Clear Sky Science · nl
Een methode voor databescherming bij voorspelling van infectieziekten met gebalanceerde leersnelheid en nauwkeurigheid
Waarom het beschermen van gezondheidsgegevens nog steeds belangrijk is
Ziekenhuizen en gezondheidsinstanties vertrouwen tegenwoordig op kunstmatige intelligentie om uitbraken van griep, COVID-19 en andere infecties dagen of weken van tevoren te voorspellen. Deze voorspellingen kunnen vaccinatiecampagnes, personeelsplanning en noodplannen sturen. Tegelijkertijd zijn de gedetailleerde patiëntgegevens die voorspellingen nauwkeurig maken ook uiterst gevoelig. Wetten en publieke bezorgdheid belemmeren vaak het samenvoegen van gegevens tussen instellingen, wat de kracht van deze modellen verzwakt. Dit artikel introduceert een manier om hoogwaardige voorspellingssystemen voor infectieziekten te trainen terwijl de gegevens van elk ziekenhuis veilig ter plekke vergrendeld blijven.
Leren van veel ziekenhuizen zonder dossiers te delen
De auteurs bouwen voort op een techniek genaamd federated learning, waarbij meerdere ziekenhuizen samen een gedeeld voorspellingsmodel trainen. In plaats van ruwe patiëntgegevens naar een centrale server te kopiëren, traint elk site het model lokaal en stuurt alleen numerieke updates van de interne instellingen van het model terug. Een centrale server combineert deze updates en stuurt het verbeterde model weer terug. Deze lus herhaalt zich vele malen. In theorie beschermt federated learning de privacy omdat persoonlijke informatie het gebouw nooit verlaat. In de praktijk kunnen slimme aanvallers echter soms details over de onderliggende data afleiden uit de gedeelde updates, dus extra bescherming is nodig. 
De cijfers vergrendelen met slimme encryptie
Om de beveiliging te versterken gebruikt het team homomorfe encryptie—een vorm van digitale vergrendeling die het mogelijk maakt berekeningen rechtstreeks op versleutelde getallen uit te voeren, zonder ze ooit in platte tekst te zien. Traditionele schema’s van dit type zijn zeer veilig maar berucht traag en veeleisend qua data, waardoor ze moeilijk toepasbaar zijn bij grote, complexe modellen zoals die op basis van Long Short-Term Memory (LSTM)-netwerken. De onderzoekers ontwerpen een hybride schema dat verschillende delen van het model verschillend behandelt. De meest veelzeggende componenten worden beschermd met een sterke maar zware vorm van encryptie, terwijl minder gevoelige delen een lichtere, snellere vergrendeling gebruiken. Daarbovenop bepaalt een vooraf gepland willekeurig schema in welke trainingsronden sites daadwerkelijk versleutelde updates verzenden, waardoor ze redundante communicatie kunnen overslaan. Tests tonen aan dat deze combinatie de training met ongeveer 25 procent versnelt vergeleken met het overal toepassen van de zware encryptie, terwijl de gegevens onder sterke cryptografische aannames beschermd blijven.
Alleen de updates versturen die echt tellen
Zelfs met slimere vergrendeling is het heen en weer sturen van elk klein modelwijziginkje tussen instellingen tijdrovend en verspilt het netwerkbandbreedte. De auteurs stellen daarom een nieuwe trainingsregel voor genaamd Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD). Tijdens het trainen meet het algoritme hoeveel elk deel van het model verandert van de ene stap naar de volgende. Alleen updates die een vooraf ingestelde drempel overschrijden worden verzonden; kleine, laag-impact veranderingen worden simpelweg genegeerd. Tegelijkertijd houdt het algoritme bij welke gegevenspunten verantwoordelijk zijn voor de grootste, meest informatieve veranderingen. Deze invloedrijke dossiers worden verzameld in een verfijnde dataset die wordt gebruikt voor een laatste trainingsronde. Experimenten op drie jaar aan echte infectierapporten uit de stad Yichang, gecombineerd met lokale webzoeksignalen, tonen aan dat DS-DSSGD de trainingstijd met ongeveer 10 procent verkort vergeleken met meerdere standaardmethoden, zonder noemenswaardig verlies aan voorspellende nauwkeurigheid.
