Clear Sky Science · nl
Intelligente incrementele classificatie met een dynamisch sprinkhaan-geoptimaliseerd neuraal netwerk voor datastromen
Waarom continu veranderende data ertoe doet
Van elektriciteitsnetten en fabrieken tot online betalingen: moderne systemen produceren iedere seconde data. Verborgen in deze continue datastromen zitten vroege waarschuwingen voor uitrustingsfalen, cyberaanvallen of op handen zijnde prijsstijgingen. De uitdaging is dat deze informatiestroom nooit stopt en dat het gedrag in de loop van de tijd blijft veranderen. Het hier samengevatte artikel introduceert een nieuwe manier om neurale netwerken te trainen zodat ze kunnen blijven leren van dergelijke live data zonder te vertragen of nauwkeurigheid te verliezen, waardoor ze nuttiger worden voor monitoring en besluitvorming in de praktijk.
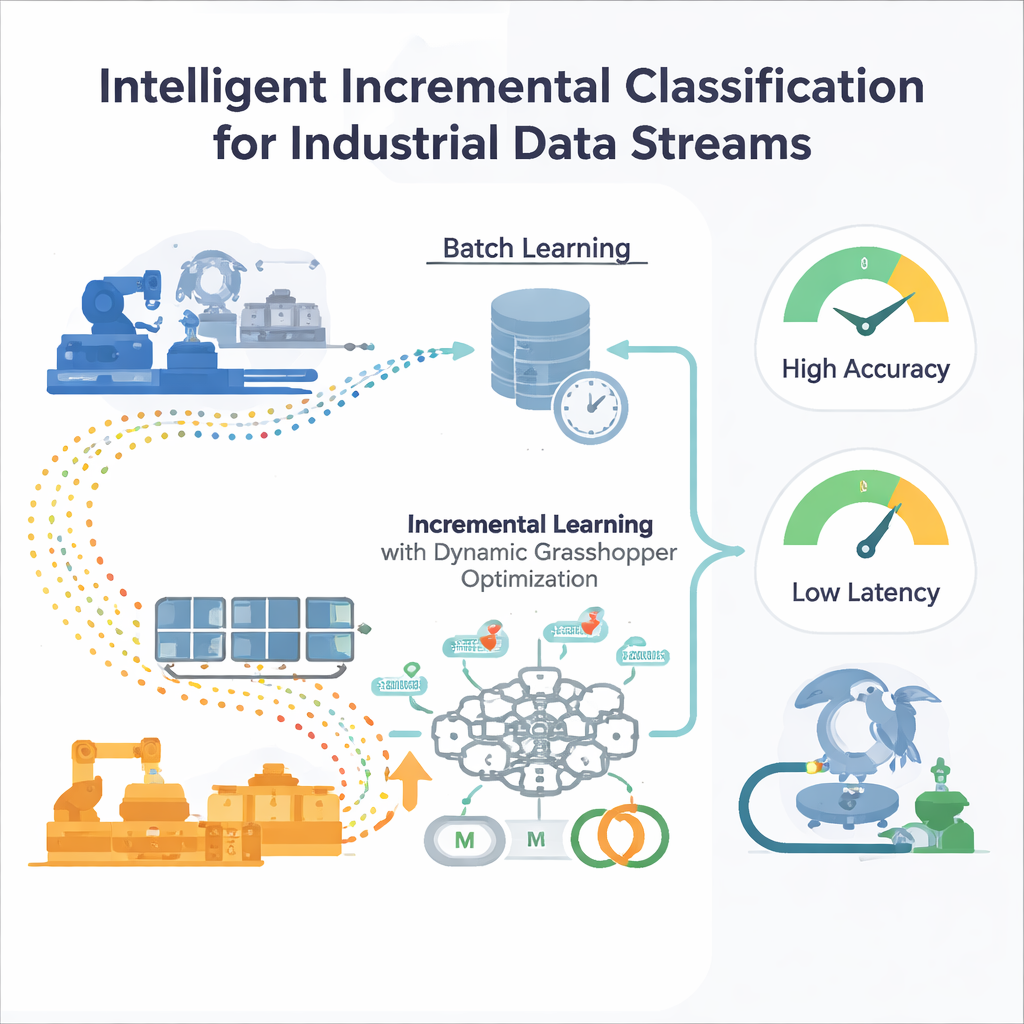
De beperkingen van eenmalig trainen
De meeste traditionele machine-learningmodellen worden in "batches" getraind: engineers verzamelen een grote historische dataset, stemmen het model af en zetten het vervolgens in productie. Dat werkt als de wereld globaal gezien gelijk blijft. Maar in industriële omgevingen verschuiven de omstandigheden—vraagpatronen veranderen, sensoren slijten, markten fluctueren. Een model dat in de tijd bevroren is, wordt geleidelijk blind voor nieuwe patronen, en het steeds opnieuw vanaf nul hertrainen op steeds grotere datasets is duur en traag. Standaard automatische afstemmingsmethoden zoals grid search of evolutionaire algoritmen veronderstellen ook vaste data, wat betekent dat ze opnieuw moeten worden gestart wanneer de datadistributie verandert—onpraktisch voor systemen die continu moeten draaien.
