Clear Sky Science · nl
MDI-YOLO een lichtgewicht transformer-CNN-gebaseerd multidimensionaal feature-fusiemodel voor detectie van kleine objecten
Scherpere ogen in de lucht
Van verkeersmonitoring tot rampenbestrijding: drones en satellieten houden onze wereld steeds vaker in de gaten. Toch zijn de zaken die we in deze beelden het meest willen zien — kleine auto’s, mensen, boten en vliegtuigen — vaak slechts een paar pixels groot. De paper over MDI‑YOLO pakt een eenvoudige maar cruciale vraag aan: hoe kunnen computers deze piepkleine objecten betrouwbaar detecteren in realtime, zelfs op energiezuinige apparaten die door drones worden gedragen?
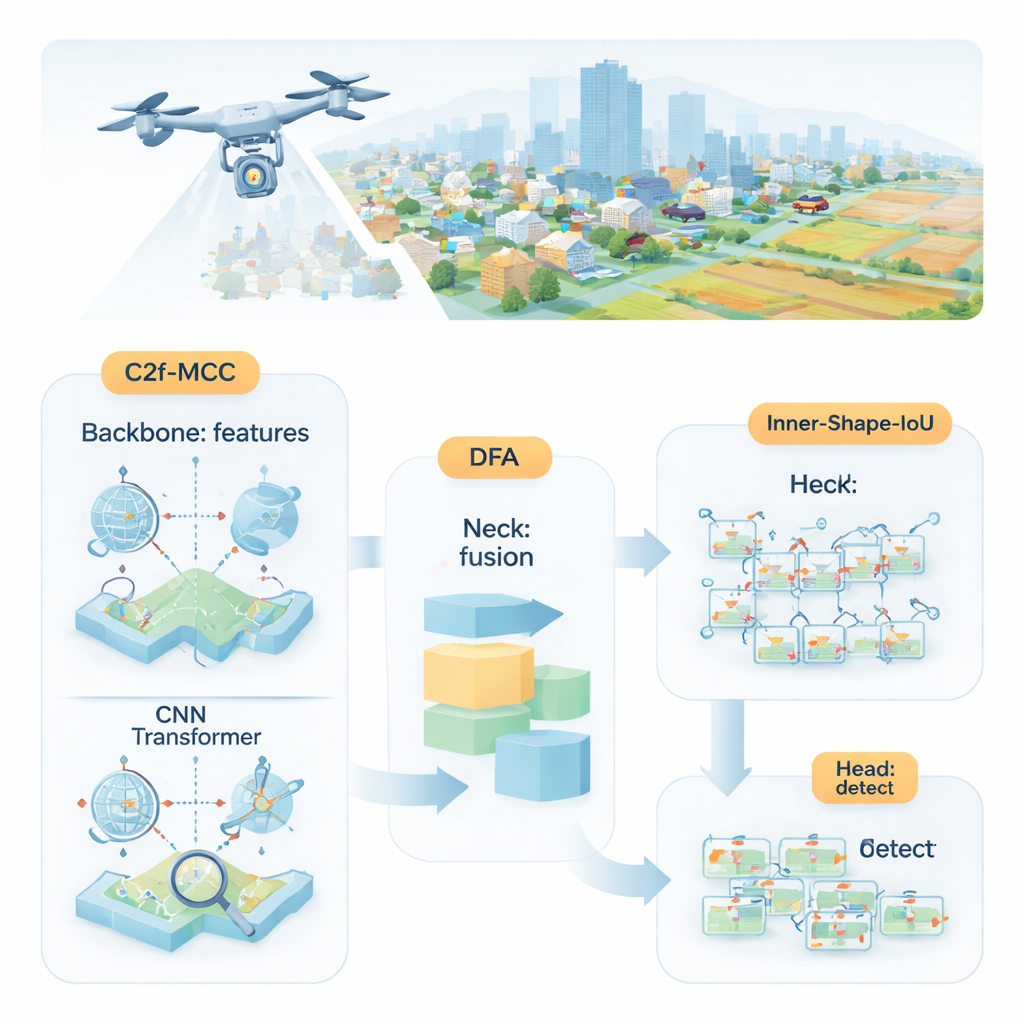
Waarom kleine objecten moeilijk te vinden zijn
In lucht- en satellietbeelden zijn objecten van belang meestal erg klein, vaak dicht opeengepakt en deels verborgen door gebouwen, bomen of schaduwen. Standaard detectiesystemen staan voor een trade‑off: lichtgewicht modellen draaien snel op edge‑apparaten zoals boordcomputers van drones, maar missen veel kleine doelen; zwaardere, nauwkeurigere modellen zijn te traag en te veel resources-intensief om praktisch in het veld te gebruiken. Kleine objecten vervloeien bovendien gemakkelijk met complexe achtergronden — denk aan grijze auto’s op grijze wegen — waardoor hun kenmerkende details kunnen verdwijnen als beelden worden gecomprimeerd en verwerkt door diepe netwerken.
