Clear Sky Science · nl
Federated learning voor heterogene elektronische patiëntendossiersystemen met kosteneffectieve selectie van deelnemers
Waarom het zo moeilijk is ziekenhuisgegevens te delen
Moderne ziekenhuizen verzamelen enorme hoeveelheden digitale informatie over hun patiënten, van laboratoriumuitslagen en vitale functies tot medicatie en procedures. In theorie zou het samenvoegen van deze dossiers over veel instellingen heen artsen in staat moeten stellen slimme computermodellen te bouwen die voorspellen wie risico loopt en welke behandelingen het meest kunnen helpen. In de praktijk gebruiken ziekenhuizen echter verschillende softwaresystemen, slaan ze gegevens op in incompatibele formaten en moeten ze strikt de patiëntprivacy en budgetten beschermen. Deze studie onderzoekt hoe ziekenhuizen van elkaars gegevens kunnen leren zonder die te kopiëren of de kosten uit de hand te laten lopen.
Samen trainen zonder ruwe dossiers te delen
De auteurs bouwen voort op een aanpak die federated learning heet, waarbij elk ziekenhuis een lokaal model traint op zijn eigen patiëntendossiers en alleen modelupdates deelt, niet de ruwe data. Een centraal "host"-ziekenhuis coördineert dit proces en streeft ernaar een voorspellingsmodel te verbeteren voor zijn eigen behoeften, zoals het voorspellen van complicaties op de intensive care. Andere ziekenhuizen, subjects genoemd, doen mee in ruil voor vergoeding. Deze opzet voorkomt het verplaatsen van gevoelige dossiers tussen instellingen, maar roept twee lastige vragen op: hoe om te gaan met vele verschillende dossiersystemen, en hoe te voorkomen dat er wordt betaald aan partners die het model nauwelijks helpen.
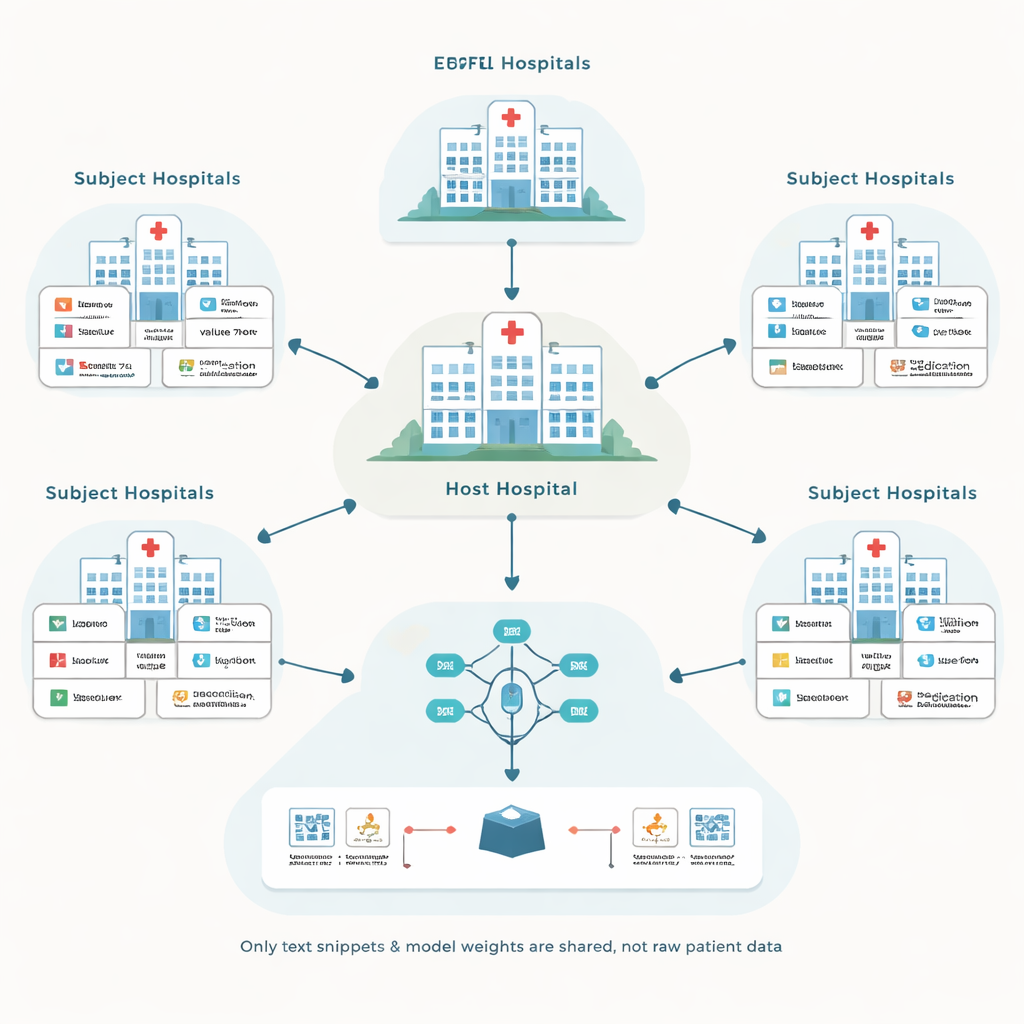
Warrige dossiers omzetten naar een gedeelde taal
Systemen voor elektronische patiëntendossiers verschillen sterk in hoe ze informatie labelen en coderen. Het ene ziekenhuis slaat bijvoorbeeld een bloedsuikermeting op onder een numerieke code, terwijl een ander ziekenhuis een andere code gebruikt voor dezelfde test. Traditionele oplossingen proberen alles om te zetten naar één zorgvuldig ontworpen standaardschema, wat duur is en veel deskundige tijd vergt. In plaats daarvan zet het voorgestelde kader, EHRFL genoemd, ieder medische gebeurtenis om in een korte tekstzin. Een laboratoriumregistratie zoals een glucosespiegel wordt bijvoorbeeld een frase als “lab event glucose value 70 mg/dL.” Omdat elk ziekenhuis al woordenboeken onderhoudt die lokale codes naar menselijk leesbare namen mappen, kan deze conversie worden geautomatiseerd zonder maatwerk.
