Clear Sky Science · nl
Onderzoek naar docent‑leerlinginteractie met multimodale grote taalmodellen: een empirisch onderzoek
Waarom het bekijken van klaslokalen met AI ertoe doet
Wie ooit in een klaslokaal heeft gezeten, weet dat de manier waarop docenten en leerlingen met elkaar omgaan het verschil kan maken tussen verveling en echt leren. Toch is het verrassend lastig om deze moment‑tot‑momentuitwisselingen te bestuderen: waarnemers worden moe, menselijke beoordelingen verschillen, en videomateriaal wordt snel overweldigend. Dit artikel onderzoekt hoe een nieuw soort kunstmatige intelligentie—multimodale grote taalmodellen die ‘naar’ beelden kunnen kijken en tekst kunnen ‘lezen’—onderzoekers en scholen kan helpen complexe klaspraktijken sneller en objectiever te doorgronden.
Het omzetten van echte lessen in onderzoeksdata
De onderzoekers begonnen met gewone klasvideo’s uit Chinese basis- en middelbare scholen, openbaar beschikbaar op een nationaal onderwijsplatform. Uit 30 lessen haalden ze bijna 2.400 stilstaande beelden die sleutelmomenten van lesgeven en leren vastlegden. Elk beeld werd gelabeld volgens vijf gemakkelijk te begrijpen interactiepatronen: begeleidend (docent legt uit), samenwerkend (leerlingen werken samen), vragend (vragen stellen en beantwoorden), zelfstandig (leerlingen werken alleen) en presenterend (leerlingen presenteren aan de klas). Experts in onderwijstechnologie hielpen deze categorieën te verfijnen zodat ze overeenkwamen met waar ervaren waarnemers in echte klaslokalen op letten.
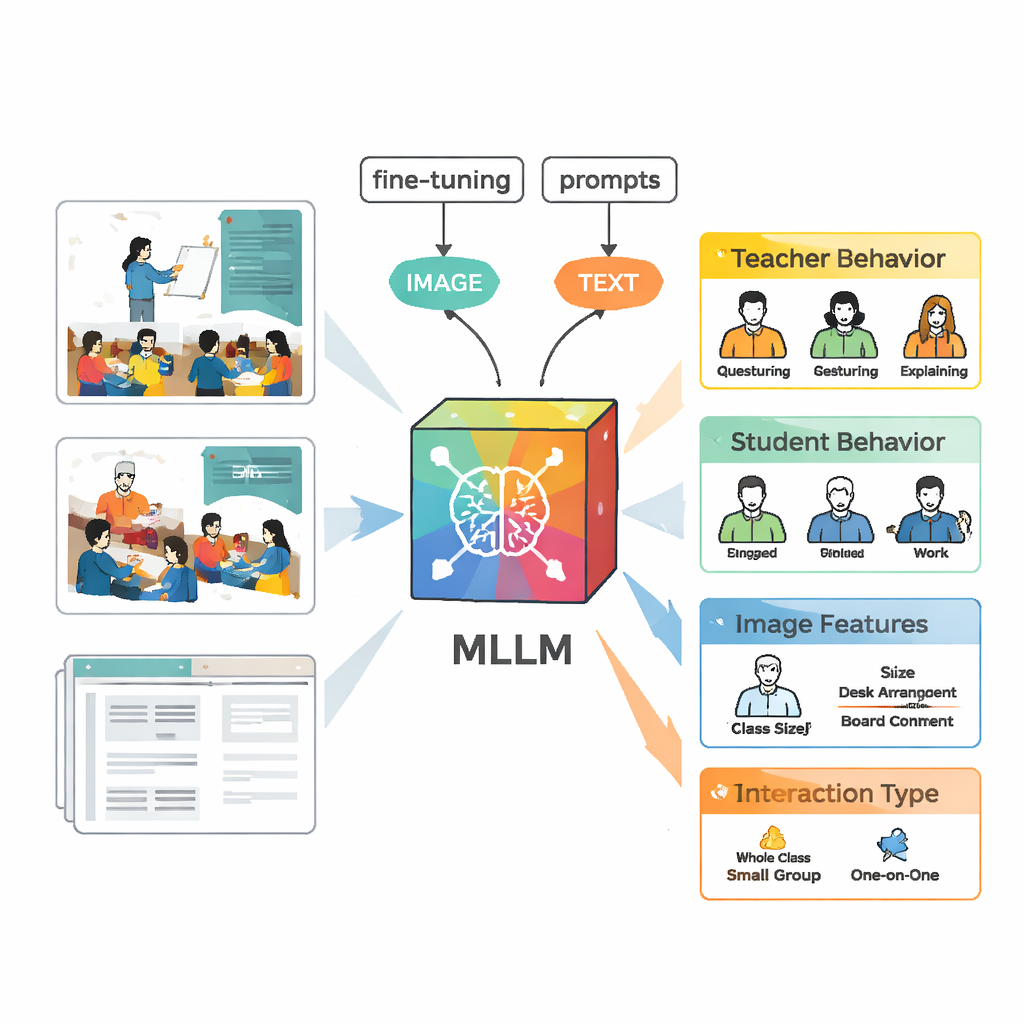
Een AI leren klasdynamiek te zien
