Clear Sky Science · nl
Seriële gecascadeerde hybride adaptieve diepe netwerken-gebaseerde classificatie van songteksten met optimalisatiebenadering
Waarom slimere songfilters ertoe doen
Muziek stroomt vrijwel ononderbroken ons leven binnen en veel van wat we horen wordt gekozen door algoritmen. Toch worstelen veel van deze systemen nog steeds met een eenvoudige vraag: wat zeggen de woorden in een lied precies en voor wie zijn ze geschikt? Dit artikel pakt dat probleem aan door een geavanceerd kunstmatig-intelligentie (AI)-model te bouwen dat automatisch songteksten leest en ze sorteert op stemming, genre, sentiment en zelfs type uitvoerder. Het doel is veiligere afspeellijsten voor kinderen, nauwkeurigere aanbevelingen op basis van stemming en betere hulpmiddelen voor muziekonderzoekers.
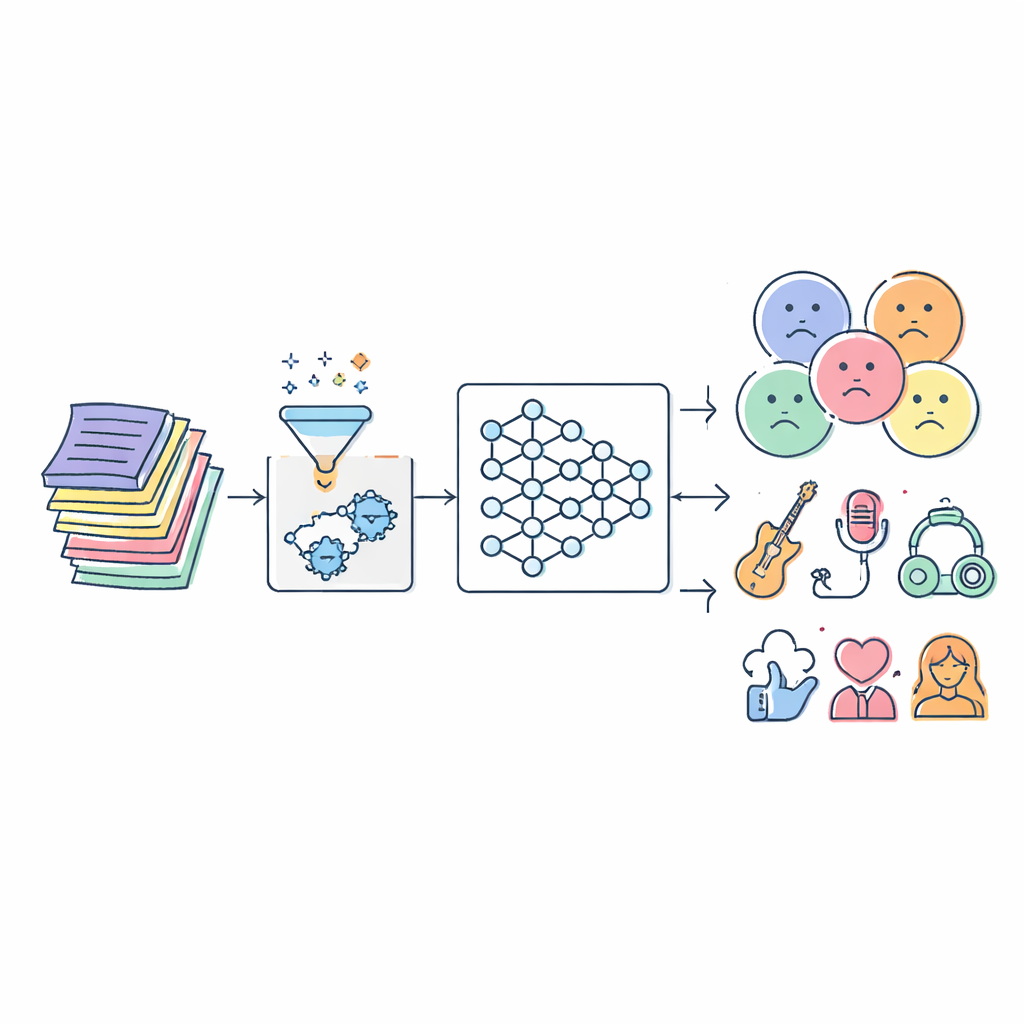
De uitdaging verborgen in songwoorden
Songteksten zijn veel complexer dan een lijst met goede of slechte woorden. Dezelfde zin kan in het ene lied teder voelen en in het andere bedreigend, en luisteraars brengen hun eigen ervaringen mee in wat ze horen. Traditionele filters vertrouwen meestal op statische lijsten met aanstootgevende termen of eenvoudige statistische technieken. Deze benaderingen missen context, houden geen gelijke tred met veranderende straattaal en labelen vaak verkeerd. Tegelijkertijd betekent de explosie van digitale muziek dat er miljoenen nummers zijn om te analyseren, in veel talen en stijlen, wat handmatige etikettering en oudere algoritmen overweldigt.