Patientprofielen bouwen uit tekst
Wanneer gebeurtenissen als tekst zijn geschreven, gebruikt EHRFL moderne taalverwerkingsmodellen om elke gebeurtenis in een numerieke vector te veranderen en combineert het vervolgens vele gebeurtenissen tot één "patient embedding" – een compacte samenvatting van iemands medische geschiedenis over een tijdvenster. Deze embeddings voeden een voorspellingslaag die meerdere klinische taken tegelijk aanpakt, zoals het voorspellen van overlijden in het ziekenhuis of nierletsel na een opname op de intensive care. De auteurs voeren gefedereerde training uit op vijf grote, realistische intensive-care datasets die verschillende ziekenhuizen, tijdsperioden en dossiersystemen beslaan. Over een reeks algoritmen, inclusief veelgebruikte federated-methoden, presteren modellen die met deze op tekst gebaseerde aanpak zijn getraind consequent beter dan modellen die slechts op één ziekenhuis zijn getraind, zelfs als de onderliggende dataformaten verschillen.
De juiste partners kiezen terwijl privacy gewaarborgd blijft
Meer partnerziekenhuizen betekent niet altijd betere resultaten. Sommige instellingen hebben patiëntpopulaties of registratiepatronen die zo verschillen van de host dat deelname de training kan vertragen of de prestatie licht kan schaden, terwijl er toch kosten bijkomen. Om dit aan te pakken stellen de auteurs een selectiestap voor op basis van overeenkomst tussen ziekenhuizen’ gemiddelde patient embeddings. De host traint eerst een model op eigen data, deelt de modelgewichten, en elke kandidaat-ziekenhuis gebruikt deze om patient embeddings te berekenen. Om privacy te beschermen knipt elk subject extreme waarden uit zijn embeddings, maakt er een gemiddelde van in één vector, en voegt dan zorgvuldig gekalibreerde willekeurige ruis toe voordat het alleen dit vervuilde gemiddelde naar de host stuurt. De host vergelijkt zijn eigen gemiddelde met dat van elk subject met eenvoudige gelijkenismaatregelen en kiest alleen de meest vergelijkbare ziekenhuizen voor de volledige gefedereerde run.
