Clear Sky Science · nl
SAT: shift alignment transformer voor videoruisonderdrukking zonder stromingsschatting
Scherpere video’s uit ruisrijke scènes
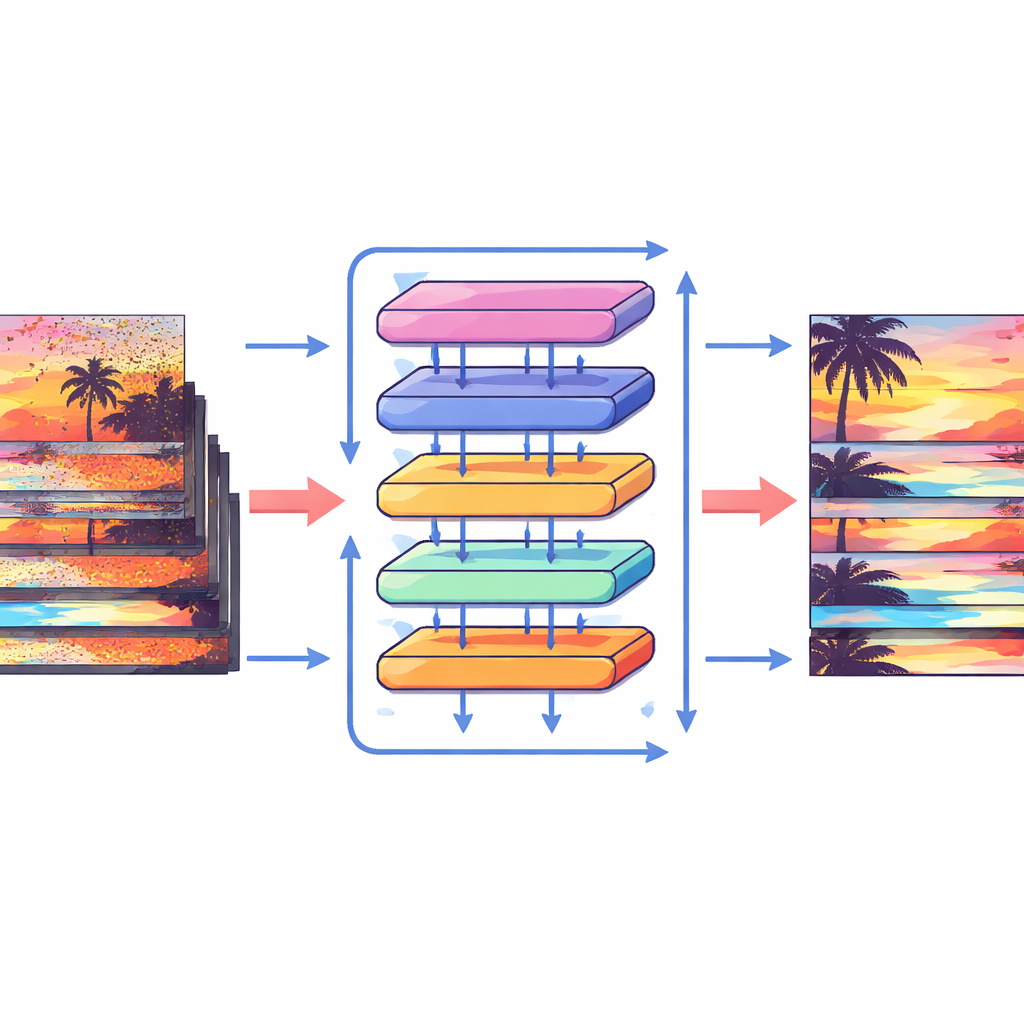
Wie ooit binnenshuis ’s nachts heeft gefilmd of met een telefoon bij weinig licht, kent het resultaat: korrelige, flikkerende beelden waarin details lijken te kruipen en kleuren onnatuurlijk ogen. Dit artikel presenteert een nieuwe methode om zulke video’s te reinigen en om te zetten in duidelijkere, stabielere sequenties zonder te leunen op de zware bewegingsvolgsoftware die daarvoor meestal nodig is. De methode, Shift Alignment Transformer genoemd, is ontworpen om fijne details te behouden en toch efficiënt genoeg te zijn voor praktisch gebruik.
