Clear Sky Science · nl
Entropie-gestuurde multi-level feature-fusienetwerk voor hoog-precisie content-gebaseerde beeldopvraging
De juiste foto snel vinden
Dagelijks maken en bewaren we enorme aantallen foto’s — van medische scans en satellietbeelden tot beveiligingsbeelden en persoonlijke kiekjes. Deze afbeeldingen handmatig taggen en doorzoeken is traag en onbetrouwbaar. Dit artikel presenteert een slimmere manier voor computers om direct naar beelden te “kijken” en met hoge precisie de juiste afbeeldingen te vinden, zelfs in zeer grote en diverse collecties.
Waarom alleen naar pixels kijken niet genoeg is
Traditionele beeldzoektoepassingen vertrouwen vaak op bestandsnamen of eenvoudige labels zoals “kat” of “gebouw”. Mensen labelen afbeeldingen niet altijd zorgvuldig, en computers zien alleen ruwe pixels, niet de rijke betekenis die mensen eruit halen. Eerdere content-gebaseerde systemen probeerden deze kloof te dichten met eenvoudige visuele aanwijzingen zoals kleur, textuur en vorm. Die aanwijzingen hielpen, maar werden meestal gecombineerd met vaste belangrijkheidsniveaus. Dat betekent dat het systeem sommige kenmerken altijd belangrijker behandelde dan andere, ook als een specifieke zoekopdracht baat zou hebben bij een andere mix. Hierdoor nam de nauwkeurigheid af wanneer afbeeldingssoorten, belichting of scènes veranderden.
Verschillende manieren van zien combineren
De auteurs stellen een nieuw zoekkader voor dat twee hoofdsoorten visueel bewijs samenvoegt. Ten eerste gebruiken ze deep-learningmodellen — bekende netwerken zoals ResNet50 en VGG16 — die complexe patronen in beelden hebben geleerd te herkennen. Ten tweede voegen ze klassieke “handgemaakte” beschrijvingen