Clear Sky Science · nl
FedSCOPE: Gefedereerde cross-domain sequentiële aanbeveling met gedecoupleerd contrastief leren en privacy-behoudende semantische verrijking
Waarom slimere, veiligere aanbevelingen ertoe doen
Elke keer dat je films bekijkt, online winkelt of recensies leest, bepalen aanbevelingssystemen stilletjes wat je vervolgens te zien krijgt. Naarmate ons digitale leven zich over steeds meer apps en websites verspreidt, zouden die systemen veel beter kunnen worden als ze van al je activiteiten tegelijk kunnen leren—zonder ooit je privégegevens bloot te geven. Dit artikel introduceert FedSCOPE, een nieuwe manier waarop verschillende platforms kunnen samenwerken aan aanbevelingen die zowel nauwkeuriger als respectvoller tegenover de privacy van gebruikers zijn.
Het probleem met de huidige aanbevelingsmotoren
De meeste huidige aanbevelingssystemen bevinden zich binnen één app of website en zien slechts een beperkt deel van je gedrag. Dat betekent dat ze moeite hebben met ‘cold-start’-gebruikers die weinig geschiedenis hebben, of met nicheproducten waar maar weinig mensen mee interacteren. Wanneer bedrijven proberen gegevens over domeinen heen te combineren—zoals boeken en films, of eten en keukengerei—lopen ze tegen drie grote problemen aan: data is vaak schaars, verschillende platforms hebben zeer uiteenlopende typen gebruikers en activiteiten, en strikte privacyregels maken