Clear Sky Science · nl
Het schatten van soortalgemeenheid en -voorkomen met onbewaakte methoden
Waarom het tellen van gewone en zeldzame soorten ertoe doet
Wanneer we ons natuur in gevaar voorstellen, denken we vaak aan zeldzame dieren op de rand van uitsterven. Toch bestaat het grootste deel van het levende weefsel om ons heen uit heel gewone soorten die veel voorkomen of juist stilletjes verdwijnen voordat iemand het merkt. Kunnen vaststellen hoe wijdverspreid een soort werkelijk is op een bepaalde locatie is essentieel om te voorspellen hoe ecosystemen zullen reageren op vervuiling, landgebruik of klimaatverandering. Dit artikel introduceert een manier om tegelijk te schatten hoe algemeen of zeldzaam veel soorten zijn, met alleen bestaande waarnemingsgegevens en moderne data-analyse. Het doel is objectievere invoer te leveren voor computermodellen die voorspellen waar soorten nu en in de toekomst kunnen leven.
Van eenvoudige waarnemingen naar grote ecologische vragen
Ecologen gebruiken routinematig computermodellen, zogenaamde ecologische nichemodellen, om uit te zoeken welke omgevingen geschikt zijn voor een soort. Deze modellen helpen voorspellen waar een soort mogelijk zal voorkomen bij veranderend klimaat of in nieuwe regio’s. Een cruciale factor is “voorkomen” (prevalentie) – ruwweg het aandeel onderzochte locaties waar een soort aanwezig is. Het drukt uit of een soort naar verwachting veel of weinig voorkomt vóórdat nieuwe onderzoeken worden uitgevoerd. Die a priori verwachting bepaalt sterk hoe modellen ruwe geschiktheidsscores omzetten in kans op voorkomen en hoe ze onderscheid maken tussen “aanwezig” en “afwezig” op een kaart. Als de prevalentie slecht wordt ingeschat, vooral voor zeldzame soorten, kunnen voorspellingen misleidend zijn en kunnen beschermingsplannen zich op de verkeerde gebieden richten.
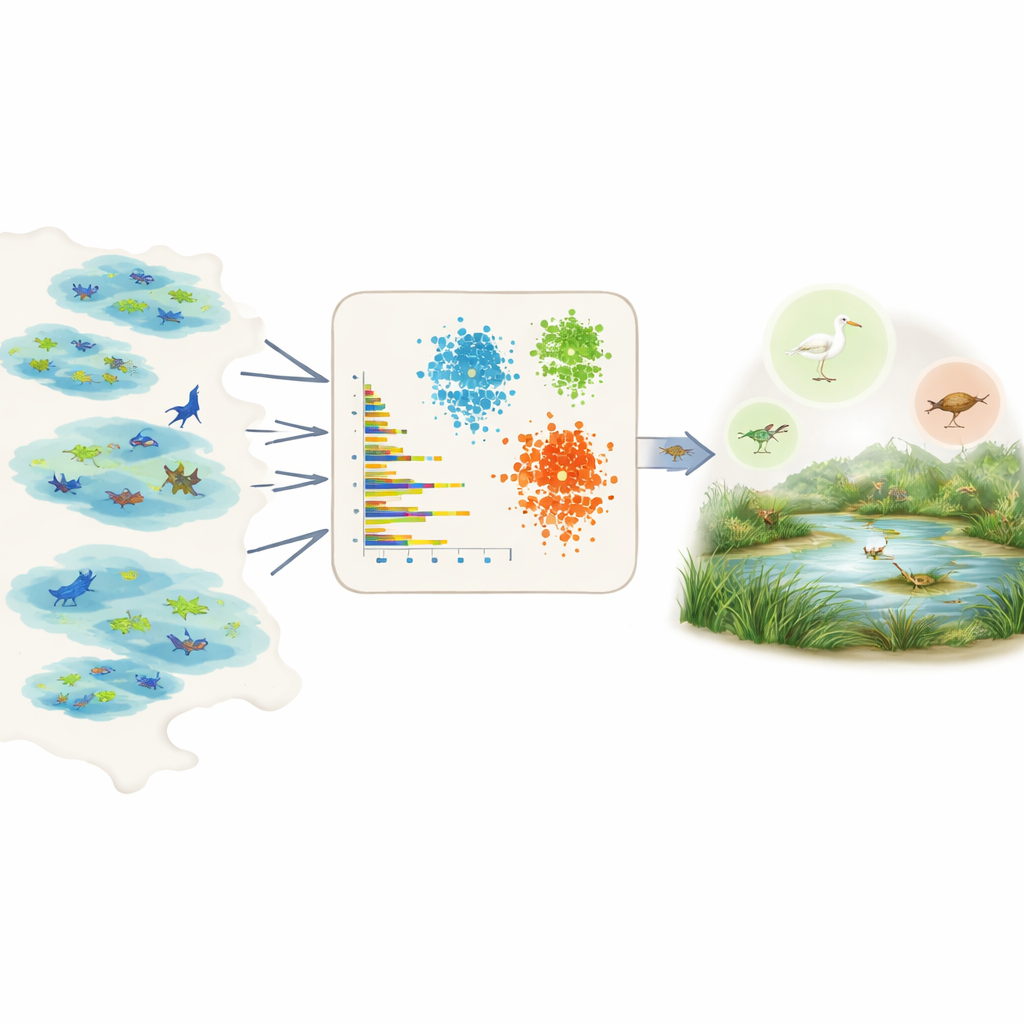
De data laten spreken voor honderden soorten
Prevalentie direct meten is lastig omdat veldgegevens gefragmenteerd en bevooroordeeld zijn. Sommige gebieden zijn intensief onderzocht, sommige soorten zijn makkelijker te zien, en veel waarnemingen komen uit burgerwetenschapsprojecten met wisselende inspanning. In plaats van te vertrouwen op deskundige inschatting of gedetailleerde kennis voor elke soort, putten de auteurs uit de Global Biodiversity