Clear Sky Science · nl
Fijnafgestelde grote taalmodellen met gestructureerde prompts maken efficiënte constructie van longkanker-kennisgrafen mogelijk
Waarom het omzetten van medische tekst in kaarten ertoe doet
Longkanker is een van de dodelijkste vormen van kanker en informatie over de diagnose en behandeling ervan staat versnipperd in onderzoeksartikelen, ziekenhuisnotities, online consulten en traditionele geneeskundige casussen. Artsen en onderzoekers hebben moeite om deze stroom van tekst bij te houden. Deze studie onderzoekt een nieuwe manier om die verspreide kennis automatisch om te zetten in één doorzoekbare "kaart"—een kennisgraaf voor longkanker—met behulp van een fijnafgesteld groot taalmodel en zorgvuldig gestructureerde prompts. Het doel is om complexe medische kennis gemakkelijker door computers doorzoekbaar te maken en bruikbaar voor experts in ondersteunende beslissingssystemen.
Van verspreide verhalen naar verbonden feiten
De auteurs richten zich op een eenvoudig idee: als je op betrouwbare wijze kunt achterhalen wie-wat-wat doet in medische tekst, kun je die feiten aan elkaar rijgen in een graaf. In de praktijk betekent dit vrije zinnen omzetten in kleine bouwstenen die triples worden genoemd—twee entiteiten verbonden door een relatie, zoals “longkanker – behandeld met – chemotherapie.” Traditionele manieren om zulke grafen te bouwen vereisen ofwel legers annotatoren of fragiele regels die nuance en nieuwe ontdekkingen missen. Om dit te overwinnen, fijnstelt het team een bestaand Chinees groot taalmodel, ChatGLM-6B, zodat het gespecialiseerd raakt in het herkennen van medisch betekenisvolle triples over longkanker in een breed scala aan bronnen, van online patiënt–arts-chats tot gestructureerde databanken en documenten uit de traditionele Chinese geneeskunde. 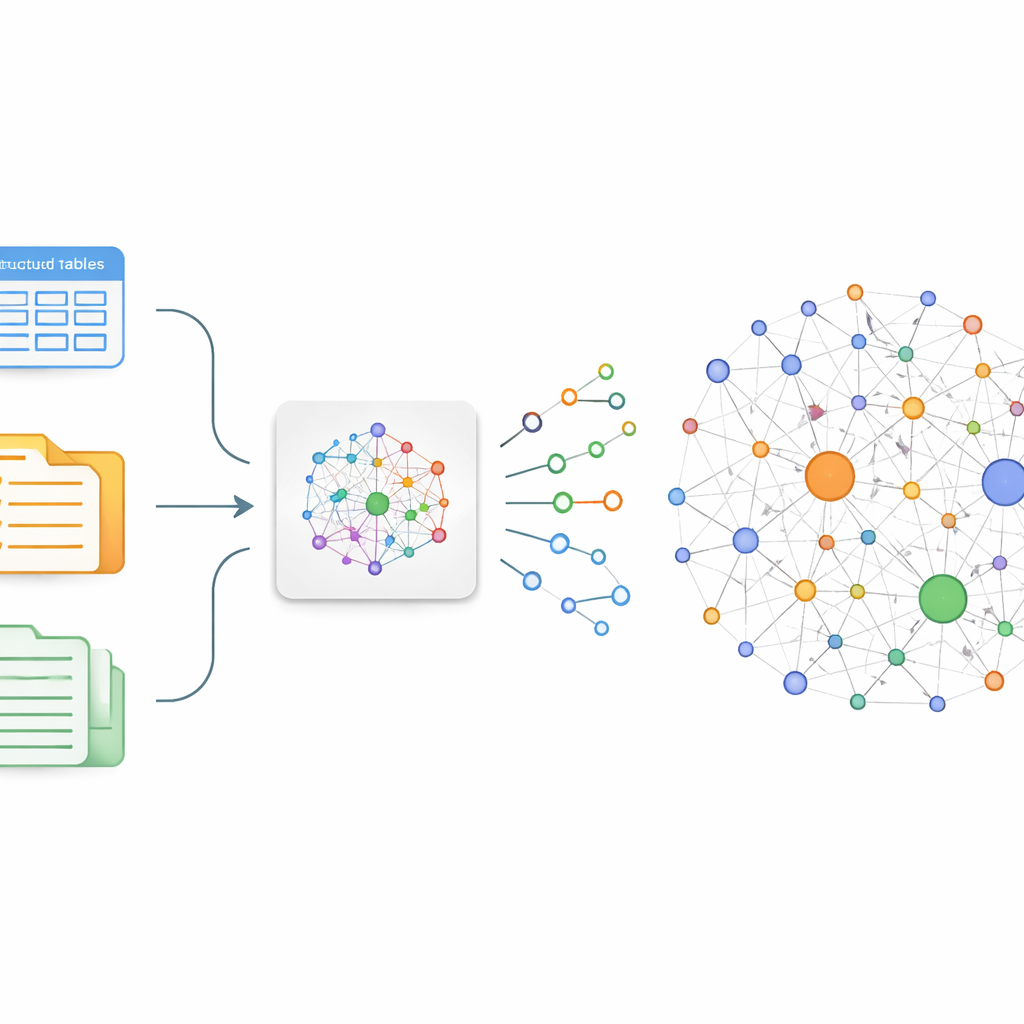
Een AI leren in nette eenheden te denken