Waarom video reinigen zo moeilijk is
Ruis uit één foto verwijderen is al een uitdaging; voor video is het nog ingewikkelder. Enerzijds wordt elk frame aangetast door willekeurige korreltjes en kleurverschuivingen. Anderzijds zijn de frames in de tijd met elkaar verbonden: objecten bewegen, de camera trilt en details verschijnen en verdwijnen. Traditionele methoden voor videoruisonderdrukking vertrouwen vaak op het schatten van beweging tussen frames, veelal via optical flow, die probeert te volgen waar elke pixel van het ene naar het andere frame beweegt. Hoewel krachtig, vallen zulke bewegingsschattingen snel uiteen wanneer de video extreem ruisig is of de beweging snel en complex is, en ze brengen bovendien een grote rekenbelasting met zich mee die systemen aanzienlijk kan vertragen.
Een nieuwe manier om uit te lijnen zonder tracking
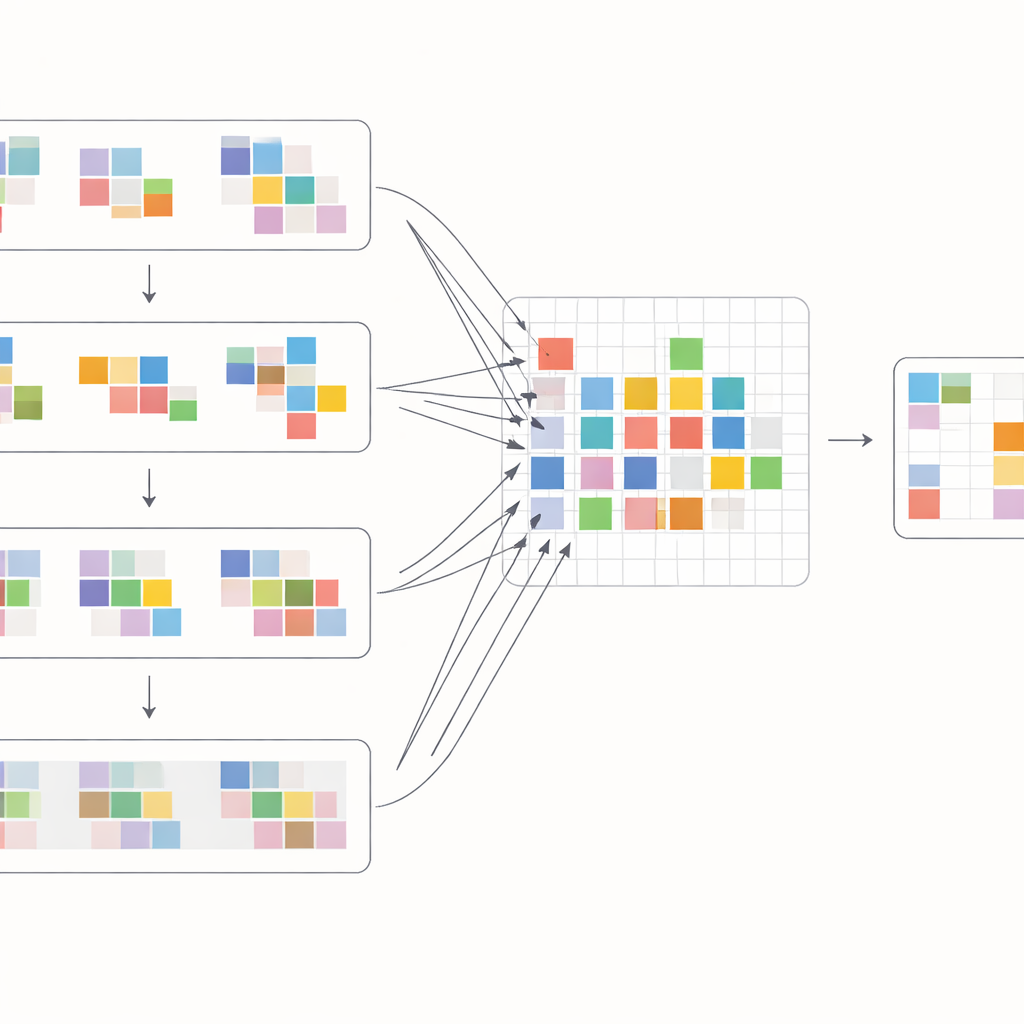
In plaats van expliciet iedere pixel te volgen, kiest de Shift Alignment Transformer (SAT) een andere aanpak: het laat het netwerk impliciet ontdekken hoe frames samenhangen door kenmerken zorgvuldig te verschuiven en te vergelijken. Het model is gebouwd rond een moderne architectuur bekend als Transformer, die uitblinkt in het vinden van langeafstandrelaties in data. Binnen dit kader introduceren de auteurs een Spatial-Temporal Shift Module die informatie zachtjes verspreidt over tijd en ruimte. In de tijd verschuift het model framekenmerken cyclisch zodat, laag voor laag, elk frame verder in het verleden en de toekomst kan “kijken”. In de ruimte splitst het kenmerken in veel kleine groepen en duwt elke groep in verschillende richtingen. Deze combinatie bootst effectief na hoe objecten over het beeld kunnen bewegen, zodat het netwerk informatie uit verschillende frames kan uitlijnen zonder ooit een expliciet bewegingsveld te berekenen.
Hoe de nieuwe bouwstenen werken
Om het meeste uit deze verschuivingen te halen, ontwerpen de auteurs een speciaal attention-blok dat informatie binnen en tussen frames mengt. Eerst worden de verschoven kenmerken uit naburige frames bijeengebracht en vergeleken via een cross-attention operatie: het model leert welke regio’s in andere frames het beste het huidige frame ondersteunen op elke locatie. Tegelijkertijd richt een afzonderlijke attention-operatie zich op relaties