De ruwe teksten opschonen
De auteurs beginnen met het samenstellen van grote tekstverzamelingen uit drie openbare datasets die samen honderden duizenden nummers bestrijken in meerdere genres en talen. Voordat een AI van de tekst kan leren, moeten de lyrics worden opgeschoond. Het systeem verwijdert interpunctie, speciale symbolen en herhaalde of irrelevante fragmenten, en reduceert vervolgens verwante woordvormen tot een gemeenschappelijke stam (bijvoorbeeld “zingen”, “zingt” en “zong” worden allemaal “zing”). Deze pre-processingstap verwijdert ruis terwijl de betekenis behouden blijft, zodat latere fasen zich kunnen richten op emotionele toon en onderwerp in plaats van op formaatverschillen of spelfouten.
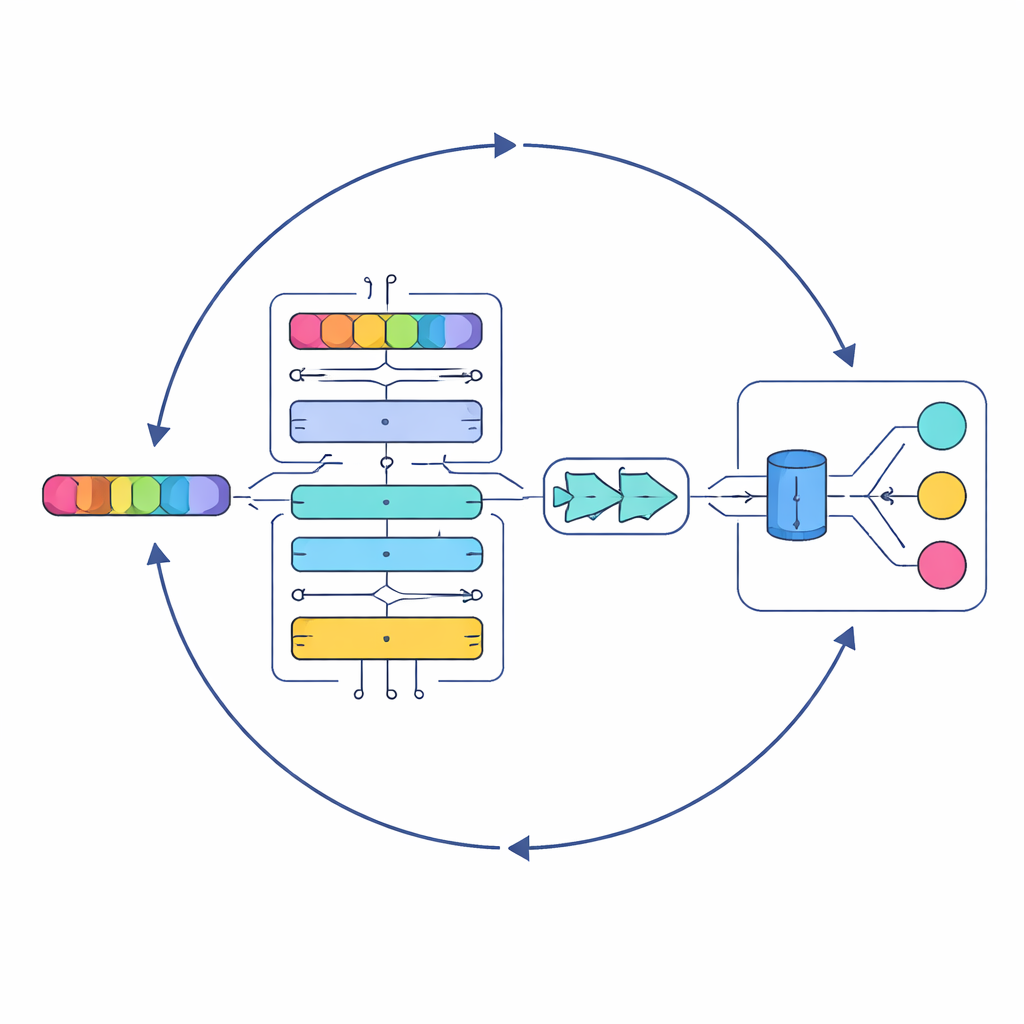
Een gelaagde AI die leest als een aandachtige luisteraar
Centraal in de studie staat een nieuw model genaamd Serial Cascaded Hybrid Adaptive Deep Network, of SCHADNet. Het combineert drie krachtige ideeën uit moderne taal-AI. Ten eerste legt een transformer-gebaseerde encoder vast hoe woorden met elkaar samenhangen over een hele tekst, niet alleen tussen directe buren. Ten tweede leest een bidirectionele Long Short-Term Memory-laag de tekst zowel vooruit als achteruit in de tijd, waardoor het systeem begrijpt hoe eerdere regels de betekenis van latere kleuren. Ten derde verfijnt een Gated Recurrent Unit-laag deze informatie tot een compact samenvattend beeld dat goed geschikt is voor definitieve beslissingen. Samen werken deze componenten als een koor van gespecialiseerde lezers, elk gefocust op andere aspecten van de songtekst.
Een strategie lenen uit de zee
Het simpelweg stapelen van deep-learninglagen is niet voldoende; hun interne instellingen — zoals het aantal neuronen en de duur van training — beïnvloeden de prestaties sterk. In plaats van deze keuzes met de hand af te stemmen, wenden de auteurs zich tot een optimalisatiebenadering die is geïnspireerd op de jachtpatronen van mariene roofdieren. Hun Improved Marine Predators Algorithm (IMPA) verkent vele mogelijke parametercombinaties en werkt geleidelijk toe naar die welke de beste resultaten opleveren. Door delen van het oorspronkelijke algoritme weg te snijden die in deze setting niet hielpen, verbeteren ze de convergentie, wat betekent dat het systeem sneller en betrouwbaarder tot goede oplossingen komt.