Een algemeen taalmodel simpelweg vragen om "informatie te extraheren" levert vaak rommelige, gesprekachtige antwoorden op. De onderzoekers ontwerpen daarom een strikt promptingschema en fintunen het model op bijna 50.000 voorbeelden van gewenst gedrag. Elk voorbeeld toont een instructie en de exacte triple-stijl uitvoer die verwacht wordt. De prompt zegt het model zich te gedragen als een professionele tekstminingexpert, alleen gestructureerde triples in een computerleesbaar formaat te produceren, en "stap voor stap te denken" wanneer zinnen geneste details bevatten—bijvoorbeeld een behandeling, het gebruikte geneesmiddel en de dosering. Deze combinatie van rolkeuze, formatregels en stapsgewijze redenering verandert het model—nu KGLM genoemd—van een conversatieassistent in een gedisciplineerde extractor van machineklare feiten.
Verschillende stemmen samenbrengen in één duidelijke graaf
Ruwe triples uit tekst vormen slechts een deel van het verhaal. Dezelfde ziekte of hetzelfde geneesmiddel verschijnt vaak onder verschillende namen—bijvoorbeeld "chronische obstructieve longziekte" versus "COPD." Om rommel en verwarring te vermijden, ontwerpen de auteurs een fusiefase die equivalente entiteiten samenvoegt over drie gegevensstromen: ongestructureerde webtekst, semi-gestructureerde klinische casussen en bestaande medische kennisgrafen. Eerst markeert een snelle op strings gebaseerde gelijkeniscontrole voor de hand liggende overeenkomsten. Wanneer dat niet volstaat, vergelijkt een dieper semantisch gelijkenheidsmodel (Sentence-BERT) betekenissen in context. Entiteiten die als duplicaten worden beoordeeld, worden samengevoegd tot één canonieke knoop, waarbij kortere namen de voorkeur krijgen en andere vormen als aliassen worden opgeslagen. Experts beoordelen vervolgens randgevallen en verwijderen misleidende of laagwaardige beweringen, wat resulteert in een schonere en coherente longkanker-kennisgraaf opgeslagen in een Neo4j-database. 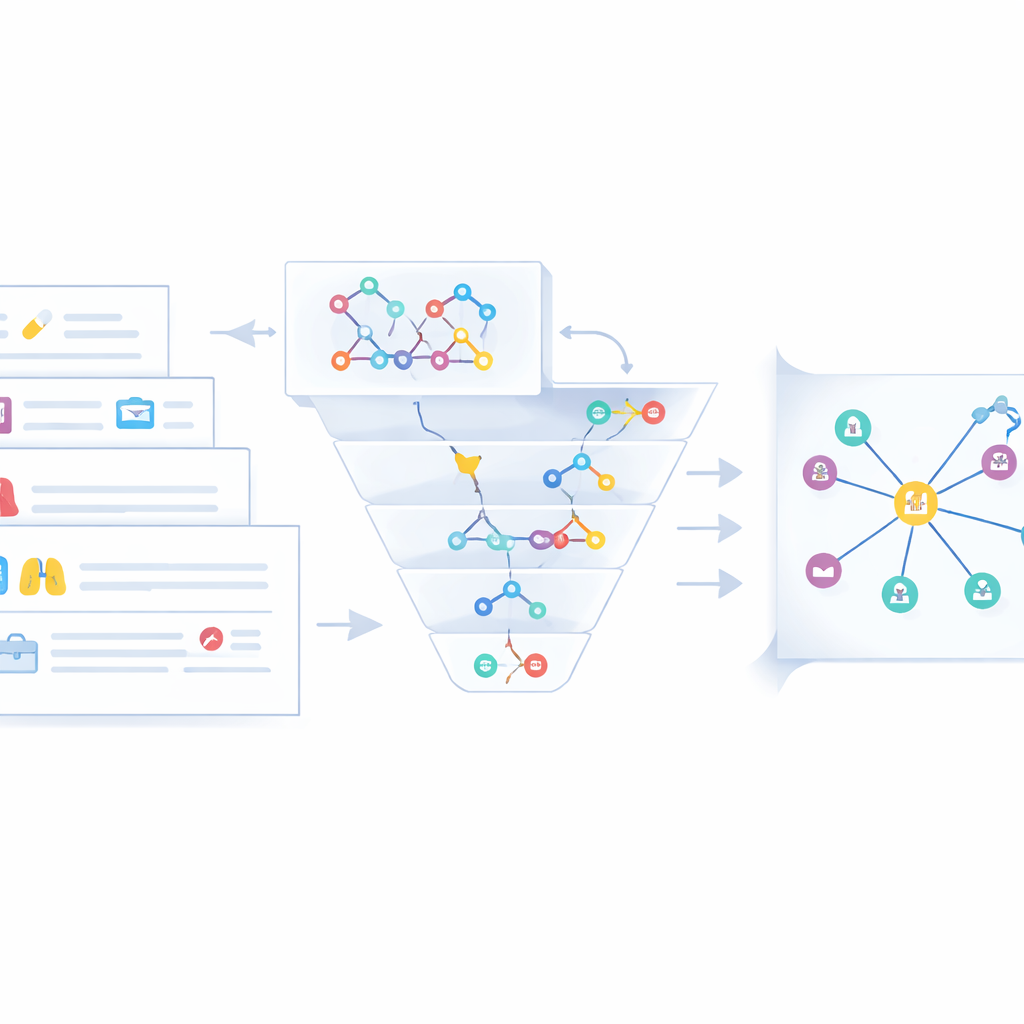
Hoe goed werkt deze kenniskaart?