Information Facility, een enorme open database van soortenwaarnemingen. Voor elke soort in een gekozen regio vatten ze de ruwe gegevens samen in een paar eenvoudige, vergelijkbare cijfers: hoeveel individuen er gewoonlijk per waarneming worden gerapporteerd, in hoeveel verschillende datasets of wetlands de soort voorkomt, hoe wijdverspreid ze is binnen die wetlands, en hoe vaak ze in de tijd wordt waargenomen, inclusief hoe vaak er pieken van veel waarnemingen zijn.
Machines leren gewone en zeldzame soorten te onderscheiden
Met deze samenvattende kenmerken past het team drie onbewaakte leermethoden toe – twee clustertechieken en een diep neuraal model bekend als een variational autoencoder – die naar patronen zoeken zonder vooraf te worden verteld welke soorten algemeen of zeldzaam zijn. De clusteringmethoden groeperen soorten die vergelijkbare abundantie, verspreiding en waarnemingsfrequentie delen. De autoencoder leert wat een “typische” soortwaarneming is en markeert ongewone patronen als anomalieën, die vaak overeenkomen met zeldzame of slecht waargenomen soorten. De modellen wijzen vervolgens elke soort toe aan drie intuïtieve klassen – zeer algemeen, tamelijk algemeen of zeldzaam – en zetten die klassen om in numerieke prevalentiewaarden die rechtstreeks kunnen worden gebruikt als a priori-kansen in ecologische nichemodellen.
De aanpak testen in een kwetsbaar moeras
Om te zien hoe goed dit kader in de praktijk werkt, richten de auteurs zich op het Massaciuccoli-meerbekken in Toscane, Italië, een laaggelegen moeras met veel vogels, vissen, insecten en andere dieren. Dit landschap is zowel een hotspot voor biodiversiteit als een toeristische trekpleister, maar het is ook kwetsbaar voor klimaatverandering, waterschaarste en vervuiling. Voor 161 diersoorten die aan het meer verbonden zijn, werden de modellen getraind met gegevens van andere Italiaanse wetlands en vervolgens gevraagd in te schatten hoe algemeen elke soort zou moeten zijn in Massaciuccoli. Twee lokale deskundigen met uitgebreide veldervaring in het gebied beoordeelden onafhankelijk dezelfde soorten. Vergeleken met die experts stemde het diepgaande leermodel ongeveer 81–90 procent van de soorten overeen met het gecombineerde expertsbeeld, terwijl de clusteringmethoden en een ensemble van alle drie ook goed presteerden.