Hoe goed het systeem presteert
De onderzoekers testen SCHADNet met IMPA op drie verschillende lyric-datasets en vergelijken het met een reeks gevestigde methoden, waaronder klassieke machine-learningclassifiers en meerdere populaire deep-learningmodellen zoals pure LSTM-, uitsluitend transformer- en hybride netwerken. Over nauwkeurigheid, recall (hoeveel echt relevante nummers worden gevonden) en andere kwaliteitsmaatstaven komt de nieuwe benadering consequent als beste uit de bus. Op een grote meertalige dataset classificeert het ongeveer 93% van de nummers correct en behaalt het een bijzonder hoge negatieve voorspellende waarde, wat betekent dat het zeer goed is in het herkennen van lyrics die niet in een gemarkeerde categorie thuishoren — cruciaal om overijverige blokkering of mislabeling te vermijden.
Wat dit betekent voor luisteraars en makers
Voor de leek is de boodschap helder: de auteurs hebben een meer genuanceerde, betrouwbare lezer voor songteksten gebouwd. In plaats van te vertrouwen op grove woordlijsten, kijkt hun systeem naar hele zinnen, context en patronen in grote muziekverzamelingen en kent automatisch labels toe zoals stemming, stijl of geschiktheid voor jongere luisteraars. Hoewel het model complex en rekentechnisch zwaar is, opent het de deur naar slimere ouderlijke controles, rijkere stemming-gebaseerde afspeellijsten en nieuwe manieren om trends in populaire muziek te bestuderen. Toekomstig werk richt zich op het verminderen van de datahonger en het versnellen van training, maar zelfs in de huidige vorm wijst SCHADNet op een toekomst waarin muziekplatforms songteksten bijna zo zorgvuldig begrijpen als een aandachtige menselijke luisteraar.
Bronvermelding: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Trefwoorden: muzieksuggesties, liedjestekstanalyse, tekstclassificatie, deep learning, contentmoderatie