Een neuraal netwerk dat on the fly leert
De auteurs stellen een incrementeel leerkader voor rond een multilayer perceptron (MLP), een veelgebruikt type neuraal netwerk. In plaats van het netwerk alle historische data in één keer te geven, wordt de binnenkomende datastroom opgedeeld in hanteerbare vensters. Elk nieuw venster vormt een kleine trainingsstap die de interne gewichten van het netwerk bijwerkt en daarna wordt weggegooid—een "train-and-forget"-strategie die het geheugenverbruik laag houdt. Cruciaal is dat het systeem niet afhankelijk is van vaste trainingsinstellingen. Twee belangrijke regelaars die het leerproces beheersen—de leersnelheid (hoe groot elke update is) en momentum (hoe vloeiend updates verlopen)—worden continu aangepast naarmate de stroom evolueert, zodat het model responsief kan blijven zonder onstabiel te worden.
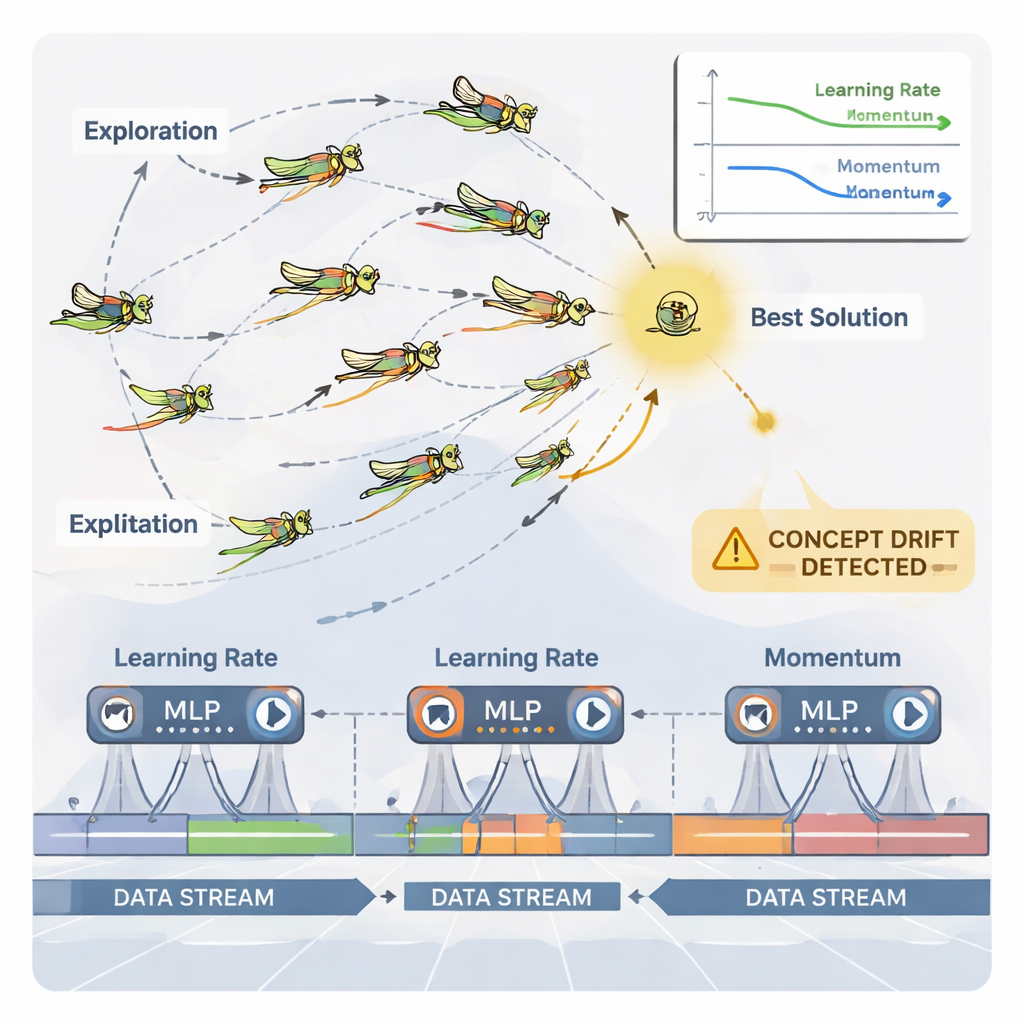
Sprinkhanen als slimme parameterafstemmers
Om deze continue aanpassing te verzorgen gebruiken de auteurs een door de natuur geïnspireerde optimizer genaamd Dynamic Grasshopper Optimization Algorithm (DGOA). Stel je een zwerm virtuele sprinkhanen voor die mogelijke combinaties van leersnelheid en momentum verkennen. In het begin zwerft de zwerm breed om goede regio’s te vinden; later vernauwen de bewegingen zich om veelbelovende keuzes te verfijnen. In deze dynamische variant veranderen stapgrootte en aantrekkingskracht richting de beste oplossing in de loop van de tijd, gebaseerd op hoe goed het neurale netwerk presteert. Het systeem houdt ook toezicht op "concept drift"—plotselinge veranderingen in voorspellingsfouten of in de data zelf. Wanneer een drift wordt gedetecteerd, worden sommige sprinkhanen gereset en worden hun stappen tijdelijk groter, waardoor de optimizer snel nieuwe gebieden kan doorzoeken en verouderde instellingen kan ontvluchten.
