Clear Sky Science · nl
Evaluatie van prestaties van grote taalmodellen op Perzische reumatologieboardexamens: nauwkeurigheid en klinisch redeneren van GPT-4o versus GPT-5.1
Waarom dit belangrijk is voor artsen en patiënten
Kunstmatige intelligentie dringt snel door in medische colleges en klinieken, maar de meeste tests van deze hulpmiddelen richten zich op het Engels. Deze studie stelt een vraag die van belang is voor miljoenen Perzischsprekenden: hoe goed gaan geavanceerde AI-chatbots, specifiek GPT‑4o en GPT‑5.1, om met complexe reumatologie-examenvragen geschreven in het Perzisch? Het antwoord helpt onderwijsgevenden, trainees en patiënten te begrijpen waar deze hulpmiddelen veilig kunnen ondersteunen bij het leren en waar menselijke expertise onmisbaar blijft.
AI op de proef gesteld
De onderzoekers verzamelden 204 meerkeuzevragen uit de officiële Iraanse reumatologieboardexamens van 2023 en 2024, dezelfde examens die specialisten moeten halen om gecertificeerd te worden. Na het uitsluiten van zeven gebrekkige vragen bleven 197 items over. Elke vraag, inclusief eventuele bijbehorende afbeeldingen of grafieken, werd in het Perzisch ingevoerd in GPT‑4o en GPT‑5.1 in aparte, schone chats. De modellen werden gevraagd de beste antwoordoptie te kiezen en hun redenering uit te leggen, in navolging van hoe een trainee een AI-tool zou raadplegen tijdens het studeren.
Beoordeling van zowel antwoorden als redenering
De prestaties werden op twee manieren beoordeeld. Ten eerste werden de door de modellen gekozen opties vergeleken met het officiële antwoordmodel, wat een eenvoudige juist/onjuist nauwkeurigheidsmaat opleverde. Ten tweede beoordeelden zes boardgecertificeerde reumatologen onafhankelijk de kwaliteit van elke verklaring op een vijfpuntschaal, van duidelijk foutief redeneren tot volledig en klinisch verantwoord redeneren. De antwoorden van elk model werden door twee verschillende reumatologen beoordeeld die elkaars beoordelingen en het officiële antwoordmodel niet kenden. Dit stelde de onderzoekers in staat niet alleen te zien of de AI “het juiste antwoord gokte”, maar ook of de logica leek op de manier waarop specialisten denken.
Prestaties van het nieuwere model
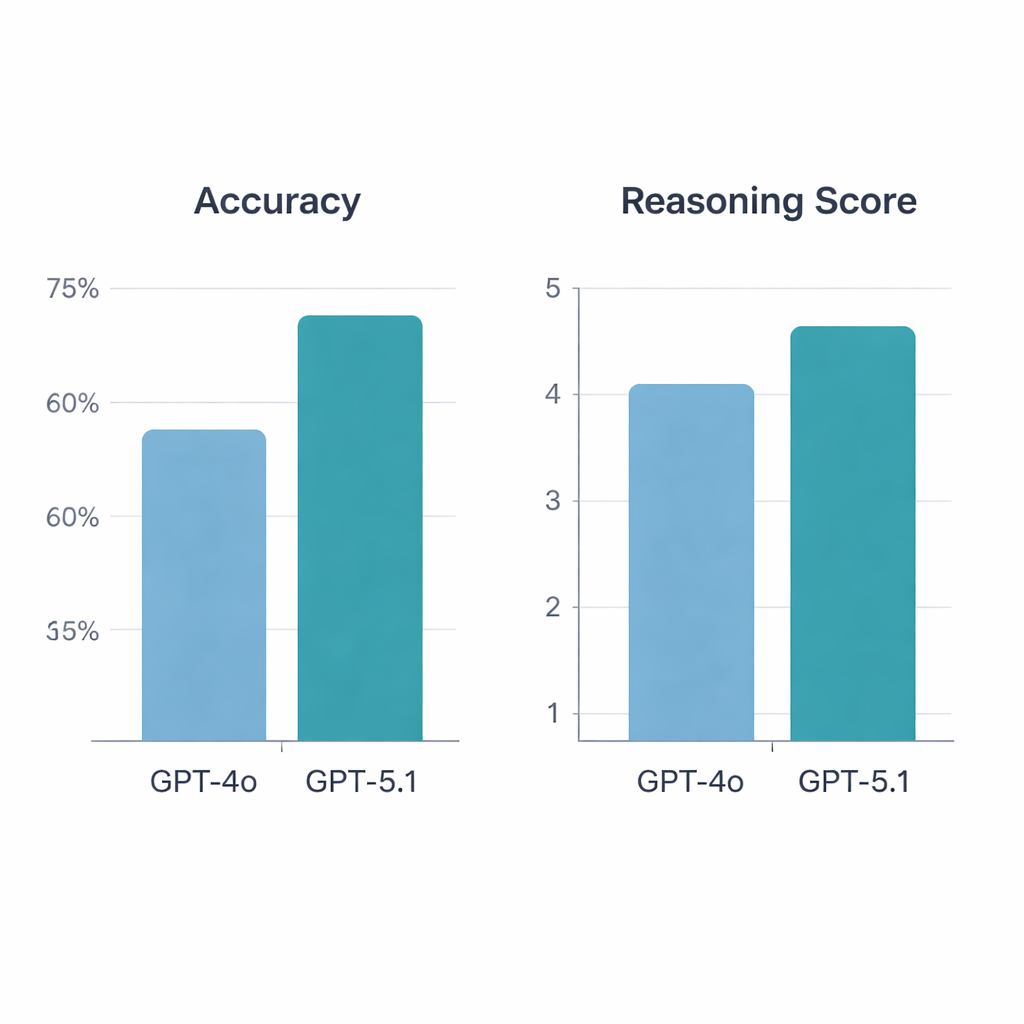