Om deze taferelen te analyseren, gebruikte het team een multimodaal groot taalmodel genaamd VisualGLM‑6B, dat zowel beelden als tekst als invoer kan verwerken. Omdat het oorspronkelijke model breed en niet specifiek op klaslokalen was getraind, hebben de onderzoekers het ‘fijngetuned’ met hun gelabelde beelden. Ze pasten een techniek toe die LoRA heet en slechts een klein aantal interne parameters van het model aanpast, waardoor het trainen efficiënter maar nog steeds krachtig is. Ze ontwerpten ook zorgvuldige prompts—gestructureerde instructies die het model vertellen docentgedrag, leerlinggedrag, visuele kenmerken en het type interactie in een consistent formaat te beschrijven—zodat de uitvoer makkelijker met menselijke experts te vergelijken zou zijn.
Betere labels bouwen met mensen en machines
Het creëren van een hoogwaardige trainingsset vereiste meer dan het simpelweg aanwijzen van het model naar video’s. Eerst produceerde VisualGLM basisbeschrijvingen van elk beeld. Menselijke annotators corrigeerden vervolgens fouten en vulden ontbrekende context aan, zoals wie er sprak of of leerlingen luisterden of discussieerden. Daarna voerden ze deze uitgewerkte beschrijvingen in ChatGPT, dat onder leiding van aangepaste prompts gestructureerde analyses genereerde volgens de vijf interactiecategorieën. Experts herzien en bewerkten deze door AI gegenereerde analyses opnieuw. Het eindresultaat was een rijke dataset waarin elk beeld een gedetailleerd, betrouwbaar verslag droeg van wat docenten en leerlingen deden.
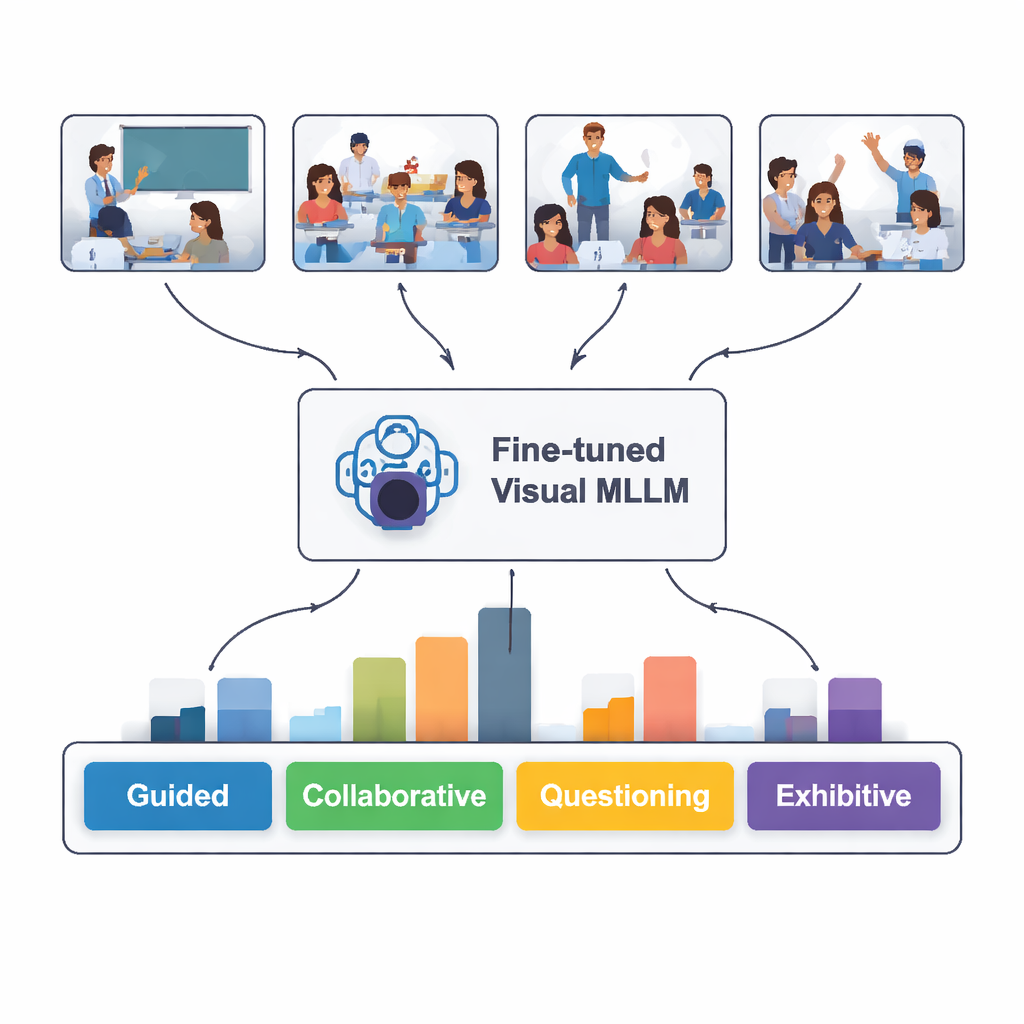
Hoe goed ‘las’ de AI het klaslokaal?
