lichaam uitoefent moet minimaliseren.
Leren van echte menselijke stappen
Om de robot te leren hoe mensen werkelijk lopen, bouwden de onderzoekers eerst een vereenvoudigd wiskundig model van de benen en romp. Vervolgens namen ze gangdata op van vijf gezonde vrijwilligers met een hoogprecisie 3D-motion-capturesysteem en krachtplaten in de vloer. Reflecterende markers op heupen, knieën, enkels en romp maakten het mogelijk te berekenen hoe elk gewricht door een volledige stap bewoog, terwijl sensoren onder de voeten maten hoe hard elk been tegen de grond drukte. Vanuit deze metingen creëerden ze vloeiende referentiecurven voor heup- en kniehoeken en volgden ze hoe gewrichtskrachten in de loop van de tijd veranderden, waarmee zowel de vorm als het ritme van normaal lopen werd vastgelegd.
Een slimere controller die toch veilig blijft
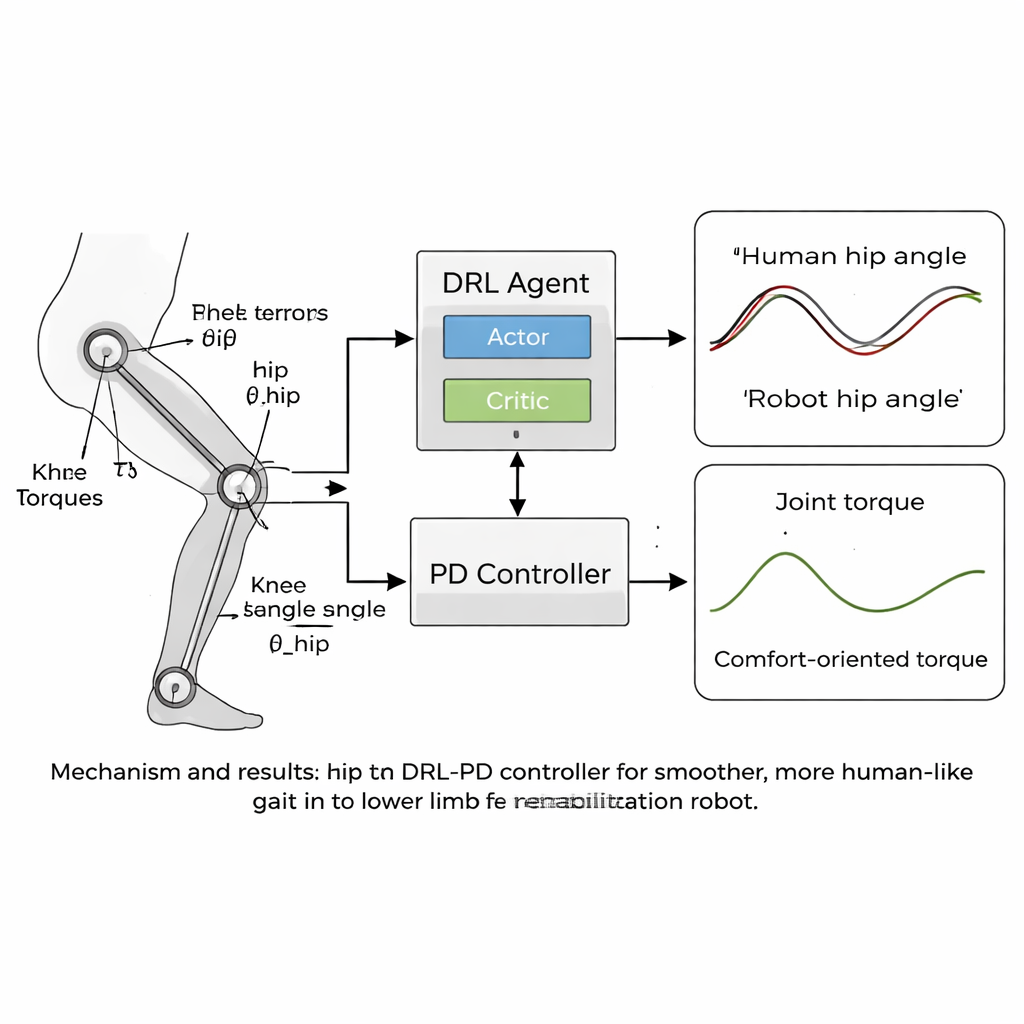
De kern van het artikel is een nieuwe “humanoïde” besturingsstrategie die deep reinforcement learning (DRL) combineert met een klassieke proportioneel-differentieel (PD) controller. DRL is een type kunstmatige intelligentie waarbij een virtuele agent acties probeert, de resultaten observeert en geleidelijk ontdekt wat het beste werkt door een beloningssignaal te maximaliseren. In dit geval zit de agent bovenop de PD-controller: hij ziet de gewrichtshoeken en snelheden van de robot en beslist welke torques toe te passen, terwijl de PD-laag ervoor zorgt dat de gewrichten niet ver afwijken van veilige, mensachtige doelhoeken. De beloningsfunctie is zorgvuldig ontworpen om stabiel voorwaarts lopen aan te moedigen en tegelijk alles te bestraffen wat onaangenaam zou voelen voor een patiënt — zoals schokkerige bewegingen, grote krachten in de gewrichten of onveilige houdingen zoals overmatige voorover- of zijwaartse helling of lage voetschoenruimte.
Soepeler bewegingen, dichterbij menselijke gang
Het team testte hun benadering in computersimulaties met een model van een revalidatierobot voor de onderste ledematen met heup- en kniegewrichten die overeenkwamen met hun gangdata. In duizenden trainingsepisodes leerde de DRL-PD-controller een repeterende loopsymmetrie te produceren waarbij de gewrichtshoeken de menselijke referentiepatronen nauw volgden. De heupen en knieën van de robot bewogen in regelmatige, stabiele lussen, een teken van betrouwbare, herhaalbare gang. Cruciaal was dat de torques die nodig waren om de gewrichten aan te drijven gladder en kleiner werden vergeleken met een standaard PD-controller. Kwantitatieve metingen toonden aan dat de volgfouten daalden tot slechts enkele honderdsten van een radiaal, en dat de snelheid waarmee gewrichtstorques veranderden — een proxy voor hoe ‘schokkerig’ de krachten voor een patiënt zouden aanvoelen — met meer dan de helft werd verminderd. De controller bleef ook stabiel toen de beenmassa’s van het model met enkele procenten werden gevarieerd, wat suggereert dat hij reële verschillen tussen gebruikers zou kunnen verdragen.
Wat dit betekent voor toekomstige revalidatierobots
Voor niet-specialisten is de kernboodschap eenvoudig: door een robot de ritmes en grenzen van menselijk lopen uit echte data te laten leren, en door hem te belonen voor soepel en zacht bewegen, kunnen we machines ontwerpen die mensen helpen lopen op een manier die natuurlijker en minder belastend aanvoelt. Patiënten zijn mogelijk eerder geneigd om zich langer en vaker in sessies in te zetten als de robot met hen mee beweegt in plaats van tegen hen in. Hoewel de huidige resultaten uit simulaties komen en krachtige computers vereisen voor het trainen, kan de controller eenmaal geleerd efficiënt op echte apparaten draaien. De auteurs zien dit werk als een stap richting gepersonaliseerde, adaptieve revalidatierobots die zich aanpassen aan het unieke looppatroon en comfort van elke patiënt, wat mogelijk zowel herstel als kwaliteit van leven verbetert.
Bronvermelding: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Trefwoorden: revalidatierobots, looptraining, deep reinforcement learning, exoskelet, patiëntcomfort