Een nieuwe mix van globale en lokale visie
De onderzoekers stellen MDI‑YOLO voor, een herontworpen versie van de populaire YOLOv8-detector die het model compact houdt terwijl het beter wordt in het vinden van zeer kleine doelen. Centraal staat een nieuw bouwblok genaamd C2f‑MCC, dat de visuele informatie door het netwerk in twee paden splitst. Het ene pad gebruikt Transformer‑achtige verwerking, die goed is in het vastleggen van langafstandrelaties over het hele beeld — bijvoorbeeld hoe een cluster pixels past in een grotere weg of startbaan. Het andere pad blijft bij klassieke convolutionele filters, die uitblinken in het oppikken van lokale details zoals randen en texturen. Door kanalen te groeperen en slechts een deel van de gegevens via het zwaardere Transformer‑pad te sturen, wint het model aan globale context zonder fors in omvang toe te nemen of te vertragen.
Het netwerk helpen zich te concentreren op het wezenlijke
Zelfs met betere bouwblokken moet het netwerk nog steeds beslissen waar het op moet letten. Om dit te sturen introduceren de auteurs een mechanisme dat Directional Fusion Attention (DFA) heet. Deze module bekijkt patronen langs de breedte en hoogte van het beeld, evenals een algemene samenvatting van de scène, en leert hoe verschillende regio’s en feature‑kanalen gewogen moeten worden. In de praktijk moedigt DFA het model aan zich te concentreren op waarschijnlijke objectgebieden — zoals voertuigvormige vlekken op wegen — en repetitieve of verwarrende achtergrondtexturen te onderdrukken. Deze gecombineerde ruimtelijke en kanaalgerichte focus maakt het eenvoudiger om kleine doelen te onderscheiden van rommelige omgevingen of achtergrondgebieden met een vergelijkbare uitstraling.
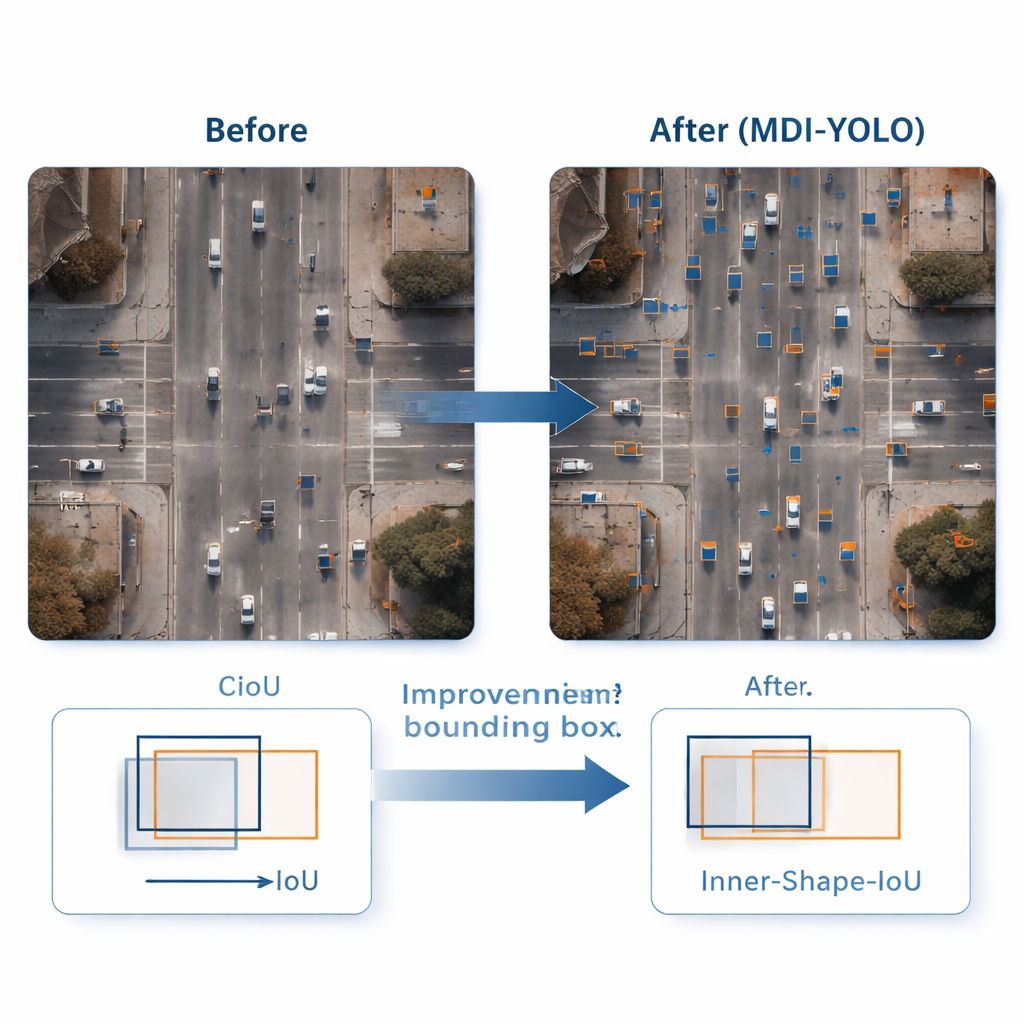
Strakkere kaders rond piepkleine doelen
