Clear Sky Science · nl
Snoeien van bomen in een bos en opnieuw bemonsteren voor onevenwichtige klassen
Waarom zeldzame gevallen belangrijk zijn voor slimme voorspellingen
Veel door kunstmatige intelligentie ondersteunde beslissingen draaien om het opsporen van het zeldzame voorval: een frauduleuze creditcardtransactie, een vroeg teken van ziekte of een gevaarlijke storing in een machine. In zulke situaties zijn de belangrijke gevallen sterk in de minderheid, en de meeste leeralgoritmen negeren ze geneigd. Dit artikel beschrijft een manier om één populaire methode, Random Forests, veel opmerkzamer te maken voor die zeldzame maar cruciale gevallen — en tegelijk het model compacter en sneller te maken.
Het probleem van ongelijk verdeelde voorbeelden
Standaard machine learning werkt het beste wanneer data goed in balans zijn — wanneer er ongeveer vergelijkbare aantallen voorbeelden voor elk uitkomst zijn. In de echte wereld domineren zeldzame gebeurtenissen echter veel taken. Bijvoorbeeld: slechts een klein deel van medische scans toont een tumor, en slechts een klein aandeel transacties is frauduleus. Dit onevenwicht maakt het gemakkelijk voor een algoritme om op papier goed te lijken door meestal de veelvoorkomende uitkomst te voorspellen, ook al mist het herhaaldelijk de zeldzame. Naarmate de kloof tussen veelvoorkomende en zeldzame gevallen groter wordt, verschuift de beslissingsgrens van het model richting de meerderheid en wordt de zeldzame klasse moeilijker te herkennen.
De balans herstellen met slimme bemonstering
Onderzoekers proberen zulke data vaak te herbelaatsen voor het trainen van modellen. Eén optie is de meerderheid inkorten (under-sampling), waarbij sommige veelvoorkomende gevallen worden weggelaten om het aantal overeen te laten komen met dat van de zeldzame gevallen. Een andere is het kopiëren of genereren van extra zeldzame voorbeelden (over-sampling), waardoor hun aanwezigheid toeneemt zonder originele data te verliezen. Een derde, hybride aanpak combineert beide ideeën, door sommige meerderheidsvoorbeelden te verwijderen en de minderheid tegelijkertijd te versterken. Elke tactiek heeft voor- en nadelen: inkorten kan nuttige informatie weggooien, terwijl veel dupliceren training trager kan maken en tot overfitting kan leiden. De auteurs maken gebruik van alle drie de strategieën om meer evenwichtige trainingssets te creëren die zijn aangepast aan de data.
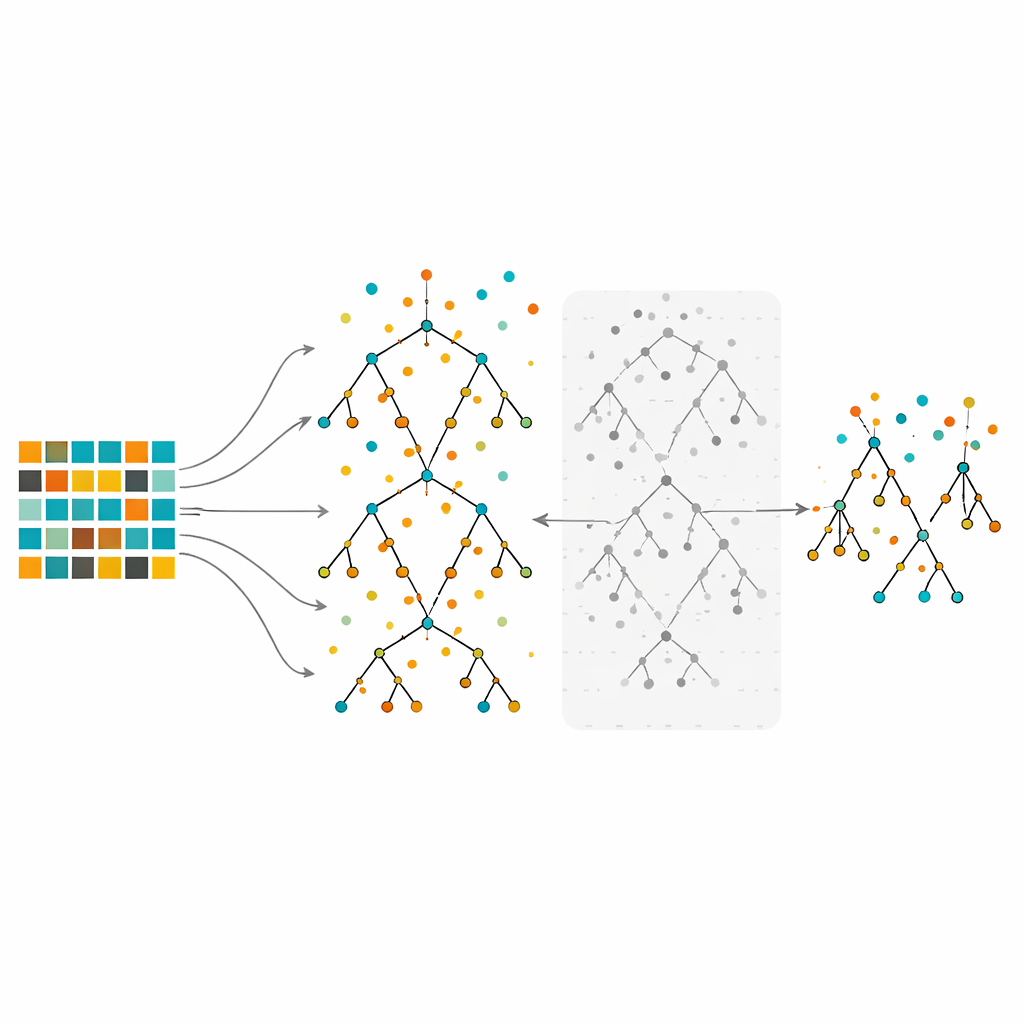
Een bos van beslissingsbomen trainen en bijsnoeien