het riskant om ruwe data op één plek te verzamelen. Eenvoudige oplossingen, zoals voor iedereen dezelfde hoeveelheid privacy-preserverende ruis toevoegen, verzwakken meestal ofwel de bescherming of schaden sterk de nauwkeurigheid.
Laat taalmodellen de gaten vullen
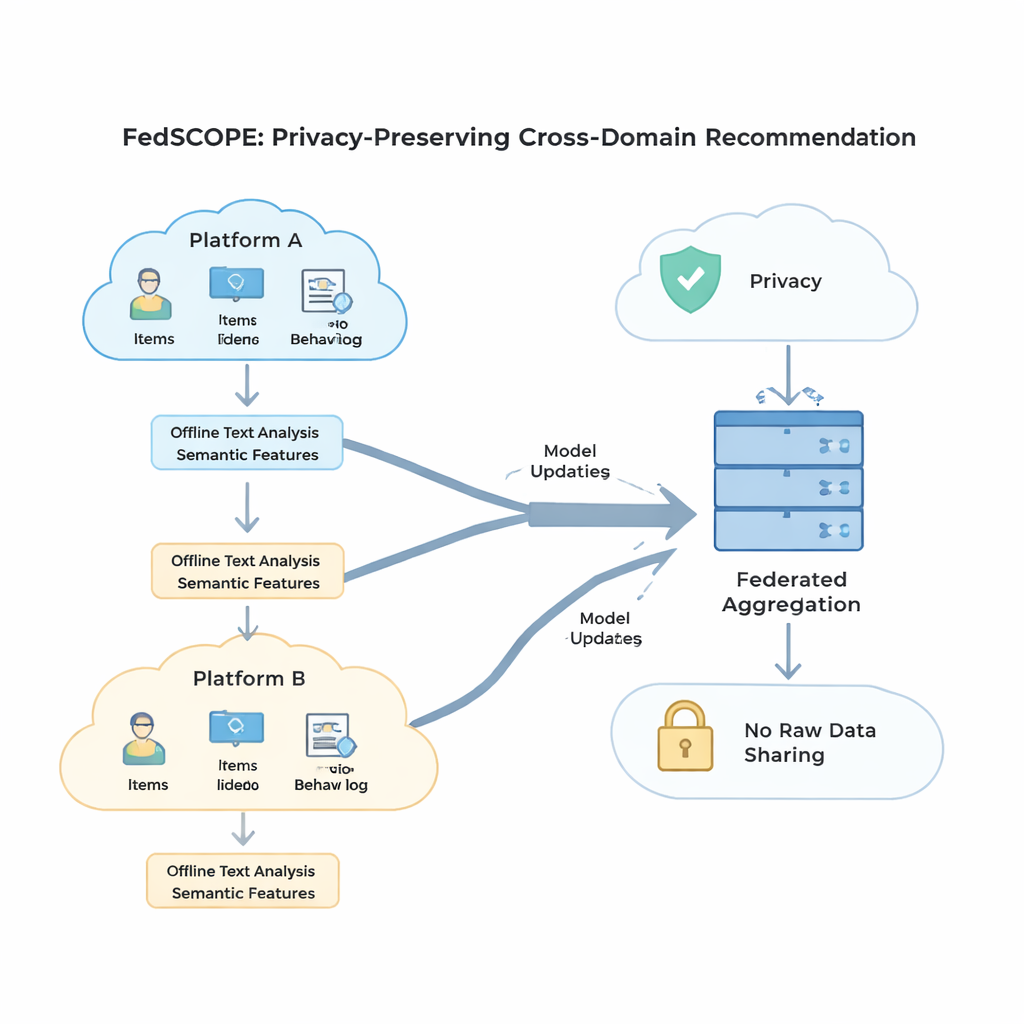
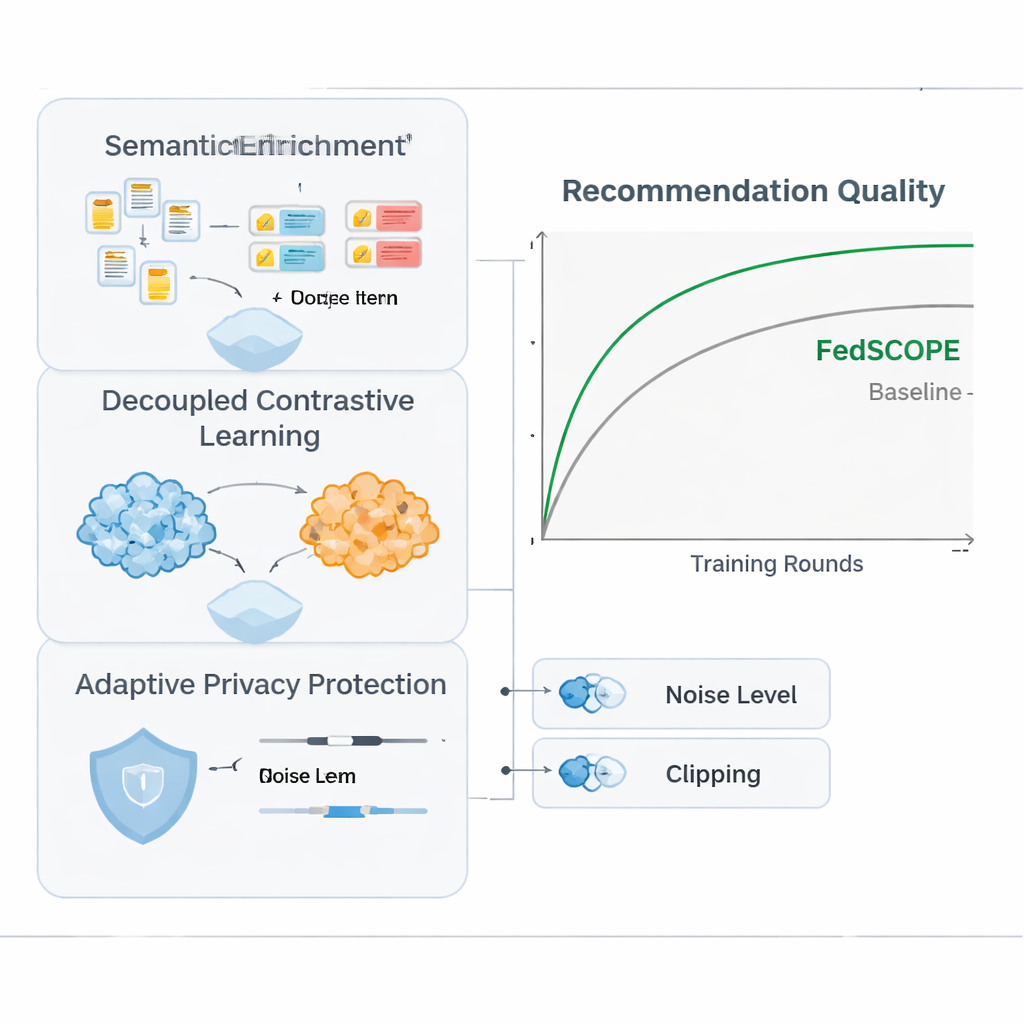
FedSCOPE pakt het sparsity-probleem aan door elk platform zijn data te laten verrijken met een groot taalmodel (LLM), maar op een ongewone, privacybewuste manier. In plaats van gebruikersgeschiedenissen bij elke aanbeveling naar een externe AI-service te sturen, voert elke client een eenmalig offline proces uit: titels en basisinformatie over items (bijvoorbeeld de naam en het genre van een film) worden aan een LLM gevoerd en gevraagd om gestructureerde beschrijvingen, zoals waarschijnlijke thema’s, kijkgewoonten of gerelateerde interessegebieden. Deze gegenereerde attributen blijven op het lokale apparaat of de server en worden samengevoegd met de gebruikelijke klik- en kijkgeschiedenissen met behulp van een lichtgewicht neuraal netwerk. Dit geeft het systeem een rijker beeld van zowel gebruikers als items, wat vooral nuttig is wanneer er maar een paar geregistreerde interacties zijn. Omdat het proces offline en lokaal plaatsvindt, verlaat gedrag in ruwe vorm nooit het platform en is er geen voortdurende afhankelijkheid van externe AI-diensten.