Een praktisch platform voor veilige samenwerking
Technische vooruitgang doet er alleen toe als ziekenhuizen en laboratoria ze daadwerkelijk kunnen gebruiken. Om deze kloof te dichten integreert het team hun methoden in een echte rekencapaciteit genaamd het Yi Shu Fang XDP Privacy Security Computing Platform. XDP beheert de volledige levenscyclus van gezondheidsgegevens, van verzamelen en schoonmaken tot versleutelde analyse en delen van resultaten. Het ondersteunt vertrouwde tools die gebruikt worden door statistici, bioinformatici en clinici, en stelt onderzoekers van verschillende instellingen in staat samen te werken binnen een gecontroleerde werkomgeving zonder ooit ruwe data te downloaden. Binnen dit platform draaien het hybride encryptieschema en het DS-DSSGD-algoritme als inplugbare componenten, waardoor het theoretische kader in een werkend systeem wordt omgezet. 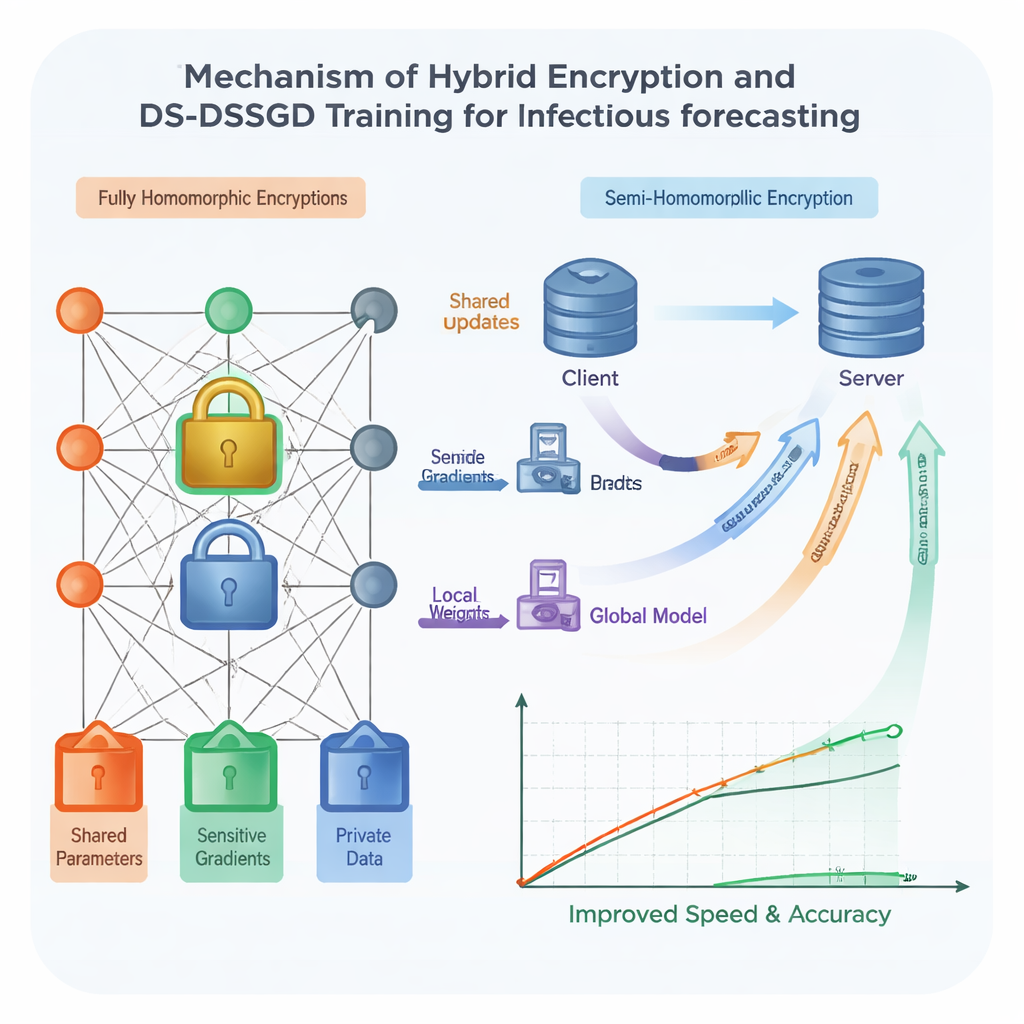
Wat dit betekent voor toekomstige uitbraakvoorspelling
In gewone bewoordingen laat deze studie zien dat het mogelijk is om “het beste van twee werelden te hebben” voor de voorspelling van infectieziekten: patiëntprivacy beschermen terwijl er toch snel en nauwkeurig wordt getraind op data uit veel instellingen. Door verschillende delen van het model te versleutelen met precies het juiste sterkte-niveau, updates alleen te verzenden wanneer dat nodig is, en alles in een veilig samenwerkingsplatform te verpakken, verminderen de auteurs de kosten van privacy van een verlammende last tot een beheersbare overhead. Bij brede toepassing zouden dergelijke benaderingen ziekenhuizen en volksgezondheidsinstanties in staat kunnen stellen hun kennis te bundelen tegen de volgende epidemie zonder ooit individuele medische dossiers bloot te geven.
Bronvermelding: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Trefwoorden: voorspelling van infectieziekten, privacy van gezondheidsgegevens, federated learning, homomorfe encryptie, deep learning