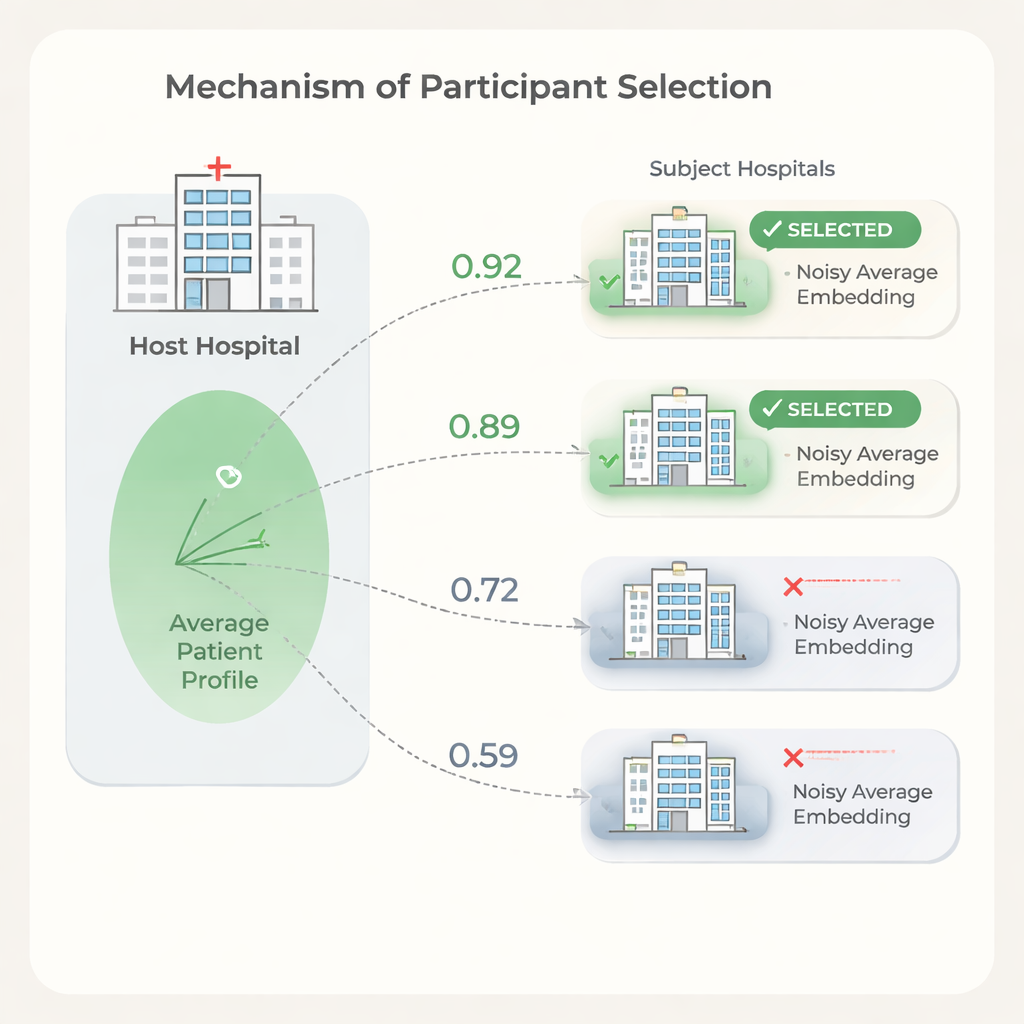
Geld besparen zonder nauwkeurigheid te verliezen
Experimenten tonen aan dat de overeenkomst tussen ziekenhuizen’ gemiddelde patient embeddings samenhangt met hoeveel elk ziekenhuis de voorspellingsprestatie van de host helpt of schaadt. Met dit signaal kan de host ziekenhuizen met lage overeenkomst laten vallen en tegelijk de voorspellingskwaliteit behouden of zelfs verbeteren vergeleken met het gebruik van alle beschikbare sites. De auteurs schetsen ook een kostenmodel dat laat zien dat, omdat datagebruikskosten en traintijd schalen met het aantal deelnemende ziekenhuizen, zelfs bescheiden verminderingen in het aantal partners tot aanzienlijke besparingen kunnen leiden. Tegelijk is de selectiestap lichtgewicht: het model wordt één keer getraind en elk ziekenhuis voert slechts eenvoudige berekeningen uit op één gemiddeld vector.
Wat dit betekent voor toekomstige AI in de gezondheidszorg
Voor lezers buiten het vakgebied is de kernboodschap dat het mogelijk kan zijn dat ziekenhuizen "samen leren" zonder ruwe patiëntendossiers samen te voegen, en dat dat op een manier kan gebeuren die zowel privacy als financiële beperkingen respecteert. Door uiteenlopende dossiers naar een gedeelde tekstvorm te vertalen en vervolgens privacybeschermde samenvattingen van patiëntpopulaties te gebruiken om compatibele partners te kiezen, biedt EHRFL een praktische aanpak voor het bouwen van ziekenhuisspecifieke voorspellende hulpmiddelen. Hoewel de studie zich richt op intensive care-data, zouden dezelfde ideeën kunnen worden uitgebreid naar poliklinieken, spoedeisende hulpen en zelfs niet-medische domeinen waar organisaties willen samenwerken aan betere modellen zonder de controle over hun data op te geven.
Bronvermelding: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Trefwoorden: federated learning, elektronische patiëntendossiers, patiëntprivacy, klinische voorspelling, gezondheidszorg AI