De methode in de praktijk getest
De onderzoekers evalueerden hun aanpak op een echte dataset van de elektriciteitsmarkt in Australië, waarbij het doel was te voorspellen of prijzen omhoog of omlaag zouden gaan. Vergeleken met gangbare afstemmingsmethoden zoals grid search, random search, particle swarm optimization, genetische algoritmen, ant colony optimization en het standaard sprinkhaan-algoritme, behaalde de dynamische variant gecombineerd met incrementeel leren de hoogste nauwkeurigheid (ongeveer 89,5%) terwijl er minder rekentijd en minder iteraties nodig waren. Aanvullende experimenten toonden aan dat de methode zich beter aanpast aan zowel stabiele als veranderende datastromen, schaalt van duizenden tot miljarden voorbeelden terwijl het geheugen beperkt blijft, en concurrentieel presteert op taken zoals voorspellend onderhoud, anomaliedetectie en fraudedetectie, evenals op standaard wiskundige optimalisatiebenchmarks.
Wat dit in de praktijk betekent
Voor niet-experts is de conclusie dat dit werk een manier biedt om neurale netwerken "levend" en goed afgesteld te houden in omgevingen waar data nooit stopt en omstandigheden voortdurend verschuiven. In plaats van het systeem herhaaldelijk stil te zetten om modellen vanaf nul te herbouwen, laat het voorgestelde kader een lichtgewicht netwerk venster voor venster zichzelf bijwerken, terwijl een zwermgebaseerde optimizer continu bijstuurt hoe snel en hoe vloeiend het leert. Het resultaat is snellere aanpassing aan nieuwe patronen, betere lange-termijnnauwkeurigheid en efficiënter gebruik van rekenmiddelen—sleutelelementen voor betrouwbare, realtime besluitvorming in sectoren als energie, productie en financiën.
Bronvermelding: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Trefwoorden: datastromen, incrementeel leren, neurale netwerken, hyperparameteroptimalisatie, zwermintelligentie