Clear Sky Science · nl
Verbetering van de voorspelling van einddragende capaciteit van in rots ingeknelde palen met gaussian‑verrijkte, geoptimaliseerde Extreme Gradient Boosting‑modellen
Bouwen op rots in plaats van giswerk
Wanneer ingenieurs bruggen en wolkenkrabbers ontwerpen, vertrouwen ze vaak op diepe funderingen die doorlopen tot in vaste rots. De sterkte van deze "in rots ingeknelde palen" is cruciaal voor veiligheid en kostenefficiëntie, maar de werkelijke draagkracht bij de punt is moeilijk direct te meten. Deze studie laat zien hoe moderne machine‑learning‑tools, gecombineerd met slimme technieken om data te genereren, ingenieurs veel scherpere schattingen kunnen geven van hoeveel belasting deze diepe funderingen veilig kunnen dragen — wat mogelijk bouwkosten kan besparen terwijl structuren veilig blijven.
Waarom diepe funderingen zo moeilijk te beoordelen zijn
In rots ingeknelde palen zijn grote betonnen kolommen die door zwakkere grond worden geboord en in sterkere rots verankerd. In theorie geldt: hoe harder de rots en hoe beter de uitvoering, hoe meer gewicht een paal bij de tip kan ondersteunen. In de praktijk is het rommelig: modder en boorslib kunnen zich op de bodem ophopen, de ruwheid en vorm van de socket variëren, en verborgen holtes of scheuren in de rots zijn moeilijk te detecteren. Vanwege deze onzekerheden nemen ontwerpers vaak het zekere voor het onzekere en gaan ze uit van weinig of geen steun van de paalpunt, wat leidt tot langere en duurdere funderingen dan wellicht nodig is.
Van eenvoudige formules naar slimmere voorspellingen
Vroegere methoden om paalcapaciteit te schatten leunden op vereenvoudigde vergelijkingen of traditionele rekenmodellen. Die richten zich meestal op een handvol eigenschappen — zoals de druksterkte van de rots — en behandelen de rotmassa op een geïdealiseerde manier. In de afgelopen jaren zijn onderzoekers begonnen met het toepassen van kunstmatige‑intelligentie technieken om direct te leren van databases met belastingsproeven, waarbij palen zijn belast tot hun gedrag goed vastligt. Deze benaderingen kunnen veel invoervariabelen tegelijk verwerken, waaronder paaldiameter, dieptes in grond en rots en maatstaven voor rotskwaliteit, maar ze zijn ook vaak 'black boxes' die kunnen overfitten wanneer gegevens schaars zijn.
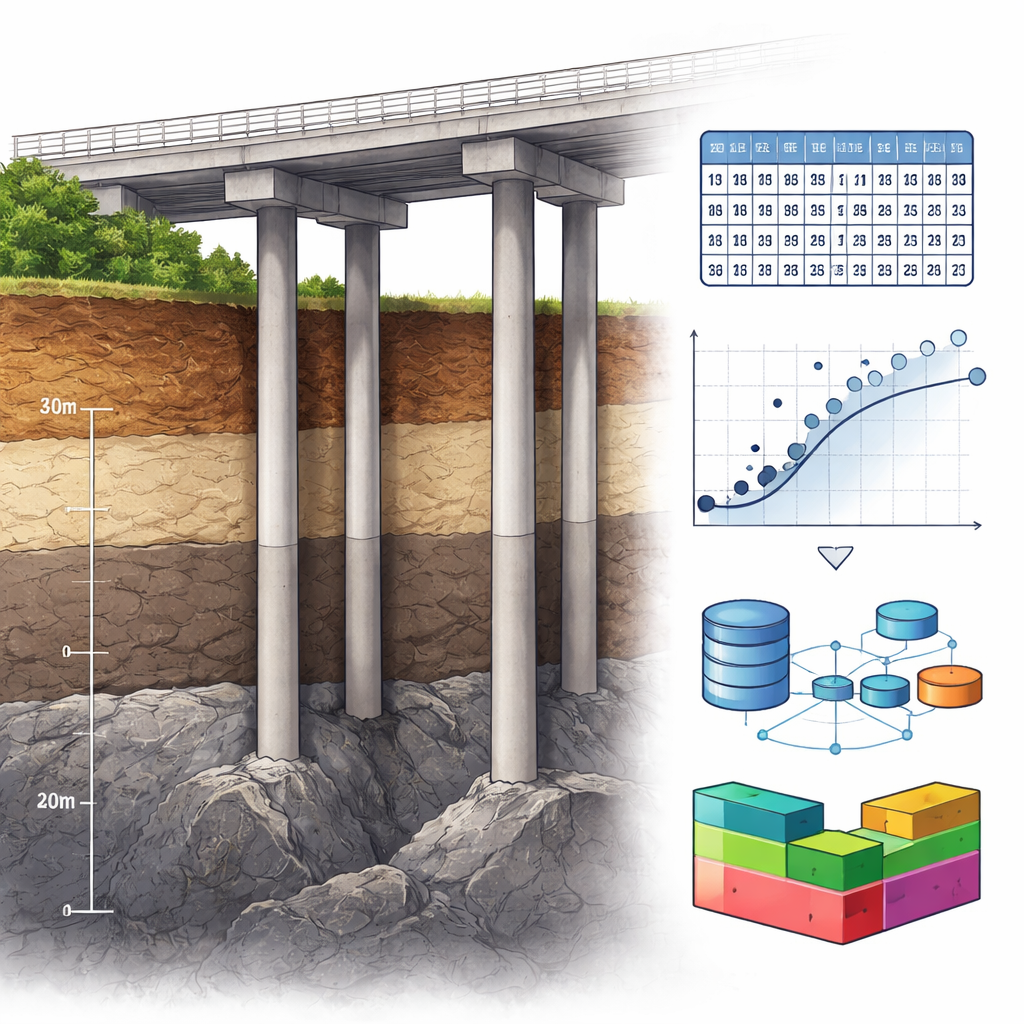
Het algoritme voeden met echte en synthetische data
