Clear Sky Science · nl
ImageNet-voortraining en twee-staps transfer learning bij classificatie van chromosoomafbeeldingen
Helderder zicht op onze chromosomen
Onze chromosomen dragen de instructies voor het bouwen en laten functioneren van ons lichaam, en artsen bestuderen hun vormen om genetische aandoeningen en sommige vormen van kanker te ontdekken. Tegenwoordig kunnen computers helpen bij het lezen van chromosoomafbeeldingen, maar ze daar goed voor trainen is lastig omdat medische beelden schaars zijn en er heel anders uitzien dan alledaagse foto’s. Deze studie stelt een eenvoudige vraag met grote praktische gevolgen: kunnen computers beter leren van gerelateerde medische beelden, en niet alleen van enorme verzamelingen katten-, honden- en autofoto’s?
Waarom chromosoomfoto’s belangrijk zijn
In ziekenhuizen rangschikken specialisten iemands 46 chromosomen in een schema dat een karyotype wordt genoemd, verdeeld in 24 typen (22 genummerde paren plus X en Y). Subtiele donkere en lichte banden langs elk chromosoom helpen ontbrekende of extra stukken aan het licht te brengen die samenhangen met aandoeningen zoals het syndroom van Down of bepaalde leukemieën. Traditioneel classificeren experts deze banden met het blote oog, wat traag en subjectief is. Deep learning biedt een manier om dit werk te automatiseren, maar deze systemen starten doorgaans vanaf modellen die op ImageNet zijn getraind, een enorm dataset van alledaagse beelden. Die sprong—van vakantiefoto’s naar microscoopbeelden van chromosomen—is groot, en het is niet duidelijk hoe goed die ervaring echt overdraagbaar is.
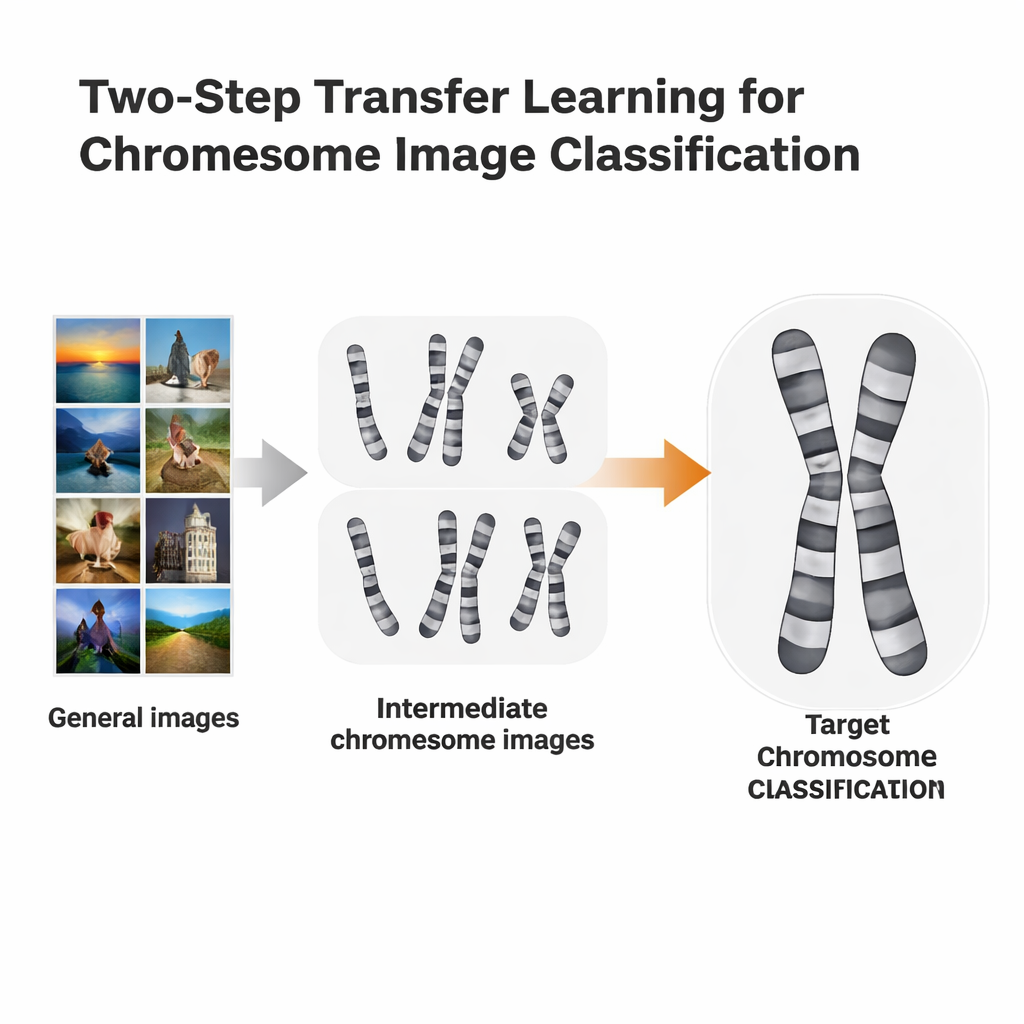
Een twee-staps leersnelkoppeling
De onderzoekers testten een meer op maat gemaakte trainingsroute die twee-staps transfer learning wordt genoemd. In plaats van direct van ImageNet naar een specifieke chromosoomtaak te gaan, fine-tuneden ze eerst ImageNet-getrainde modellen op chromosoomafbeeldingen afkomstig van één kleuringsmethode, en fine-tuneden