Clear Sky Science · nl
Query-efficiënte decision-based adversarial attack met een laag query-budget
Waarom kleine oneffenheden in afbeeldingen slimme machines kunnen misleiden
Moderne kunstmatige intelligentie kan met indrukwekkende nauwkeurigheid gezichten, dieren en alledaagse voorwerpen herkennen. Toch kunnen deze systemen worden misleid door veranderingen in een afbeelding die zo klein zijn dat mensen ze nauwelijks zien. Dit artikel onderzoekt een nieuwe manier om zulke “misleidende” beelden te maken terwijl de AI zo weinig mogelijk vragen wordt gesteld, wat zowel laat zien hoe kwetsbaar huidige modellen kunnen zijn als hoe aanvallers hen in de praktijk zouden kunnen misbruiken.
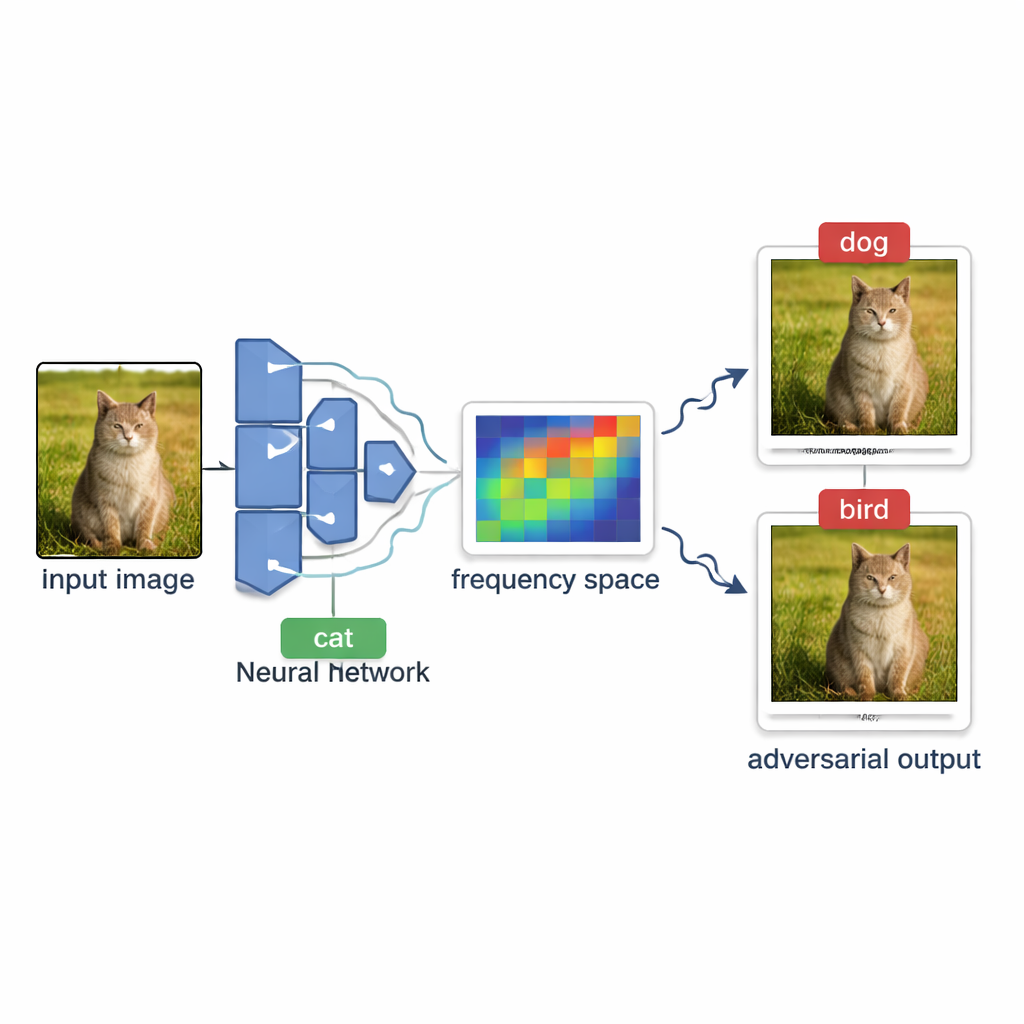
Hoe aanvallers AI-systemen van buitenaf onderzoeken
In veel echte diensten—zoals online fototagging of contentfilters—gedraagt het model zich als een black box. Buitenstaanders kunnen een afbeelding uploaden en zien alleen het uiteindelijke label, zoals “hond” of “stopbord,” maar nooit de interne confidentiescores of de structuur van het model. Het maken van een misleidende afbeelding onder deze voorwaarden wordt een decision-based black-box aanval genoemd. De uitdaging is om een normale afbeelding voorzichtig zo te veranderen dat het model hem verkeerd classificeert, zonder te kunnen zien hoe “dichtbij” het model is om van mening te veranderen en zonder zoveel testafbeeldingen te verzenden dat het systeem het opmerkt of te duur wordt om te bevragen.
