Clear Sky Science · nl
NeuroAction: een neuro-evolutionaire benadering van reinforcement learning voor autonome voertuigen
Waarom slimmere rijstijlen er toe doen
De meesten van ons denken aan zelfrijdende auto’s als kalme, perfect rationele chauffeurs. Maar de systemen van vandaag jagen meestal op één enkele mix van doelen — zoals niet botsen terwijl ze je snel op de bestemming krijgen — en die mix wordt door ingenieurs vastgelegd. NeuroAction, de benadering die in dit artikel wordt beschreven, wil autonome auto’s iets geven dat dichter bij menselijke flexibiliteit komt: het vermogen om uit vele veilige rijstijlen te kiezen, van voorzichtig “baby aan boord”-gedrag tot vlot snelwegrijden, zonder de auto telkens opnieuw te hoeven trainen.
Van one-size-fits-all naar veel veilige opties
Huidige deep reinforcement learning-systemen voor rijden leren door vallen en opstaan: ze observeren de weg, nemen acties zoals sturen en accelereren, en krijgen één numerieke beloning die verschillende doelen samenvoegt zoals snelheid, veiligheid en rijstrookpositie. Om het systeem aan te passen moeten ingenieurs die ene beloning heel zorgvuldig ontwerpen. Als ze snelheid te zwaar wegen, kan de auto agressief rijden; als ze veiligheid te sterk benadrukken, kruipt hij voort. Voorkeuren later veranderen betekent meestal dat je een groot kunstmatig neuraal netwerk opnieuw moet trainen, wat traag is, veel geheugen vereist en gevoelig is voor technische instellingen.
Rijden opdelen in eenvoudige doelen
NeuroAction pakt dit aan door de rijtaak te splitsen in meerdere duidelijke doelstellingen in plaats van één. In de studie wordt de virtuele bestuurder van de auto onafhankelijk beoordeeld op drie aspecten: hoe snel hij rijdt binnen een veilige marge, hoe trouw hij in de meest rechtse (meestal veiligere) rijstrook blijft, en hoe goed hij botsingen vermijdt. In plaats van deze te combineren tot één score, behandelt de methode ze als afzonderlijke maatstaven. Achter de schermen wordt elk mogelijke rijbeleid — het neurale netwerk dat sensorinput omzet in stuur- en snelheidsbeslissingen — tegelijkertijd op alle drie de assen geëvalueerd.
Laat evolutie naar betere bestuurders zoeken
In plaats van netwerkgwichten fijnaf te stemmen met de standaard backpropagation-techniek, gebruikt NeuroAction ideeën uit de biologische evolutie. Er wordt een populatie van verschillende rijbeleidsregels gecreëerd en getest in een gesimuleerde snelwegomgeving. Beleidsregels die goede afwegingen maken tussen snelheid, rijstrookdiscipline en veiligheid worden behouden en gecombineerd, terwijl slechtere worden weggegooid. Over vele generaties ontdekt dit evolutionaire proces een geheel aan sterke oplossingen — bekend als een Pareto-front — waar geen enkel beleid op één doel kan worden verbeterd zonder minstens één van de andere te schaden.
Evolutionair leren versus gradient-gebaseerd leren
De onderzoekers pasten NeuroAction toe op een veelgebruikte 2D-snelwegsimulator, met een standaard op neurale netwerken gebaseerde rijagent. Ze optimaliseerden vervolgens de parameters van de agent met verschillende gevestigde multi-objectieve evolutionaire algoritmen en vergeleken hoe goed elk algoritme het bereik aan wenselijke afwegingen kon bestrijken. Een belangrijke prestatiemaatstaf, het “hypervolume” van het ontdekte front, vangt zowel de kwaliteit als de diversiteit van de oplossingen. Eén algoritme, NSGA-II, behaalde de beste algemene dekking, terwijl een naaste verwant, NSGA-III, bijzonder consistente resultaten over herhaalde runs liet zien.