toe die kleurverdelingen, randen en texturen op een meer gecontroleerde manier vastleggen. In plaats van van tevoren te raden hoeveel elk type kenmerk zou moeten wegen, laat het systeem de data beslissen. Het meet hoe informatief elk kenmerk is voor een gegeven zoekopdracht en past hun invloed dynamisch aan. Deze multi-level mix van hoog- en laag-niveau aanwijzingen helpt de computer een rijker, flexibeler begrip te vormen van wat er in een afbeelding staat.
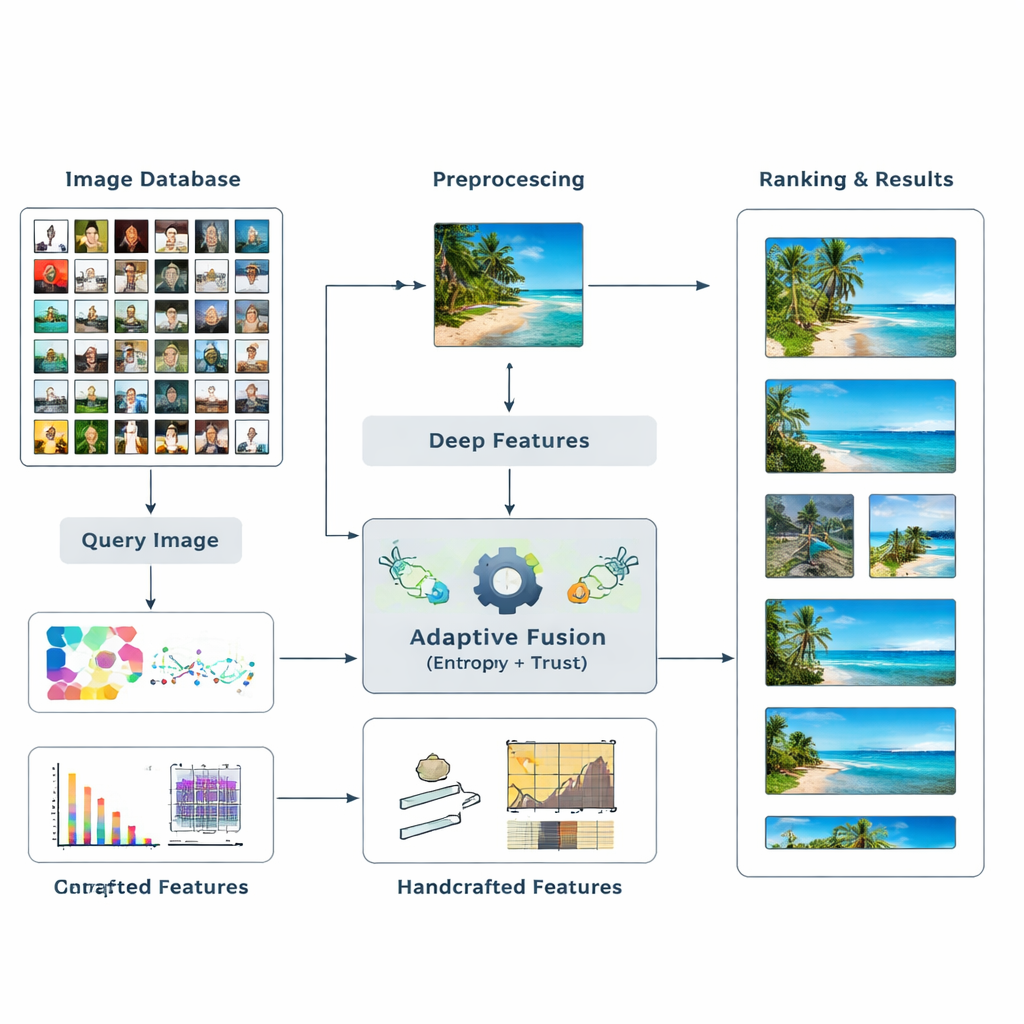
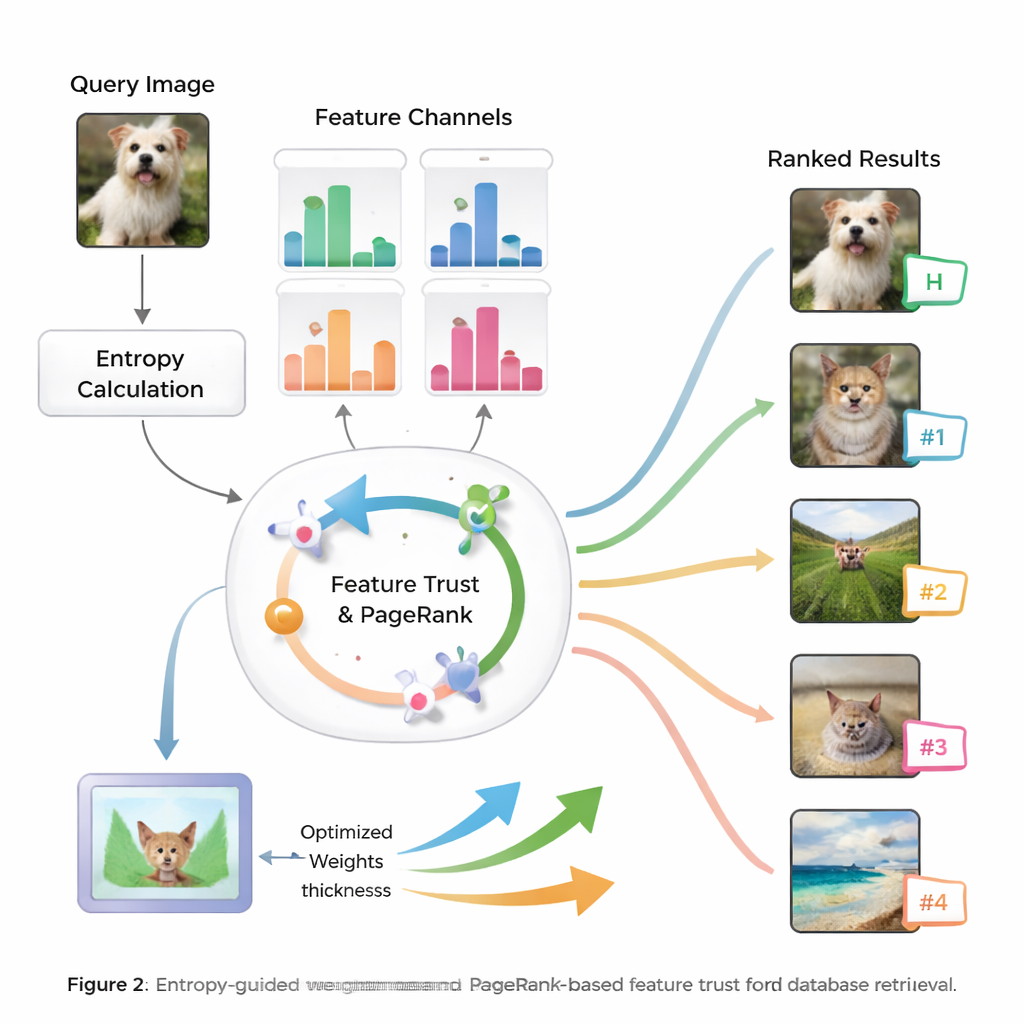
Informatie en vertrouwen bepalen de gewichten
De kern van de methode is het idee van entropie, een maat voor hoe onzeker of verspreid informatie is. Kenmerken die consequent relevante van irrelevante afbeeldingen scheiden hebben lagere entropie en worden als meer “discriminatief” behandeld. Voor een nieuwe query evalueert het systeem hoe elk kenmerk zich over de database gedraagt en kent het een initiële belangrijkheidsscore toe. Vervolgens onderzoekt het hoe betrouwbaar de zoekresultaten van elk kenmerk zijn — of de bovenste overeenkomsten echt op de query lijken — en bouwt zo een begrip van “vertrouwen” voor elk type aanwijzing op. Deze vertrouwensscores worden ingevoerd in een PageRank-achtige procedure, vergelijkbaar met hoe vroege websearch-engines bepaalden welke pagina’s het belangrijkst waren, om de featuregewichten te verfijnen via een probabilistisch overdrachtsnetwerk.
Van slimme gewichten naar betere rangschikking
