Clear Sky Science · nl
Verbetering van detectie van abonnementsfraude met ensemble learning: de casus Ethio Telecom
Waarom telefoonfraude iedereen aangaat
Elke keer dat we bellen, een sms sturen of mobiel internet gebruiken, vertrouwen we erop dat de rekening weerspiegelt wat we werkelijk hebben verbruikt. Criminelen kunnen echter telefonienetwerken misbruiken door lijnen te openen met valse identiteiten, enorme onbetaalde rekeningen op te bouwen en die lijnen zelfs voor andere misdrijven te gebruiken. Deze studie richt zich op Ethio Telecom, Ethiopië’s nationale aanbieder, en toont aan hoe geavanceerde, data‑gedreven methoden verdachte abonnementen veel nauwkeuriger kunnen opsporen dan traditionele middelen, en zo telefoonservices betaalbaar en veilig houden voor miljoenen gebruikers.
De verborgen kosten van valse telefoonaccounts
Abonnementsfraude doet zich voor wanneer iemand zich aanmeldt voor telefoniediensten met valse of gestolen gegevens en nooit de intentie heeft te betalen. Wereldwijd is dit een van de schadelijkste vormen van telecomfraude en kost het de sector jaarlijks tientallen miljarden dollars. Alleen voor Ethio Telecom wordt geschat dat fraude ongeveer een miljard dollar per jaar wegsluist, waarbij valse abonnementen verantwoordelijk zijn voor ongeveer 40% van dat verlies. Naast gemiste inkomsten kunnen deze lijnen worden ingezet voor oplichting, herverkoop van internationale gesprekken of andere illegale activiteiten, wat risico’s oplevert voor zowel klanten als de nationale veiligheid.
Van handgemaakte regels naar leren van data
Net als veel andere aanbieders vertrouwde Ethio Telecom traditioneel op experts die vaste regels opstelden om verdacht gedrag te signaleren—bijvoorbeeld het blokkeren van een lijn na te veel internationale oproepen in korte tijd. Deze regelgebaseerde systemen zijn makkelijk te begrijpen maar hebben moeite wanneer fraudeurs van tactiek veranderen of wanneer gebruikspatronen complex zijn. De auteurs bepleiten dat machine learning, die patronen rechtstreeks uit historische data leert, sneller en gevoeliger kan reageren. In plaats van te vertrouwen op één enkel model, verkennen ze "ensemble"-methoden die meerdere modellen combineren, en "adaptieve" methoden die blijven updaten naarmate nieuwe data binnenkomt.
Wat de onderzoekers uit echte oproeplogs bouwden
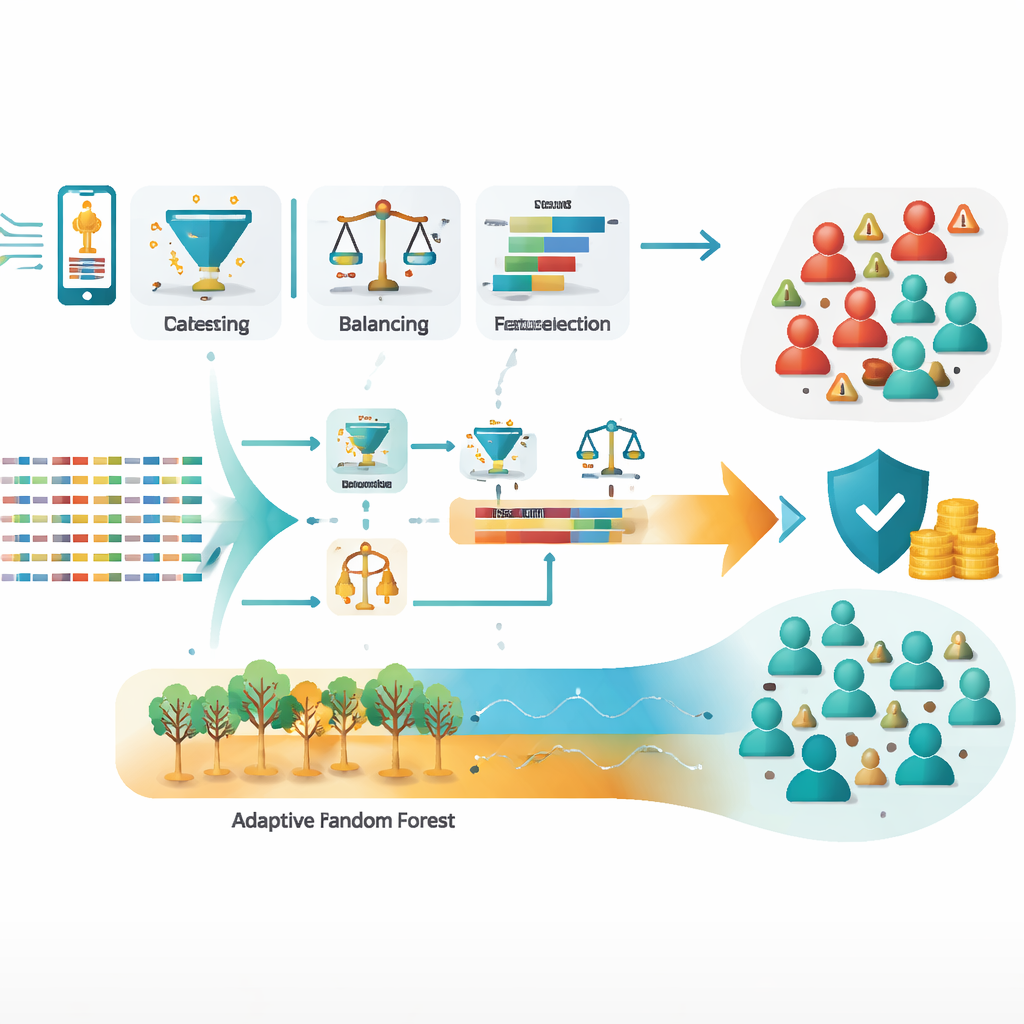
Het team werkte met een grote set call detail records—logboeken van wie wie belde, hoe lang en onder welke omstandigheden—uit een periode van twee maanden die bekendstond om intense fraudeactiviteit. Beginnend met ongeveer één miljoen ruwe records, maakten ze de data schoon, verwijderden fouten en duplicaten, brachten de sterk scheve klassen in evenwicht (veel meer eerlijke gebruikers dan fraudeurs) en creëerden nieuwe features die verdacht gedrag beter vastleggen. Vooral maten zoals hoeveel internationale nummers een abonnee belde, het aandeel internationale oproepen in het totaal en de verhouding van unieke nummers tot totale oproepen bleken belangrijk. Deze gedestilleerde signalen onderscheiden vaak normaal gebruik van georganiseerde misbruik veel beter dan simpele tellingen of demografische gegevens.