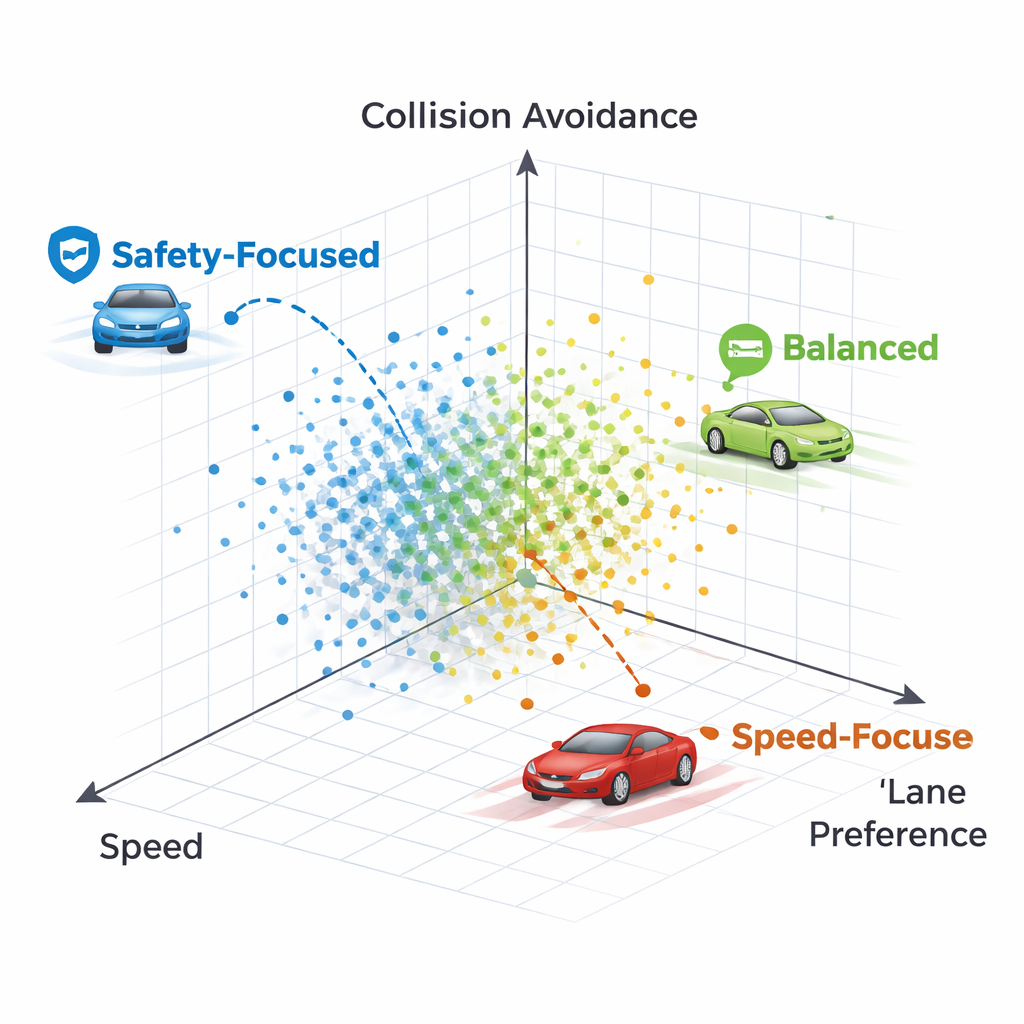
Hoe verschillende rijstijlen eruitzien
Door individuele beleidsregels op het Pareto-front te onderzoeken, tonen de auteurs aan dat elk punt overeenkomt met een herkenbaar andere rijstijl. Eén beleid blijft bijna koste wat het kost stevig in de rechterrijstrook, ten koste van snelheid en uiteindelijk met een botsing met een zeer langzaam voertuig voor zich — een overvoorzichtige strategie die rijstrookvoorkeur te hoog waardeert. Een ander beleid wisselt aanvankelijk van rijstrook maar keert dan terug naar een vrije rechterrijstrook, waarbij hogere snelheid wordt behouden terwijl botsingen worden vermeden. In het algemeen produceren de methoden een spectrum aan strategieën variërend van conservatieve, strookbehoudende bestuurders tot meer assertieve maar nog steeds veilige rijders, allemaal tegelijkertijd beschikbaar zonder hertraining.
Wat dit betekent voor toekomstige zelfrijdende auto’s
Voor niet-specialisten is de kernboodschap dat NeuroAction het trainen van zelfrijdende auto’s verandert in een zoektocht naar vele goede opties in plaats van één vast gedrag. Hierdoor wordt het mogelijk om een rijbeleid te kiezen dat bij de situatie past — langzaam en ultra-veilig bij het vervoeren van kinderen, sneller als je haast hebt — terwijl nog steeds aan veiligheidsbeperkingen wordt voldaan. Hoewel de huidige experimenten in simulatie zijn uitgevoerd en vereenvoudigde doelstellingen gebruiken, wijst het kader naar meer aanpasbare, voorkeurbewuste autonome voertuigen die gepersonaliseerde maar betrouwbare rijstijlen kunnen bieden op een stevige wiskundige basis.
Bronvermelding: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Trefwoorden: autonoom rijden, reinforcement learning, evolutionaire algoritmen, multi-objectieve optimalisatie, zelfrijdende auto’s