Zodra het systeem heeft geleerd hoeveel vertrouwen het huidige query elk kenmerk moet krijgen, combineert het de gelijkenisscores tot één overall maat voor elke afbeelding in de database. Afbeeldingen worden vervolgens gerangschikt op basis van deze uitgebreide score, zodat diegene die op de meest betekenisvolle manieren overeenkomen met de query bovenaan komen te staan. De auteurs testen hun aanpak op veelgebruikte beeldbenchmarks en vergelijken deze met meerdere bestaande methoden. Ze rapporteren verbeteringen tot 8,6% in mean average precision en noemenswaardige verbeteringen in de kwaliteit van de top tien resultaten, zowel qua nauwkeurigheid als relevantie van de ordening. Statistische toetsen tonen aan dat deze verbeteringen waarschijnlijk niet door toeval komen, wat suggereert dat het systeem zowel nauwkeurig als stabiel is voor veel typen afbeeldingen.
Wat dit betekent voor alledaagse beeldzoektoepassingen
In eenvoudige woorden laat dit onderzoek zien hoe je beeldzoekmachines kunt maken die zich aanpassen aan elke vraag in plaats van te vertrouwen op rigide regels. Door informatie-inhoud en verdiend vertrouwen te laten bepalen welke visuele aanwijzingen het belangrijkst zijn, kan het systeem vaker de juiste beelden vinden — of het nu gaat om het opsporen van een vingerafdruk in een omvangrijke misdaaddatabase, het lokaliseren van een specifiek gebouw in satellietfoto’s, of het ophalen van de juiste medische scan. De auteurs erkennen dat de methode computationeel zwaarder is dan eenvoudigere systemen, maar betogen dat de hogere betrouwbaarheid en nauwkeurigheid het bijzonder geschikt maken voor grote, kritieke beeldrepositories waar het vinden van de juiste afbeelding echt telt.
Bronvermelding: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Trefwoorden: content-gebaseerde beeldopvraging, deep learning, featurefusie, beeldzoektocht, entropie-weging