Getest op 100 nieuwe klasbeelden die het nog nooit had gezien, identificeerde het fijngetunede model het interactietype correct in 82 procent van de gevallen. Het presteerde het best bij het herkennen van begeleidende, zelfstandige en presenterende situaties—wanneer de docent duidelijk uitlegt, leerlingen rustig zelfstandig werken, of een leerling vooraan presenteert. Het had meer moeite met samenwerkend werk en vragende situaties, waar lichaamstaal en zitopstelling zelfs voor mensen ambigu kunnen zijn. Een diepere tekstgebaseerde vergelijking liet zien dat de door het model geschreven beschrijvingen vaak sterk overeenkwamen met expertanalyses, hoewel het af en toe details ‘hallucineerde’ die niet in de afbeeldingen voorkwamen of een subtiele gebaar verkeerd interpreteerde.
Wat dit betekent voor toekomstige klaslokalen
Voor de niet‑specialistische lezer is de kernboodschap dat AI‑systemen steeds beter in staat zijn klaslokalen te observeren en samen te vatten hoe lesgeven en leren zich ontvouwen, met een mate van structuur en consistentie die voor mensen lastig te handhaven is over duizenden scènes. Hoewel niet perfect—vooral bij subtiele vormen van discussie en vragen stellen—laat de aanpak zien dat multimodale grote taalmodellen nu al onderwijsresearch en uiteindelijk feedbacktools voor de klas kunnen ondersteunen. Naarmate deze modellen ook geluid, gebaren en grotere, gevarieerdere datasets gaan omvatten, kunnen ze docenten helpen patronen in hun praktijk te zien die eerder verborgen waren, en zo een nieuw perspectief bieden op hoe alledaagse interacties het leren van leerlingen vormen.
Bronvermelding: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Trefwoorden: docent‑leerlinginteractie, klaslokaalanalyse, multimodale AI, onderwijstechnologie, grote taalmodellen