Clear Sky Science · nl
Een uitlegbaar hybride CNN–transformermodel voor gebarentaalherkenning op randapparaten met adaptieve fusie en kennisdistillatie
Waarom compacte gereedschappen voor gebarentaal ertoe doen
Miljarden dagelijkse gesprekken steunen meer op handbewegingen, gezichtsuitdrukkingen en lichaamstaal dan op gesproken woorden. Toch kunnen de meeste telefoons, tablets en openbare apparaten nog steeds geen gebarentalen begrijpen, zeker buiten Engelssprekende landen. Dit artikel introduceert TinyMSLR, een compact en uitlegbaar systeem voor gebarentaalherkenning dat in realtime op kleine, energiezuinige apparaten kan draaien. Het doel is gewone hardware om te vormen tot betaalbare, betrouwbare communicatiemiddelen voor dove en slechthorende mensen wereldwijd.
Meer talen aan het gesprek toevoegen
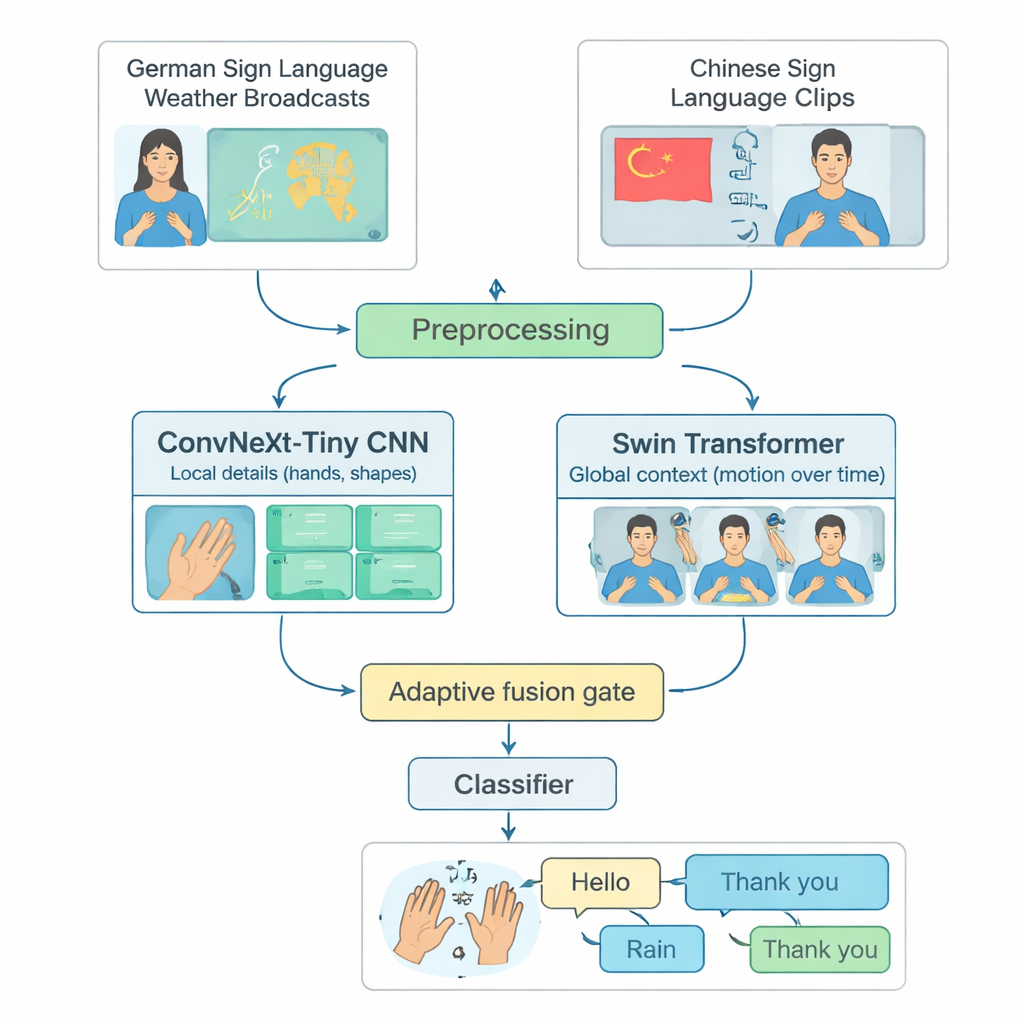
Veel geavanceerde systemen voor gebarentaalherkenning richten zich op één enkele taal, meestal American Sign Language, en draaien alleen op krachtige computers. Daardoor blijven mensen die andere gebarentalen gebruiken of in regio’s met beperkte rekenmiddelen wonen, buiten beschouwing. De auteurs pakken deze kloof aan door een gedeelde testset te bouwen uit twee verschillende talen: weeruitzendingen in Duitse Gebarentaal en een grote collectie Chinese Gebarentaal. Ze selecteren zorgvuldig 20 veelvoorkomende alledaagse gebaren — zoals Hallo, Weer, Regen, Blij, Ja en Dank je — die in beide talen voorkomen. Door lange video’s te verkorten tot korte clips met precies één gebaar en het aantal voorbeelden per klasse en per tekenaar te balanceren, creëren ze een eerlijke, reproduceerbare manier om te beoordelen hoe goed een model geïsoleerde gebaren over talen heen kan herkennen.
