Clear Sky Science · nl
DT-ondersteunde resourceallocatie via generative adversarial imitation learning in complexe cloud-edge-end scenario's
Slimmere gegevenssnelwegen voor het Internet of Things
Nu steden, fabrieken en woningen volstromen met verbonden sensoren en apparaten, produceren ze enorme hoeveelheden data die snel en betrouwbaar verwerkt moeten worden. Alles naar verre cloudservers sturen kan te traag zijn, terwijl kleine apparaten aan de "edge" vaak niet genoeg rekenkracht hebben. Dit artikel onderzoekt een nieuwe manier om automatisch reken-, opslag- en netwerkbronnen te routeren en toe te wijzen over apparaten, nabijgelegen edge-servers en de cloud—zodat slimme applicaties snel en robuust blijven, zelfs wanneer de echte wereld rommelig en onvoorspelbaar is.
Waarom de huidige methoden moeite hebben
Moderne systemen vertrouwen vaak op deep reinforcement learning, waarbij een algoritme via vallen en opstaan leert met beloningssignalen uit de omgeving. In complexe, rumoerige netwerken zijn die beloningen echter moeilijk te definiëren en te meten. Als de beloningsfunctie onjuist of vervormd is door interferentie, kan het systeem onveilig of verspild gedrag aanleren. Veel bestaande methoden veronderstellen bovendien uitgebreide voorkennis over verkeerspatronen en apparaatgedrag, iets wat in live industriële netwerken zelden beschikbaar is. Daarnaast optimaliseren de meeste oplossingen maar één type resource tegelijk—zoals rekenkracht—terwijl opslag en netwerkbandbreedte evenzeer samenwerken om de echte prestaties te bepalen.
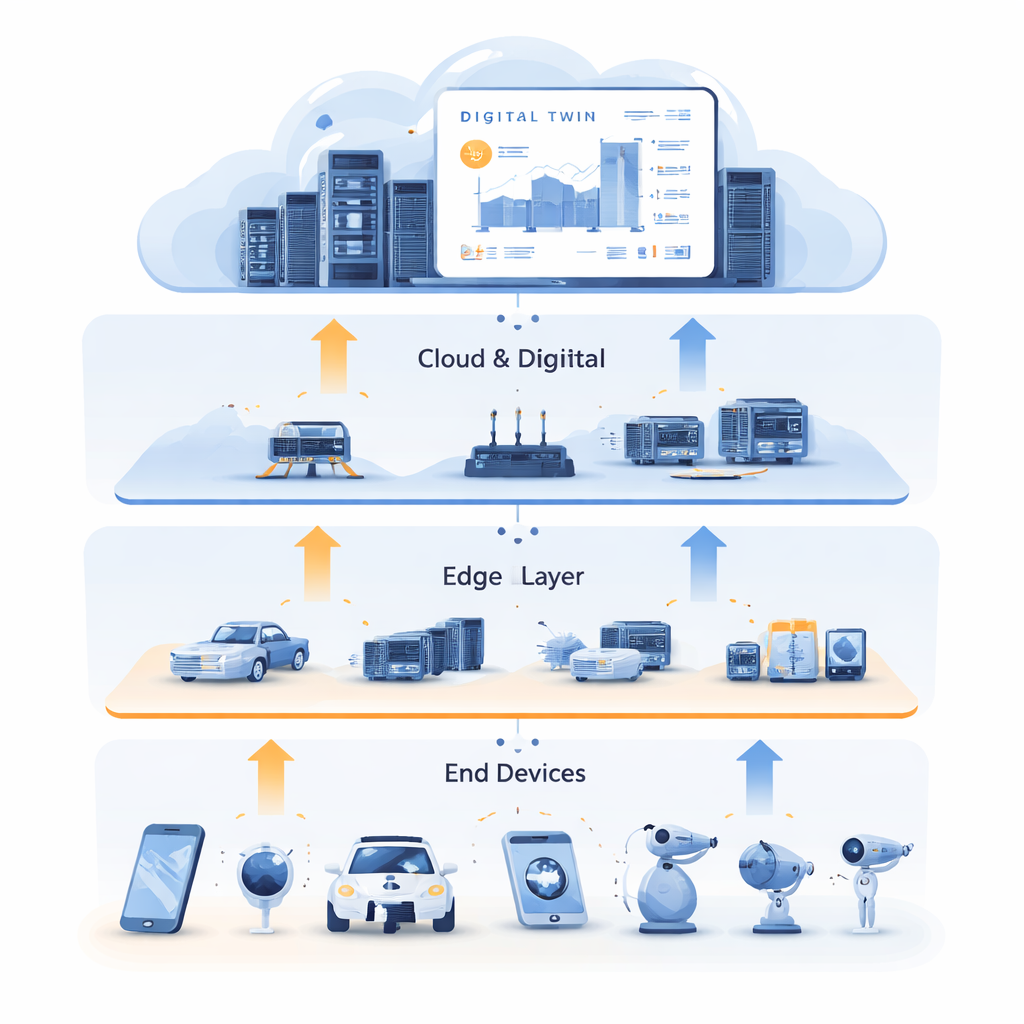
Leren van een digitale tweeling
Om deze impasse te doorbreken combineren de auteurs resourceallocatie met Digital Twin-technologie. Een Digital Twin is een gedetailleerde virtuele replica van het fysieke netwerk, in de cloud bijgehouden. Hij weerspiegelt de staat van edge-servers, verbindingen en taken in de tijd, gebruikmakend van rijke historische data uit sensoren en logs. In dit werk is de Digital Twin niet slechts een dashboard; hij wordt een trainingsomgeving. Het systeem gebruikt