De auteurs bouwden voort op een gepubliceerde set van 151 proeven met in rots ingeknelde palen die de einddragingsfactor (een maat voor hoeveel belasting de punt kan dragen) registreerden samen met acht beschrijvende kenmerken. Na zorgvuldige opschoning van de data om uitschieters en hiaten te verwijderen, hielden ze 136 echte palen over. Om het kleine aantal voorbeelden — een veelvoorkomend probleem in de geotechniek — te overwinnen, creëerden ze vervolgens extra "synthetische" data door milde, willekeurige Gaussische ruis toe te voegen aan de bestaande records. Dat leverde een grotere, statistisch consistente set van 460 palen op die de originele patronen behielden terwijl meer variatie werd geboden voor het trainen van machine‑learning‑modellen.
Het trainen en afstemmen van de leermachines
Het team richtte zich op een algoritme genaamd Extreme Gradient Boosting, of XGBoost, dat vele eenvoudige beslisboommodellen combineert tot een krachtig voorspellend model. Om de beste prestaties uit XGBoost te halen, koppelden ze het aan drie door de natuur geïnspireerde optimalisatieschema’s gebaseerd op rekentechnieken, brainstormgedrag en walvisjachtstrategieën. Deze optimizers stelden automatisch sleutelparameters af — zoals boomdiepte en leersnelheid — om een balans te vinden tussen het passen op bekende data en het vermijden van overfitting. Onder de varianten bleek het met de Arithmetic Optimization Algorithm afgestemde XGBoost‑model (XGBoost_AOA) het nauwkeurigst en het meest stabiel.
Wat de modellen leerden over rots en palen
Al met alleen de oorspronkelijke 136 palen presteerde het geoptimaliseerde model beter dan eerdere methoden. Toen het werd getraind op de uitgebreide set van 460 palen, verbeterde de nauwkeurigheid sterk: de voorspellingsfouten krompen tot een fractie van hun vroegere grootte en de overeenkomst tussen voorspelde en waargenomen capaciteiten kwam dicht bij een ideale één‑tot‑één lijn. De analyse toonde ook welke invoer het meest van belang was. De druksterkte van de rots en een rotsmassa‑beoordeling waren de dominante voorspellers, terwijl paaldiameter en het totale belastingniveau ook sterke bijdragen leverden. Maten die nauw met elkaar samenhangen, zoals twee verschillende rotskwaliteitsscores, bleken sterk redundant te zijn, wat aantoont hoe overlappende informatie overfitting kan bevorderen als dit niet zorgvuldig wordt aangepakt.