daarna opnieuw op een tweede, iets verschillende methode. Ze gebruikten twee open datasets: Q-band afbeeldingen, die van lagere kwaliteit en moeilijker te lezen zijn, en G-band afbeeldingen, die schoner en gedetailleerder zijn. Elke dataset fungeerde om beurten als de “tussenstap” voor de andere. Het idee lijkt op het leren van talen: als je al Spaans spreekt, is het wellicht makkelijker om Italiaans te leren dan direct vanuit het Engels te beginnen.
Testen van veel computerlijke “ogen”
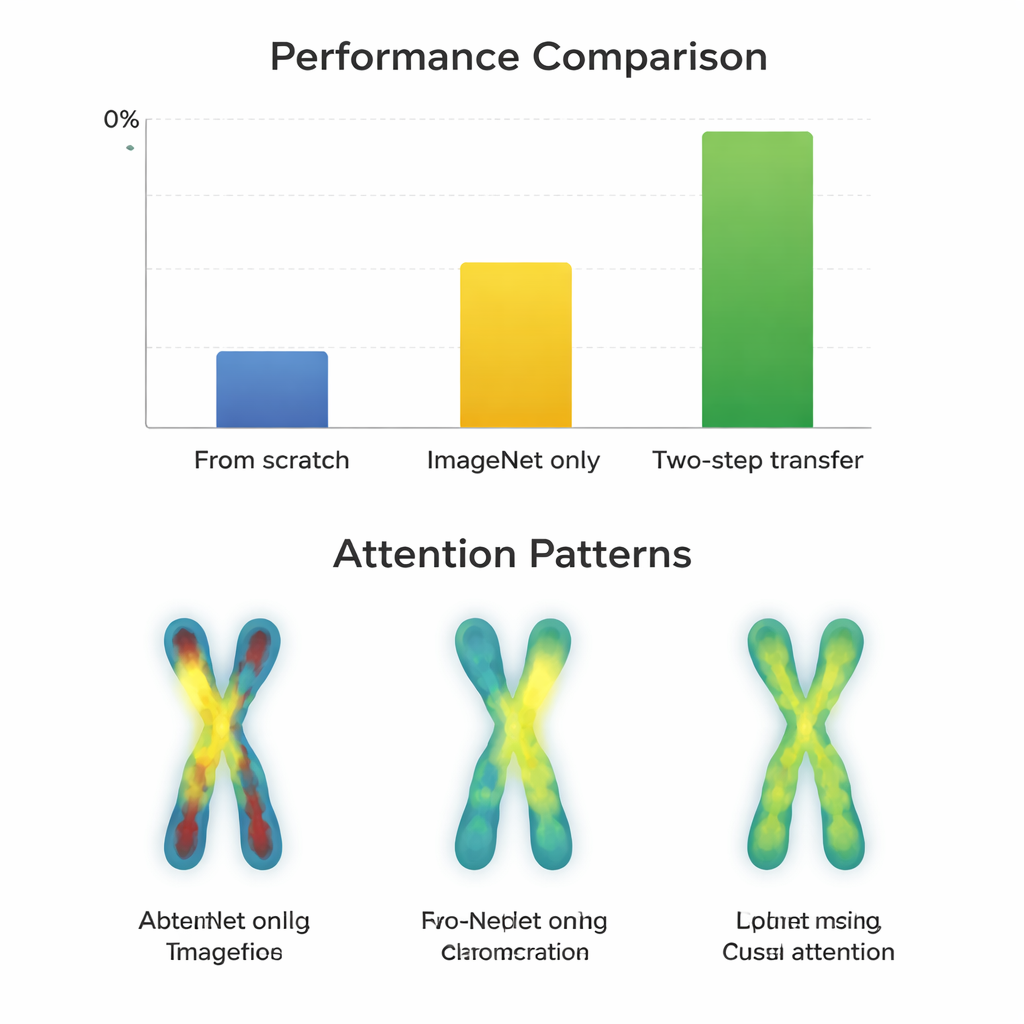
Om te zien wanneer deze extra stap helpt, trainde het team 66 verschillende classifiers, door 11 populaire neurale netwerkontwerpen te combineren met drie strategieën: vanaf nul trainen, fine-tunen vanaf ImageNet alleen en gebruik van twee-staps transfer. Ze maten de prestaties met Macro-F1, een score die alle chromosoomtypen eerlijk behandelt, inclusief de zeldzame. Eerst bevestigden ze dat Q-band en G-band afbeeldingen statistisch meer op elkaar lijken dan op ImageNet-foto’s, wat ze veelbelovende tussenstappen maakt. Daarna vergeleken ze hoe goed de verschillende modellen leerden onder elke strategie op zowel de makkelijke (G-band) als de moeilijke (Q-band) datasets.
Wanneer de extra stap rendeert
Bij de hogere kwaliteit G-band afbeeldingen presteerden bijna alle modellen al extreem goed na eenvoudige ImageNet-fine-tuning, met scores rond de 97–98 procent. Hier leverde de extra twee-staps training slechts kleine verbeteringen op—vaak minder dan één procentpunt—en soms had het zelfs een negatief effect bij oudere netwerkontwerpen. Daarentegen veranderde het verhaal bij de uitdagendere Q-band afbeeldingen. Moderne, compacte architecturen zoals ConvNeXt, Swin Transformer, Vision Transformer en MobileNetV3 profiteerden duidelijk van de twee-staps route, met verbeteringen van ongeveer 0,8 tot 3,3 procentpunt ten opzichte van alleen ImageNet. Visuele kaarten van waar de modellen “keken” laten zien waarom: met twee-staps transfer concentreerden de netwerken zich gelijkmatiger langs de chromosoombanden op beide armen, in plaats van alleen op contouren of één regio. Grote, oudere netwerken zoals VGG profiteerden echter niet en werden soms slechter, wat suggereert dat slimmer ontwerp groter kan verslaan.