historische data om "expert"-voorbeelden van goede beslissingen te genereren, waarmee wordt vastgelegd hoe taken moeten worden opgesplitst tussen berekening en caching, en waar ze verwerkt moeten worden voor lage vertraging. Deze training vindt offline plaats, zonder live-diensten te verstoren, en benut de overvloedige rekencapaciteit van de cloud om vele mogelijke situaties te verkennen.
Imitatie in plaats van vallen en opstaan
In plaats van direct van beloningen te leren, hanteert het voorgestelde E‑GAIL-model imitatieleren: de agent probeert zich als een expert te gedragen. Eerst bouwen de auteurs meerdere expertpolicies met een Actor–Critic-framework dat is uitgebreid met een NoisyNet-laag. Het zorgvuldig injecteren van ruis in het beslissingsnetwerk stelt deze experts in staat een breed scala aan omstandigheden te ervaren—including verstoringen die echte draadloze interferentie en fluctuerende workloads nabootsen—zodat hun trajecten realistischer zijn. Vervolgens fuseert het systeem meerdere single-expert trajecten tot één "multi-expert" referentie met hulpmiddelen uit de speltheorie. Door te zoeken naar een Nash-evenwicht tussen de experts, vermijdt het conflicten en produceert het een consensusstrategie met bredere dekking van mogelijke scenario's.
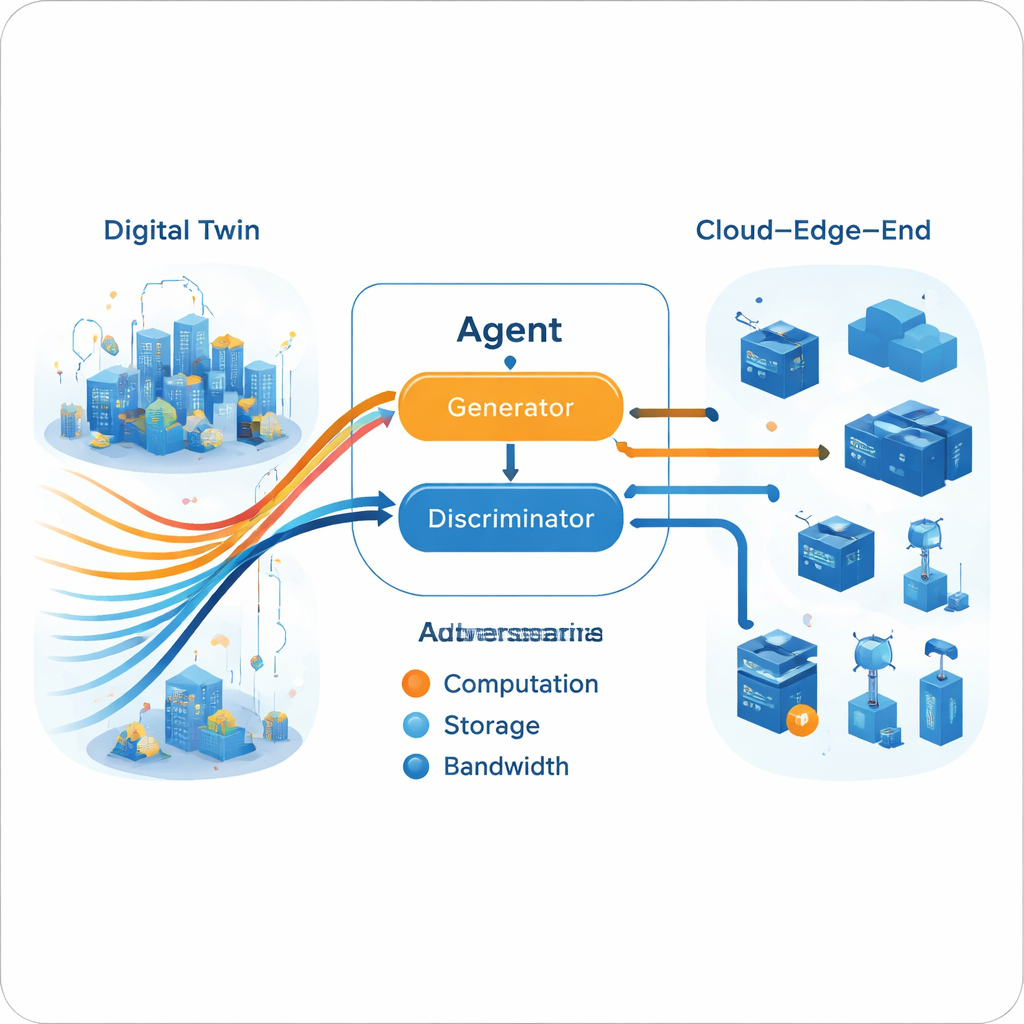
Een generatief adversariële motor voor beslissingen
Zodra het multi-expert traject in de Digital Twin is opgebouwd, leert de live-agent het te imiteren met een generatief adversariële opzet, vergelijkbaar van geest met beeldgenererende neurale netwerken. Een generator stelt resourceallocatie-acties voor gegeven de huidige netwerkstatus, terwijl een discriminator probeert te onderscheiden of een reeks acties van de agent of van de experttrajecten komt. In de loop van tijd dwingt dit adversariële spel de generator beslissingen te produceren die de discriminator niet van expertgedrag kan onderscheiden. Cruciaal is dat dit proces geen expliciete beloningsfunctie van de echte omgeving vereist. De training is opgesplitst: intensieve offline training (in de cloud) verfijnt experts en generator, terwijl lichtere online updates (aan de edge) het model in lijn houden met de actuele omstandigheden, binnen de praktische limieten van edge-hardware.