Hoe het combineren van modellen de detectie verbetert
De onderzoekers testten drie standaardmodellen—decision trees, logistieke regressie en artificiële neurale netwerken—naast verschillende ensemble‑strategieën zoals bagging (Random Forest), boosting (XGBoost), voting en stacking, plus adaptieve modellen ontworpen voor continue datastromen (Hoeffding Tree en Adaptive Random Forest). Na zorgvuldige afstemming van elk model behaalde de stacking‑benadering, die leert hoe de sterke punten van meerdere basismodellen te combineren, ongeveer 99,3% nauwkeurigheid op niet eerder geziene data. De Adaptive Random Forest was bijna net zo sterk, met ongeveer 99,2% nauwkeurigheid, en kon zich bovendien aanpassen naarmate fraudepatronen in de loop van de tijd verschuiven. Beide benaderingen reduceerden sterk de gevaarlijkste fout—het missen van daadwerkelijke fraude—in vergelijking met enkele modellen alleen.
Bijblijven met veranderende tactieken in real time
Aangezien fraudeurs hun methoden voortdurend aanpassen, kan een statisch model snel verouderen. Om dit aan te pakken gebruikten de auteurs een online feature‑selectietechniek die continu opnieuw evalueert welke signalen het meest relevant zijn, zonder het hele systeem van nul op te bouwen. Ze benadrukken ook het belang van privacy: alle persoonlijke identificerende gegevens in de dataset werden geanonimiseerd voordat de analyse plaatsvond, en ze adviseren strikte toegangscontrole en auditlogs. Voor praktische inzet schetst de studie een real‑time architectuur waarbij nieuwe oproeplogs via tools als Apache Kafka naar adaptieve modellen stromen die on‑the‑fly updaten terwijl ze monitoren op plotselinge gedragsveranderingen.
Wat dit betekent voor telefoongebruikers en aanbieders
Kort gezegd toont de studie aan dat het laten "meevoten" van meerdere intelligente modellen, en het toestaan dat ze continu leren, valse abonnementen met opmerkelijke nauwkeurigheid kan opsporen terwijl het aantal valse alarmen beheersbaar blijft. Voor Ethio Telecom kan dit zich vertalen in substantiële besparingen, stabielere tarieven en sterkere bescherming tegen crimineel misbruik van het netwerk. Voor klanten betekent het dat ongewoon maar legitiem gebruik minder snel ten onrechte als fraude wordt gezien, terwijl echt risicovolle lijnen sneller worden opgespoord en afgesloten. De auteurs concluderen dat ensemble‑ en adaptief leren, gebaseerd op zorgvuldig gekozen, contextspecifieke indicatoren, een krachtig en schaalbaar stappenplan bieden voor moderne detectie van telecomfraude.
Bronvermelding: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Trefwoorden: telecomfraude, abonnementsfraude, ensemble learning, adaptive random forest, call detail records