Een nieuwe manier om te zoeken met zeer weinig vragen
De auteurs introduceren OPOQA (One Plane One Query Attack), een methode die is ontworpen om zuinig om te gaan met queries terwijl hij toch hoogwaardige adversarial beelden creëert. In plaats van herhaaldelijk te peilen langs één veronderstelde richting, werkt OPOQA in rondes. In elke ronde begint het vanaf een al misleidende afbeelding en de originele schone afbeelding, en stelt het vervolgens meerdere nieuwe kandidaat-afbeeldingen voor die in zorgvuldig gekozen richtingen liggen. Cruciaal is dat elke richting maximaal één keer wordt beproefd, waarmee het beperkte query-budget vrijkomt om veel meer mogelijkheden te verkennen in plaats van een enkele gok te veel te verfijnen.
Meeliften op de vloeiende variaties in een afbeelding
Om veelbelovende richtingen te kiezen, leunt OPOQA op het idee dat de meest effectieve, moeilijk waarneembare veranderingen vaak gladde, brede verschuivingen zijn in plaats van scherpe ruis op pixelniveau. De methode gebruikt een wiskundig hulpmiddel genaamd de discrete cosinustransformatie om de afbeelding in een “frequentie”-weergave te brengen, waar langzame, subtiele variaties in een compact gebied zitten. Hij neemt willekeurig een paar van deze laagfrequente componenten, zet ze terug om naar normale pixelveranderingen en gebruikt ze als basale richtingen voor exploratie. Elke bemonsterde richting helpt bij het definiëren van een vlak tweedimensionaal oppervlak dat de originele afbeelding, de huidige adversarial afbeelding en een nieuwe kandidaat verbindt. Op elk van deze oppervlakken kiest OPOQA één punt om te testen, waarbij twee doelen worden afgewogen: dichter bij het originele beeld komen terwijl het nog steeds waarschijnlijk is dat het model tot een foute beslissing wordt geduwd.

De beste kandidaat kiezen en zich ter plaatse aanpassen
Zodra OPOQA een kleine set kandidaat-afbeeldingen heeft gegenereerd, meet het hoe ver elk daarvan van de originele afbeelding afstaat en sorteert ze van minst naar meest veranderd. Het vraagt het model vervolgens in die volgorde. Op het moment dat het een kandidaat vindt die het model verkeerd classificeert, stopt het en behandelt die afbeelding als het nieuwe uitgangspunt voor de volgende ronde. Als geen van de kandidaten het model weet te misleiden, behoudt OPOQA de vorige beste adversarial afbeelding maar stelt een interne knop bij die bepaalt hoe conservatief of agressief de volgende reeks stappen zal zijn. Deze “gulzige” strategie—altijd de beste beschikbare misgeclassificeerde afbeelding accepteren en de stapgrootte dynamisch afstemmen—laat de aanval zich richten op subtiele, effectieve perturbaties zonder queries te verspillen aan weinig veelbelovende richtingen.
Wat de experimenten onthullen over de zwakke plekken van AI
De onderzoekers testten OPOQA op 200 afbeeldingen uit de grootschalige ImageNet-benchmark en zes veelgebruikte neurale netwerkmodellen, waaronder Inception-v3, ResNet, VGG, DenseNet en vision transformers. Onder een strikte limiet van 1.000 modelqueries per afbeelding evenaarde of overtrof OPOQA verschillende toonaangevende aanvalsmethoden. Bijvoorbeeld op Inception-v3 misleidde het model succesvol bij 94 procent van de afbeeldingen terwijl de veranderingen zo klein waren dat ze bijna onzichtbaar waren voor het menselijk oog, wat een verbetering was ten opzichte van de vorige beste methode met enkele procentpunten. Over de modellen heen bereikte OPOQA doorgaans hoge succespercentages eerder—met minder queries—alhoewel sommige concurrerende methoden bij grote query-budgets en tijd voor fijnslijpen alsnog konden bijtrekken of het zelfs konden overtreffen.
Wat dit betekent voor alledaagse AI-veiligheid
De studie toont aan dat hedendaagse visiesystemen kunnen worden misleid, zelfs wanneer aanvallers slechts de uiteindelijke beslissingen zien en beperkte mogelijkheden hebben om het model te bevragen. Door slim zachte, laagfrequente veranderingen te verkennen en elke query zorgvuldig te doseren, kan OPOQA afbeeldingen maken die voor mensen hetzelfde lijken maar machines ernstig op het verkeerde been zetten. Voor niet-experts is de conclusie dat AI’s “zicht” nog steeds tamelijk breekbaar is: het kan subtiel van koers worden gebracht op manieren die moeilijk op te merken zijn. Het herkennen en bestuderen van zulke efficiënte aanvallen is een sleutelstap om systemen in de echte wereld—zoals beveiligingscamera’s, medische beeldhulpmiddelen en autonome voertuigen—te versterken tegen manipulatie die anders onopgemerkt zou blijven.
Bronvermelding: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Trefwoorden: adversariale voorbeelden, black-box aanvallen, beveiliging van deep learning, beeldclassificatie, query-efficiënte aanval