Hoe goed werkt het?
De auteurs testen E‑GAIL tegen diverse gangbare baselines, waaronder deep Q‑learning, speltheoretische offloading, gretige heuristieken, enkel cloudverwerking en willekeurige allocatie. Over veel experimenten—variërend het aantal eindapparaten, kanalen, taakmixen, workloads, datagroottes, afstanden en ruispatronen—bereikt E‑GAIL consequent end-to-end vertragingen die zeer dicht bij die van de expertpolicy liggen en duidelijk beter zijn dan andere geautomatiseerde methoden. Het past zich goed aan wanneer taken verschuiven tussen rekencentraal- en opslagintensief, wanneer het netwerk groeit of wanneer interferentie toeneemt. De Digital Twin versnelt het genereren van experttrajecten en verbetert hun kwaliteit, terwijl de multi-expert fusie de scenario's uitbreidt die de agent kan afhandelen zonder helemaal opnieuw te trainen.
Wat betekent dit voor alledaagse systemen
Voor niet-specialisten is de kernboodschap dat deze benadering netwerken intelligenter zichzelf laat beheren in het gezicht van onzekerheid. In plaats van regels met de hand te schrijven of te vertrouwen op kwetsbaar trial-and-error leren, leert E‑GAIL van rijke, gesimuleerde ervaring geleverd door een Digital Twin en van meerdere ervaren "experts" waarvan het advies wiskundig wordt verzoend. Het resultaat is een resource-allocator die snel kan beslissen waar taken te draaien en waar data op te slaan, waardoor reactietijden laag blijven zelfs wanneer omstandigheden veranderen. In toekomstige industriële en slimme-stadsystemen zouden zulke zelfgeleerde coördinatoren stilletjes rekenkracht, opslag en bandbreedte kunnen jongleren achter de schermen, waardoor onze verbonden wereld sneller, betrouwbaarder en energiezuiniger wordt.
Bronvermelding: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Trefwoorden: digital twin, edge computing, imitatieleren, resourceallocatie, Industrial Internet of Things