Beperkingen die door de data zelf worden opgelegd
De onderzoekers onderzochten ook fouten op G-band afbeeldingen. Sommige mislukkingen waren niet toe te schrijven aan de leerstrategie maar aan gebrekkige input, zoals chromosomen die slecht waren bijgesneden bij het scheiden van overlappende vormen. In die gevallen hadden alle trainingsmethoden moeite, en waren de aandachtkaarten verspreid of gefixeerd op misleidende randen. Dit benadrukt een praktische boodschap voor klinieken en ontwikkelaars: zelfs de beste trainingspijplijn kan slechte beeldkwaliteit of voorbewerkingsfouten niet volledig compenseren, vooral bij relatief kleine datasets zoals die voor chromosoombeeldvorming.
Wat dit betekent voor diagnostiek in de praktijk
Voor niet-specialisten is de belangrijkste conclusie dat slim hergebruik van gerelateerde medische beelden geautomatiseerd chromosoomlezen kan verbeteren—vooral wanneer de doeldata ruisig of schaars zijn en wanneer moderne, zorgvuldig ontworpen neurale netwerken worden gebruikt. Voor beelden van hoge kwaliteit is standaard ImageNet-gebaseerde training mogelijk al voldoende. Maar wanneer pathologen met moeilijkere datasets werken, kan een extra leerstap met een nauw verwant type afbeelding het computeroog aanscherpen en de prestaties in het bereik van 93–98 procent brengen. Deze aanpak kan verder reiken dan chromosomen naar veel gebieden van medische beeldvorming waar gelabelde data beperkt zijn, en zo betrouwbare AI-hulpmiddelen dichter bij de dagelijkse klinische praktijk brengen.
Bronvermelding: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Trefwoorden: chromosoomclassificatie, medische beeldvorming AI, transfer learning, deep learning-modellen, karyotypering