De studie richt zich op Random Forests, een ensemblemethode die veel beslissingsbomen bouwt op licht verschillende steekjes uit de data en vervolgens hun stemmen combineert. Random Forests zijn bekend om het omgaan met complexe data en om het benadrukken welke kenmerken het belangrijkst zijn. Toch kunnen zelfs grote bossen, wanneer ze op sterk onevenwichtige data worden getraind, bevooroordeeld blijven richting de meerderheid. In de voorgestelde methode balanceren de auteurs eerst de data met under-sampling, over-sampling of een hybride aanpak. Vervolgens groeien ze veel bomen volgens de gebruikelijke Random Forest-procedure, maar met een belangrijke twist: in plaats van elke boom te behouden, evalueren ze iedere boom met behulp van out-of-bag-observaties — dat zijn datapunten die niet gebruikt zijn om juist die boom te bouwen — en verwijderen ze de helft met de slechtste foutpercentages. Deze snoeistap levert een kleiner, selectiever bos op dat is opgebouwd uit de betrouwbaarste bomen.
Testen op vele reale datasets
Om te beoordelen hoe goed dit bijgesnoeide bos presteert, testen de auteurs het op tien openbaar beschikbare datasets die een breed scala aan toepassingen weerspiegelen, van medische en biologische metingen tot spamfiltering van e-mail en geluidsclassificatie. Elke dataset heeft twee klassen, waarvan de ene duidelijk zeldzamer is dan de andere, en ze variëren in grootte, aantal kenmerken en mate van onbalans. De nieuwe methode wordt vergeleken met diverse veelgebruikte benaderingen: k-nearest neighbors, een enkele beslissingsboom, een standaard Random Forest, een Balanced Random Forest-variant en support vector machines. Over verschillende bemonsteringsstrategieën behaalt het bijgesnoeide bos consequent lagere classificatiefouten dan de alternatieven op de meeste datasets. De combinatie van hybride bemonstering plus snoeien levert de beste algehele resultaten, zowel qua nauwkeurigheid als qua stabiele prestaties over alle tien taken.
Schärpere modellen die minder moeite verspillen
Buiten nauwkeurigheid verbetert de aanpak ook de efficiëntie. Door de minder effectieve bomen weg te nemen is het uiteindelijke ensemble kleiner en vereist het minder rekenwerk om te trainen en om voorspellingen te doen, zonder in te leveren — en vaak met verbeterde — capaciteit om zeldzame gevallen te detecteren. Statistische toetsen bevestigen dat de winst ten opzichte van concurrerende methoden niet op toeval berust. Voor praktijkmensen die met onevenwichtige data werken laat dit werk zien dat het zorgvuldig balanceren van de trainingsset en vervolgens het snoeien van een Random Forest op basis van out-of-bag-prestaties modellen kan opleveren die zowel nauwkeuriger als efficiënter zijn. In alledaagse termen helpt de methode onze algoritmen om de zeldzame maar belangrijke signalen in een zee van gewone voorbeelden daadwerkelijk op te merken.
Bronvermelding: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Trefwoorden: klasse-imbalans, random forest, resampling, machine learning, ensemblemethoden