Clear Sky Science · nl
Een tweevoudig deep learning-kader voor continue gebarentaalherkenning ter verbetering van communicatieve toegankelijkheid in de regio Ha’il
De kloof in communicatie overbruggen
Voor veel dove mensen is gebarentaal de belangrijkste manier van communiceren, maar de meeste computers, telefoons en openbare diensten begrijpen die taal nog steeds niet. Dit artikel presenteert een nieuw systeem met kunstmatige intelligentie dat continue gebaren in video kan volgen en nauwkeuriger kan omzetten in geschreven woorden. Door niet alleen aandacht te besteden aan handbewegingen maar ook aan hoofdpositie en gezichtsuitdrukkingen, streeft het systeem ernaar technologiegebaseerde communicatie natuurlijker en toegankelijker te maken — vooral voor dove gemeenschappen in de regio Ha’il in Saoedi-Arabië, waar digitale ondersteuning nog beperkt is. 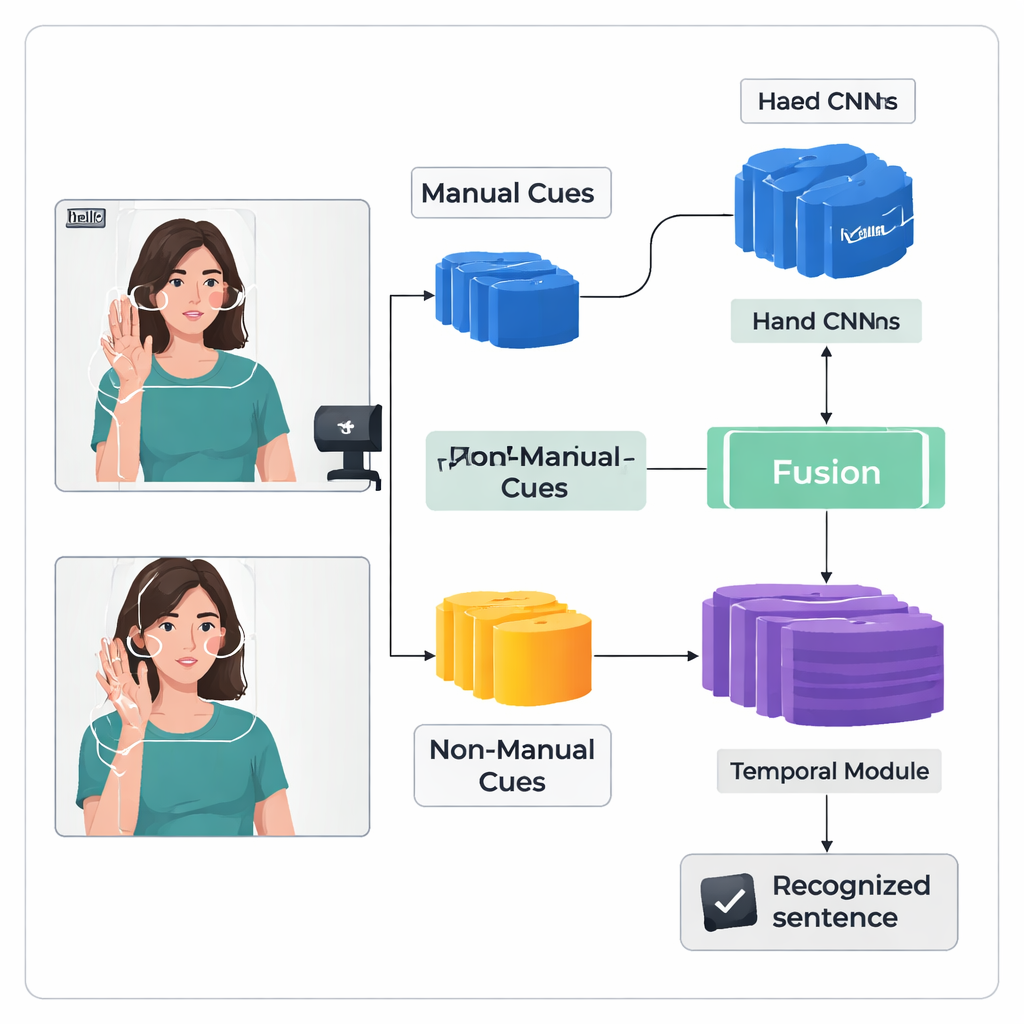
Waarom handen niet genoeg zijn
Gebarentalen zijn rijke, complexe systemen die het hele bovenlichaam gebruiken. Betekenis komt niet alleen voort uit hoe de handen bewegen, maar ook uit gezichtsuitdrukkingen, waar de gebarende persoon naar kijkt en hoe het hoofd helt of knikt. Deze niet-hand signalen kunnen vragen, ontkenning, klemtoon of emotie markeren. Mensen lezen dit moeiteloos, maar de meeste computersystemen voor gebarentaalherkenning richten zich vrijwel uitsluitend op de handen. Die eenvoud maakt training makkelijker maar zorgt ervoor dat belangrijke aanwijzingen verloren gaan, vooral wanneer gebaren vloeiend in snelle, continue zinnen in plaats van geïsoleerde woorden voorkomen.