Om de prestaties te meten vergelijkt het team KGLM met standaard deep learning-benaderingen gebaseerd op BERT en convolutionele netwerken, evenals met het oorspronkelijke, niet-fijnafgestelde ChatGLM-model. Bij de taak van relatie-extractie—bepalen welke entiteiten verbonden zijn en op welke manier—bereikt het fijnafgestelde, prompt-gestuurde KGLM een F1-score van ongeveer 0,82, waarmee het alle geteste referentiemodellen overtreft en ongeveer 25 procent verbetert ten opzichte van het beginnende model. Ablatie-experimenten tonen aan dat elk promptcomponent van belang is: het verwijderen van de expertrol, het strikte triple-formaat of de "stap voor stap"-aanwijzing vermindert de nauwkeurigheid, vooral bij complexe zinnen met geneste attributen of terminologie uit de traditionele Chinese geneeskunde. Een panel van klinische en informatica-experts beoordeelt bovendien dat de resulterende graaf nauwkeuriger, bruikbaarder en klinisch relevanter is dan grafen die zijn gebouwd zonder fijnafstemming of gestructureerde prompts.
Wat dit betekent voor toekomstige medische hulpmiddelen
Simpel gezegd toont de studie aan dat met de juiste training en instructies een groot taalmodel rommelige, real-world longkankertekst efficiënt kan omzetten in een gestructureerd, doorzoekbaar web van feiten. Deze longkanker-kennisgraaf, hoewel nog steeds een onderzoeksprototype en beperkt tot Chinese bronnen en één ziektegebied, wijst op een toekomst waar voortdurend bijgewerkte "kenniskaarten" beslissingsondersteunende systemen, educatieve tools en onderzoeksondersteuning kunnen voeden. De auteurs benadrukken dat zulke grafen zorgvuldig gevalideerd en regelmatig bijgewerkt moeten worden en niet klaar zijn om zonder deskundig toezicht beslissingen in de zorg te sturen. Toch suggereren hun resultaten dat fijnafgestelde taalmodellen plus slimme prompting het ontmoedigende werk van het organiseren van medische kennis schaalbaarder en tijdiger kunnen maken.
Bronvermelding: Zhou, C., Gong, Q., Luan, H. et al. Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs. Sci Rep 16, 9505 (2026). https://doi.org/10.1038/s41598-026-38959-w
Trefwoorden: longkanker, kennisgraaf, groot taalmodel, relatie-extractie, medische AI