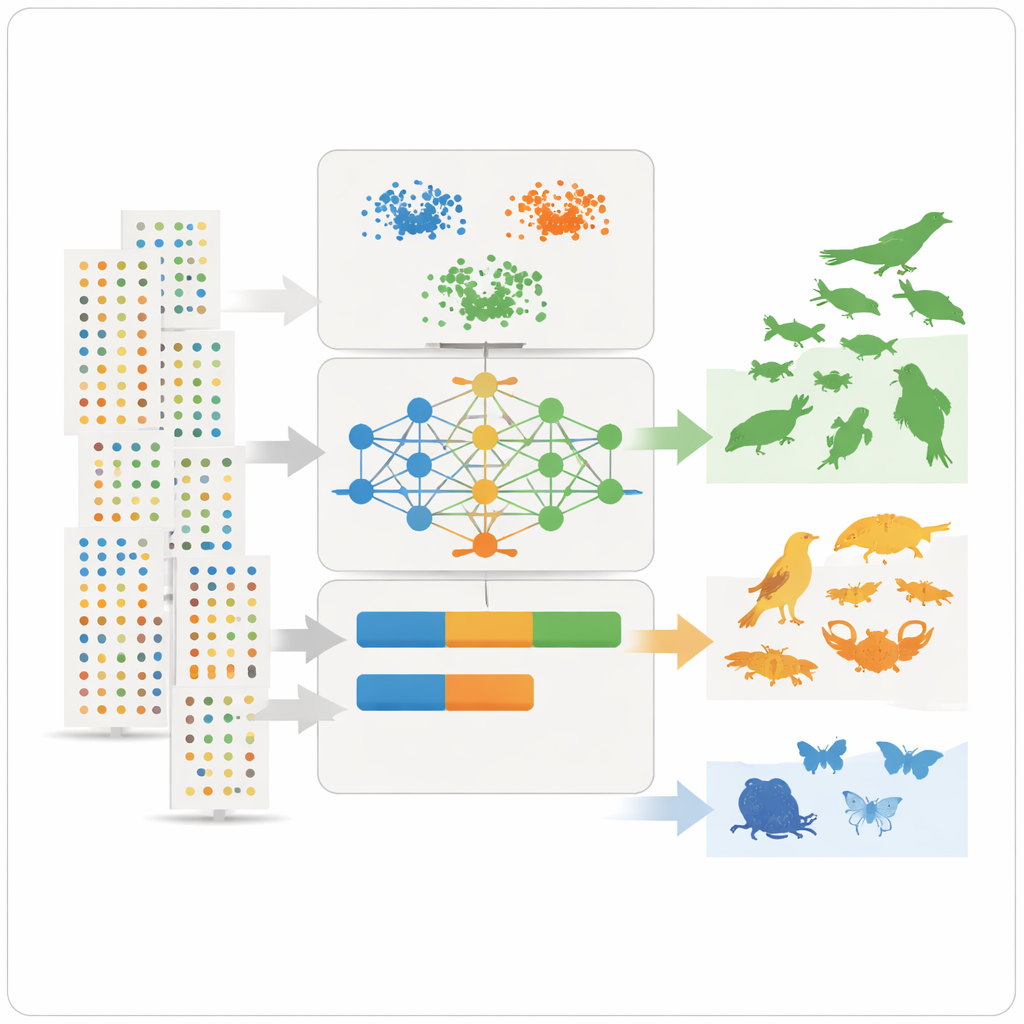
Leren van meningsverschillen en verborgen vooringenomenheden
Niet elk geval kwam perfect overeen. Een paar soorten die door experts als talrijk rond het meer werden gezien, leken in de data zeldzaam, vaak omdat ze schuw zijn, ondergerapporteerd of in sommige wetlands intensiever worden gevolgd dan in andere. Dit benadrukte een belangrijke beperking: grote databases weerspiegelen waar en hoe mensen naar natuur zoeken, niet alleen waar soorten werkelijk voorkomen. Een gevoeligheidsanalyse liet zien welke kenmerken het meest van belang waren voor de classificaties: het gemiddelde aantal records per dataset, de abundantie per waarneming en de consistentie van waarnemingen over de jaren bleken bijzonder informatief. Ondanks resterende vertekeningen leverde de methode duidelijke, reproduceerbare prevalentieschattingen op en kan ze worden bijgesteld naar fijnere of grovere klassen afhankelijk van modelbehoeften.
Wat dit betekent voor toekomstige natuurvoorspellingen
Voor niet-specialisten is de belangrijkste boodschap dat we bestaande biodiversiteitsgegevens nu slimmer kunnen gebruiken om in te schatten welke soorten waarschijnlijk algemeen, middelniveau of zeldzaam zijn in een bepaalde omgeving, zonder elke casus handmatig af te stemmen. Door rumoerige waarnemingsgegevens om te zetten in transparante, data-gedreven prevalentieschattingen helpt het kader ecologische modellen realistischere voorspellingen te maken over habitatgeschiktheid en toekomstige biodiversiteitstrends. Dat kan op zijn beurt betere planning ondersteunen voor wetlands zoals Massaciuccoli en vele andere ecosystemen wereldwijd, zelfs wanneer veldgegevens incompleet zijn en deskundige tijd beperkt.
Bronvermelding: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Trefwoorden: soortvoorkomen, biodiversiteitsmodellering, moerasecosystemen, machine learning ecologie, soortalgemeneheid