Twee stromen die parallel werken
De auteurs introduceren een "dual-stream" deep learning-kader genaamd TS-CNN dat handen en hoofd afzonderlijk verwerkt en die informatie vervolgens samenbrengt. De ene stroom richt zich op bijgesneden beelden van de handen van de gebarende persoon en leert patronen van vorm, beweging en positie. De andere stroom ontvangt een compacte kaart van gezicht en hoofd, afgeleid van landmarkpunten en schattingen van hoofdpose. Beide stromen gebruiken een standaard type vision-netwerk om elk videoframe om te zetten in numerieke kenmerken. Het systeem fuseert deze kenmerken frame voor frame, met respect voor het feit dat hand- en hoofdsignalen gelijktijdig optreden bij echt gebaren. Een later tijdelijk module kijkt over veel frames heen om te begrijpen hoe gebaren zich in de tijd ontvouwen, en een recurrente laag produceert een reeks voorspelde gebareneenheden, of glossen.
Het geheugen voor gebaren verscherpen
Het herkennen van continue gebaren is moeilijk omdat trainingsdata beperkt zijn en gebaren in elkaar overvloeien zonder duidelijke frame-voor-frame labels. Om dit aan te pakken voegen de auteurs een Feature Enhancement Module toe die het netwerk extra begeleiding geeft tijdens training. Een veelgebruikte techniek lijnt de voorspelde glossreeks uit met de video en genereert waarschijnlijke posities voor elke gloss in de tijd. De nieuwe module neemt deze uitlijningssuggesties en gebruikt ze als directe supervisie om de interne representatie van glosskenmerken te verfijnen. Simpel gezegd leert het systeem niet alleen de juiste reeks uit te voeren, maar ook duidelijkere, consistentere interne “herinneringen” op te bouwen van hoe elk gebaar eruitziet in verschillende video’s.
De aanpak op de proef stellen