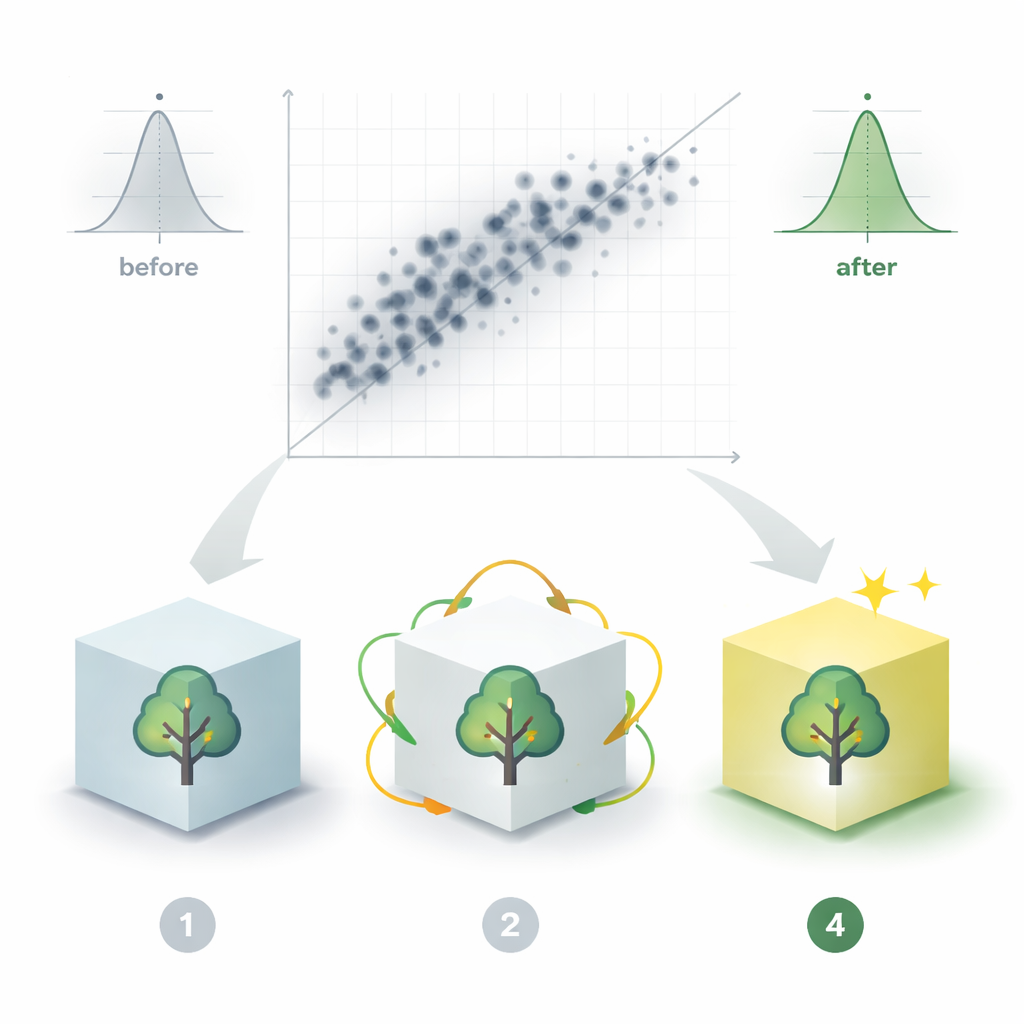
Van onderzoekssoftware naar praktisch hulpmiddel
Om de resultaten buiten het laboratorium bruikbaar te maken, verpakten de auteurs hun best presterende model in een gebruiksvriendelijke computerinterface. Ingenieurs kunnen basisparameters van paal en rots invoeren en onmiddellijk een schatting van de puntcapaciteit ontvangen, samen met bewijs dat het model is geverifieerd aan de hand van onafhankelijke casusgeschiedenissen. Hoewel de aanpak nog steeds afhankelijk is van de kwaliteit en reikwijdte van de onderliggende data, laat het zien hoe het combineren van machine learning, synthetische datageneratie en interpreteerbaarheidsinstrumenten verspreide testresultaten kan omzetten in een praktisch ontwerphulpmiddel — wat helpt om giswerk te verminderen, onnodige conservatisme te beperken en veiliger, economischere funderingen te ontwerpen.
Bronvermelding: Khatti, J., Fissha, Y. & Cheepurupalli, N. Improving end-bearing capacity prediction of rock-socketed shafts using Gaussian-augmented optimized extreme gradient boosting models. Sci Rep 16, 7664 (2026). https://doi.org/10.1038/s41598-026-38646-w
Trefwoorden: in rots ingeknelde palen, diepe funderingen, machine learning, data‑augmentatie, geotechnische techniek