Een object zien is nog maar de helft van het werk; de detector moet het ook nauwkeurig omlijnen. Standaard trainingsmethoden vergelijken voorspelde rechthoeken met de echte met een "overlap"-score, maar die kan ongevoelig zijn wanneer objecten klein of vreemd gevormd zijn. De auteurs ontwerpen een nieuwe verliesfunctie, Inner‑Shape‑IoU, die kaders beoordeelt niet alleen op overlap, maar ook op hoe goed hun vorm, grootte en centrale regio overeenkomen met het echte object. Door twee complementaire maatstaven te combineren, straft het functie die alleen de randen goed raken maar de kern missen af, wat leidt tot nauwkeurigere omtrekken — vooral voor kleine, dicht opeengepakte of langgerekte objecten.
Bewezen winst zonder extra gewicht
Om MDI‑YOLO te testen voerde het team experimenten uit op twee uitdagende openbare benchmarks: VisDrone2019, met dronebeelden van steden en verkeer, en DOTAv1.0, een grote verzameling luchtbeelden met veel kleine, dicht opeengepakte objecten. Zonder te leunen op voorgetrainde modellen verbeterde MDI‑YOLO de standaard nauwkeurigheidsscores met enkele procentpunten ten opzichte van de baseline YOLOv8, terwijl het aantal parameters vrijwel onveranderd bleef en de snelle inferentietijden behouden bleven. Vergeleken met een reeks populaire detectors — van lichtgewicht YOLO‑varianten tot zwaardere Transformer‑gebaseerde systemen — bood het een zeldzame combinatie van hoge nauwkeurigheid, lage rekenkosten en robuustheid over verschillende scènes.
Wat dit betekent voor gebruik in de praktijk
Voor niet‑specialisten komt het erop neer dat MDI‑YOLO drones en remote sensing‑systemen scherpere, betrouwbaardere "ogen" geeft zonder grote, energieverslindende computers te vereisen. Door op slimme wijze globale context, lokale details, gerichte aandacht en een meer onderscheidende manier van trainen van begrenzingsvakken te combineren, maakt de methode het makkelijker om kleine objecten te detecteren die van belang zijn voor veiligheid, monitoring en kaartlegging. Dit soort efficiënte, hoogprecisie visie is een belangrijke stap naar slimmer luchtplatforms die autonoom kunnen opereren, snel kunnen reageren en op grote schaal in de echte wereld kunnen worden ingezet.
Bronvermelding: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Trefwoorden: dronebeeldvorming, detectie van kleine objecten, remote sensing, YOLO, computer vision