Het team evalueert TS-CNN op twee bekende datasets voor gebarentaal: RWTH-PHOENIX-Weather 2014 voor Duitse Gebarentaal en CSL Split II voor Chinese Gebarentaal. Ze meten de prestatie met behulp van de woordfoutpercentage (word error rate), een standaardmaat vergelijkbaar met die in spraakherkenning. In vergelijking met een basislijn die alleen naar handbewegingen kijkt, vermindert het toevoegen van hoofdpose-informatie fouten met ongeveer 4 procentpunten in de Duitse dataset en 3–4 punten in de Chinese dataset. Het toevoegen van de feature enhancement module levert nog grotere verbeteringen op, met een foutreductie van ruwweg 10–14 procent overall op beide datasets. Het systeem draait bovendien efficiënt en bereikt realtime snelheden op een moderne grafische processor, wat cruciaal is als het in live interpretatie of mobiele hulpmiddelen gebruikt moet worden. 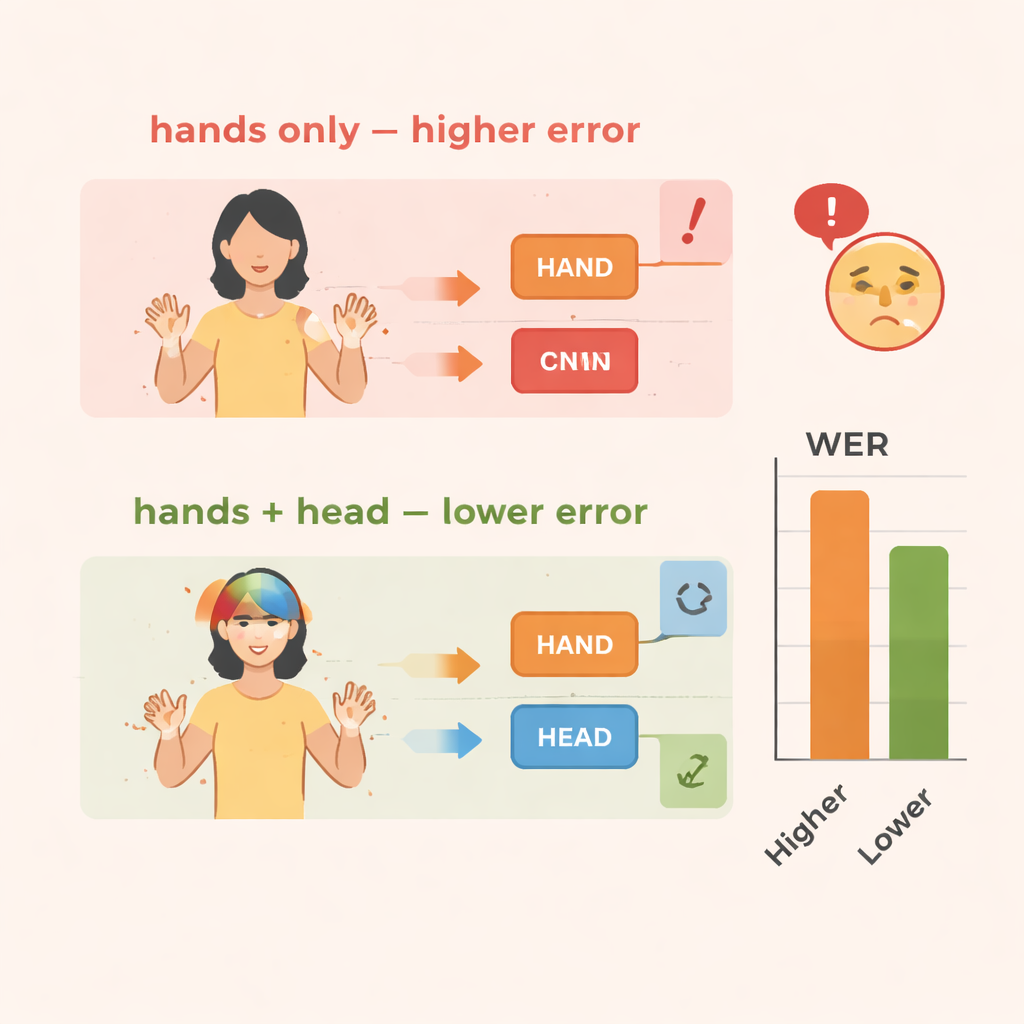
Wat dit betekent voor het dagelijks leven
In praktische termen laat dit onderzoek zien dat computers gebarentaal betrouwbaarder kunnen begrijpen wanneer ze de hele gebarende persoon observeren, niet alleen de handen. Door hoofdbewegingen en gezichtsaanwijzingen naast handbewegingen te modelleren en zorgvuldig te verfijnen hoe het leert van beperkte trainingsdata, komt het TS-CNN-kader dichter bij praktische systemen die dove mensen kunnen ondersteunen in klaslokalen, ziekenhuizen en overheidskantoren. Voor regio’s zoals Ha’il, waar menselijke tolken schaars zijn en technologische projecten nog in ontwikkeling, zou zo’n systeem uiteindelijk meer inclusieve communicatie kunnen ondersteunen — en zo de kloof tussen gebarenden en horenden helpen dichten zonder de rijke, menselijke ervaring van het gebaren zelf te vervangen.
Bronvermelding: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Trefwoorden: herkenning van gebarentaal, deep learning, toegankelijkheid, computerzicht, mens–computerinteractie