GPT‑5.1 presteerde duidelijk beter dan GPT‑4o. Van de 197 valide vragen beantwoorde GPT‑4o 64,5% correct, terwijl GPT‑5.1 76% nauwkeurigheid bereikte—een statistisch significante stijging. Beide modellen hadden 113 vragen goed en 34 fout, maar GPT‑5.1 loste daarnaast 36 vragen op die GPT‑4o miste; GPT‑4o was alleen juist op slechts 13 vragen. Toen reumatologen de verklaringen beoordeelden, kwam GPT‑5.1 opnieuw als beste uit de bus, met een gemiddelde redeneringsscore van 4,47 uit 5 vergeleken met 4,13 voor GPT‑4o, en het kreeg meer topwaarderingen. In tegenstelling tot GPT‑4o, waarvan de kwaliteit van de redenering varieerde afhankelijk van of een vraag ging over basale wetenschap, casusvignetten, diagnose of behandeling, behield GPT‑5.1 een gelijkmatigere prestatie over alle categorieën.
Sterktes, hiaten en menselijke meningsverschillen
De studie onthulde belangrijke nuances. Zelfs wanneer het eindantwoord van een model fout was, beoordeelden specialisten soms de redenering als tamelijk coherent, wat een kloof benadrukt tussen examencorrectie en denken in de klinische praktijk. Tegelijkertijd was de overeenstemming tussen de reumatologen matig, wat aangeeft dat clinici zelf van mening verschillen over wat telt als “goed redeneren.” Taal leek ook relevant: eerder onderzoek in het Engels en Spaans rapporteerde hogere scores voor vergelijkbare modellen, wat suggereert dat AI nog steeds beter presteert in grotere wereldtalen dan in het Perzisch. De auteurs benadrukken dat deze chatbots overtuigende verklaringen kunnen genereren die feitelijke fouten verbergen, en dat hun prestaties kunnen veranderen na updates van de systemen.
Wat dit betekent voor de toekomst
Voor het algemene publiek is de boodschap dat de nieuwste generatie AI-chatbots beter wordt in het behandelen van specialistische medische examens in het Perzisch, maar dat ze nog niet klaar zijn om gedegen opleiding of deskundig oordeel te vervangen. GPT‑5.1 kan een nuttige studiepartner zijn voor reumatologietrainees—het samenvatten van onderwerpen, het doorlopen van casussen en het bieden van gestructureerde uitleg—maar het mag niet als het definitieve woord worden vertrouwd voor beslissingen met grote gevolgen over diagnose of behandeling. De auteurs pleiten voor grotere, meertalige studies, herhaalde tests in de tijd en realistische klinische simulaties om vast te stellen hoe deze hulpmiddelen veilig geïntegreerd kunnen worden in medische opleidingen en, uiteindelijk, in de dagelijkse patiëntenzorg.
Bronvermelding: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Trefwoorden: reumatologie, Perzisch medische opleiding, grote taalmodellen, klinisch redeneren, boardexamens