Hoe het hybride model handen en beweging ziet
TinyMSLR combineert twee complementaire manieren om naar video te kijken. De ene tak gebruikt een moderne convolutionele netwerkarchitectuur (ConvNeXt‑Tiny) die uitblinkt in het herkennen van fijne details, zoals vingerhoudingen en subtiele texturen. De tweede tak gebruikt een Swin Transformer, een nieuwere modelfamilie die goed is in het volgen van patronen over ruimte en tijd — hoe handen, gezicht en bovenlichaam zich over meerdere frames bewegen. Elke korte videoclip wordt gestandaardiseerd naar 32 frames van 224×224 pixels, licht geaugmenteerd (bijvoorbeeld kleine rotaties of helderheidsaanpassingen) en vervolgens parallel aan beide takken gevoerd. Elke tak produceert een samenvatting van 768 getallen; samen vangen deze twee samenvattingen zowel scherpe lokale details als bredere beweging en context.
Het model laten beslissen wat het belangrijkst is
Aangezien sommige gebaren vooral door handvorm worden onderscheiden terwijl andere afhankelijk zijn van bredere armbewegingen of gezichtskenmerken, legt TinyMSLR niet één vaste manier op om de twee gezichtspunten te combineren. In plaats daarvan gebruikt het een kleine “fusiepoort” die voor elke invoerclip leert hoeveel vertrouwen te geven aan de detailgerichte tak versus de contextgerichte tak. De poort kijkt naar beide featuresamenvattingen en geeft twee gewichten terug die altijd optellen tot één; de uiteindelijke representatie is een gewogen mengsel van de twee. Tijdens training krijgt elke tak ook zijn eigen kleine classifier zodat hij zelfstandig nuttig leert te zijn, en een paar grotere “teacher”-netwerken (één CNN, één Transformer) sturen het kleine model subtiel bij door niet alleen het juiste label te tonen maar ook welke alternatieve labels erop lijken. Deze techniek, kennisdistillatie genoemd, helpt het compacte systeem de nauwkeurigheid van zwaardere modellen te benaderen terwijl formaat en snelheid geschikt blijven voor randapparaten.
Zien waarom het systeem elke beslissing neemt
Buiten ruwe nauwkeurigheid benadrukken de auteurs dat gebruikers en ontwikkelaars moeten kunnen nagaan waarop het model zijn aandacht richt. Ze passen SHAP toe, een familie gereedschappen die aan elk deel van de invoer een belangrijkheidswaarde toekent. In de praktijk berekenen ze deze verklaringen op tussentijdse features en projecteren ze terug op frames als warmtekaarten en temporele plots. Dit onthult bijvoorbeeld welke frames en regio’s de beslissing sturen tussen visueel vergelijkbare gebaren zoals Regen en Sneeuw of Koud en Slecht. Het aggregeren van veel verklaringen toont bredere patronen: niet‑manuele signalen zoals gezichtsuitdrukking en hoofdbeweging, evenals polsoriëntatie en handvorm, blijken bijzonder invloedrijk. Deze inzichten helpen verifiëren dat het systeem zich baseert op betekenisvolle aspecten van het gebaren in plaats van op achtergrondartefacten.

Snelheid, zuinigheid en ruimte voor groei
Op de tweetalige benchmark met 20 gebaren bereikt TinyMSLR ongeveer 99% training- en validatienauwkeurigheid en een F1‑score rond 99%, terwijl het minder dan 2,7 miljoen parameters en circa 1,9 miljard operaties per clip gebruikt. Op een moderne GPU verwerkt het een gebaar in ongeveer 13,5 milliseconden en verbruikt het minder dan 30 millijoule energie; het opgeslagen model is slechts ongeveer 7,2 megabyte groot. Deze cijfers suggereren dat realtime gebarentaalherkenning op het apparaat haalbaar is op goedkope bordjes en ingebedde systemen. De auteurs wijzen er zorgvuldig op dat hun werk alleen korte, geïsoleerde gebaren en twee talen bestrijkt, en gezichtsuitdrukkingen impliciet behandelt in plaats van als een afzonderlijk signaal. Het uitbreiden van de aanpak naar rijkere woordenschatten, continue zinnen, meer talen en expliciete modellering van gezichts- en hoofdbewegingen blijft toekomstig werk. Toch biedt TinyMSLR een overtuigend bewijs van concept: nauwkeurige, efficiënte en interpreteerbare hulpmiddelen voor het begrijpen van gebarentalen hoeven niet beperkt te zijn tot de cloud — ze kunnen rechtstreeks op alledaagse apparaten draaien.
Bronvermelding: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Trefwoorden: gebarentaalherkenning, tiny machine learning, edge-AI, uitlegbare AI, meertalige modellen