Persoonlijke informatie scheiden van gedeelde informatie
Om gebruik te maken van gedrag uit meerdere domeinen zonder signalen op een schadelijke manier te vermengen, introduceert FedSCOPE een trainingsstrategie genaamd gedecoupleerd contrastief leren. Eenvoudig gezegd leert het systeem twee dingen tegelijk. Ten eerste, binnen elk domein—bijvoorbeeld alleen de filmzijde—trekt het gebruikers die zich vergelijkbaar gedragen dichter naar elkaar en duwt het degenen die dat niet doen uit elkaar, waardoor het gevoel voor persoonlijke smaak binnen die omgeving wordt aangescherpt. Ten tweede, over domeinen heen, brengt het representaties van dezelfde gebruiker op één lijn terwijl verschillende gebruikers distinct blijven, zodat wat je kijkt kan helpen voorspellen wat je zou kunnen lezen of kopen, zonder je met anderen te vervagen. Door deze ‘binnen-domein’ en ‘over-domein’ doelen apart te behandelen, voorkomt de methode een veelvoorkomend euvel waarbij het forceren van alles in één gedeelde mal fijnmazige voorkeuren vernietigt.
Privacy beschermen zonder bruikbaarheid weg te gooien
Sterke wiskundige privacy, bekend als differentiële privacy, betekent meestal het toevoegen van willekeurige ruis aan modelupdates voordat die met een centrale server worden gedeeld. Veel eerdere systemen gebruikten dezelfde privacy-instellingen voor elke deelnemer, wat slecht aansluit wanneer sommige clients miljoenen gebruikers hebben en andere slechts een paar duizend. FedSCOPE geeft in plaats daarvan elke client een gepersonaliseerd privacybudget en past aan hoeveel het zijn updates afknijpt en verstoort op basis van de omvang van de data en eerdere gedragingen. Grote, data-rijke platforms kunnen preciezere informatie bijdragen zonder overmatig te worden vervuild met ruis, terwijl kleinere platforms steviger worden afgeschermd. Alle updates worden vervolgens gecombineerd met behulp van secure aggregation, zodat de server nooit een individuele bijdrage in klare tekst te zien krijgt.
Wat de experimenten in de praktijk aantonen
De auteurs testten FedSCOPE op real-world winkeldata van Amazon, waarbij ze domeinen koppelden zoals Films met Boeken en Eten met Keuken. Ze vergeleken het met een reeks moderne aanbevelingsmethoden, waaronder andere privacy-behoudende en cross-domain benaderingen. Over meerdere nauwkeurigheidsmaatstaven scoorde FedSCOPE consequent aan de top of in de buurt daarvan. Het convergeerde sneller tijdens training, werkte beter voor gebruikers met zeer weinig eerdere interacties en hield goed stand wanneer het aantal deelnemende clients of de fractie die elke ronde werd bemonsterd, veranderde. Belangrijk is dat, wanneer het team de privacybeperkingen verscherpte, FedSCOPE’s adaptieve strategie de prestaties veel hoger hield dan systemen die een one-size-fits-all differentiële privacy toepasten.
Wat dit betekent voor dagelijkse gebruikers
Voor de leek wijst FedSCOPE op een toekomst waarin je favoriete apps kunnen samenwerken om je smaak dieper te begrijpen zonder ooit je ruwe data samen te voegen. Door schaars bijgehouden geschiedenissen te verrijken met inzichten uit taalmodellen, zorgvuldig te scheiden wat domeinspecifiek is van wat gedeeld wordt, en privacy-instellingen per deelnemer af te stemmen, levert het kader aanbevelingen die zowel relevanter als respectvoller met persoonlijke informatie omgaan. In praktische termen kan dat betere suggesties betekenen voor wat je next moet kijken, lezen of kopen—zonder dat je je digitale privacy hoeft op te geven.
Bronvermelding: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Trefwoorden: gefedereerde aanbeveling, privacy-behoudende AI, cross-domain personalisatie, grote taalmodellen, differentiële privacy