binnen elk afzonderlijk frame en versterkt zo lokale structuur en textuur. Deze twee stromen worden vervolgens samengevoegd en door eenvoudige verwerkingslagen geleid in een multi-schaals U-vormig netwerk, dat van grove naar fijne resolutie en weer terug gaat. Deze opzet stelt het systeem in staat zowel grote cameraplatforms als kleine details zoals dunne randen of fijne patronen aan te kunnen, en herbouwt geleidelijk een schone versie van elk frame.
Hoe goed het in de praktijk werkt
De onderzoekers testen hun benadering op twee veeleisende benchmarks. De eerste betreft schone video’s die kunstmatig vervuild zijn met verschillende niveaus van willekeurige ruis, zodat ze precies kunnen meten hoe dicht de herstelde frames bij de originelen liggen. Hier evenaart of overtreft de nieuwe methode consequent de kwaliteit van eerdere convolutionele en recurrente netwerken, en komt ze dicht in de buurt van de beste bestaande transformer-gebaseerde modellen terwijl ze minder rekenwerk gebruikt. De tweede benchmark gebruikt echte videobeelden vastgelegd door sensors bij weinig licht, waar de ruis ongelijkmatig, gekleurd en veel minder voorspelbaar is. In deze realistischer test presteert de Shift Alignment Transformer duidelijk beter dan eerdere state-of-the-art methoden, en levert video’s op die schoner, scherper en stabiler over de tijd zijn, met minder kleurschommelingen en minder resterende artefacten.
Wat dit betekent voor toekomstige videotools
Kort gezegd tonen de auteurs aan dat het mogelijk is video’s effectief te ontwaarden zonder expliciet beweging te volgen, door slimme verschuivingen in tijd en ruimte te combineren met attention-gebaseerde feature-matching. Hun Shift Alignment Transformer biedt een goede balans tussen nauwkeurigheid en efficiëntie, vooral voor realistische low-light beelden, waar traditionele bewegingsschatting fragiel is. Naarmate attention-gebaseerde modellen efficiënter worden, zouden methoden als deze hun weg kunnen vinden naar alledaagse camera’s en streamingdiensten, waardoor ruizige, moeilijk te bekijken clips met weinig moeite voor de gebruiker veranderen in vloeiende, scherpe video’s.
Bronvermelding: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Trefwoorden: videoruisonderdrukking, transformer, beeldruis, low-light video, computer vision