Clear Sky Science · nl
Tensorontbinding zonder rang via metrisch leren
Patronen vinden in een zee van gegevens
De moderne wetenschap verdrinkt in complexe data: stapels medische scans, kaarten van hersenactiviteit, astronomische beelden en simulaties van materialen. Deze gegevens begrijpelijk maken betekent vaak dat je ze in eenvoudigere vormen moet persen zonder te verliezen wat echt belangrijk is. Dit artikel introduceert een nieuwe manier om dat te doen. In plaats van te proberen elke pixel nauwkeurig te reconstrueren, richt het zich op het vastleggen van de werkelijke relaties tussen voorbeelden — welke hersenen meer op elkaar lijken, welke galaxievorm op welke lijkt — zodat de resulterende kaart van de data betekenis weerspiegelt in plaats van ruwe details.
Van het herbouwen van beelden naar het meten van gelijkenis
Traditionele hulpmiddelen om multidimensionale data te vereenvoudigen, bekend als tensorontbindingen, werken een beetje alsof je een akkoord in noten splitst. Ze ontbinden een datablock in een klein aantal basispatronen plus gewichten. Hiervoor moet van tevoren worden opgegeven hoeveel patronen — de “rang” — mogen worden gebruikt, en succes wordt beoordeeld op hoe goed de oorspronkelijke data kunnen worden gereconstrueerd. Dat is ideaal voor compressie of ruisonderdrukking, maar niet per se voor taken zoals “zijn deze twee gezichten dezelfde persoon?” of “behoort deze hersenscan tot een autistische of een typische proefpersoon?”, waar correcte groepering belangrijker is dan perfecte reconstructie.
Parallel hieraan heeft deep learning een ander idee populair gemaakt: in plaats van een tensor algebraïsch te ontbinden, leer je een compacte numerieke code, of embedding, via een neuraal netwerk. Klassieke auto-encoders richten zich nog steeds op reconstructie. Dit werk draait het doel om. Het stelt een “geen-rang” kader voor dat niet van tevoren een rang vastlegt en zich niet bekommert om pixel-perfect herstel. In plaats daarvan leert het een afstandsmaat zodat punten die dicht bij elkaar zouden moeten staan (dezelfde persoon, dezelfde diagnose, dezelfde fysische klasse) buren worden in de embedruimten, en punten die verschillend zouden moeten zijn van elkaar worden wegduwen.
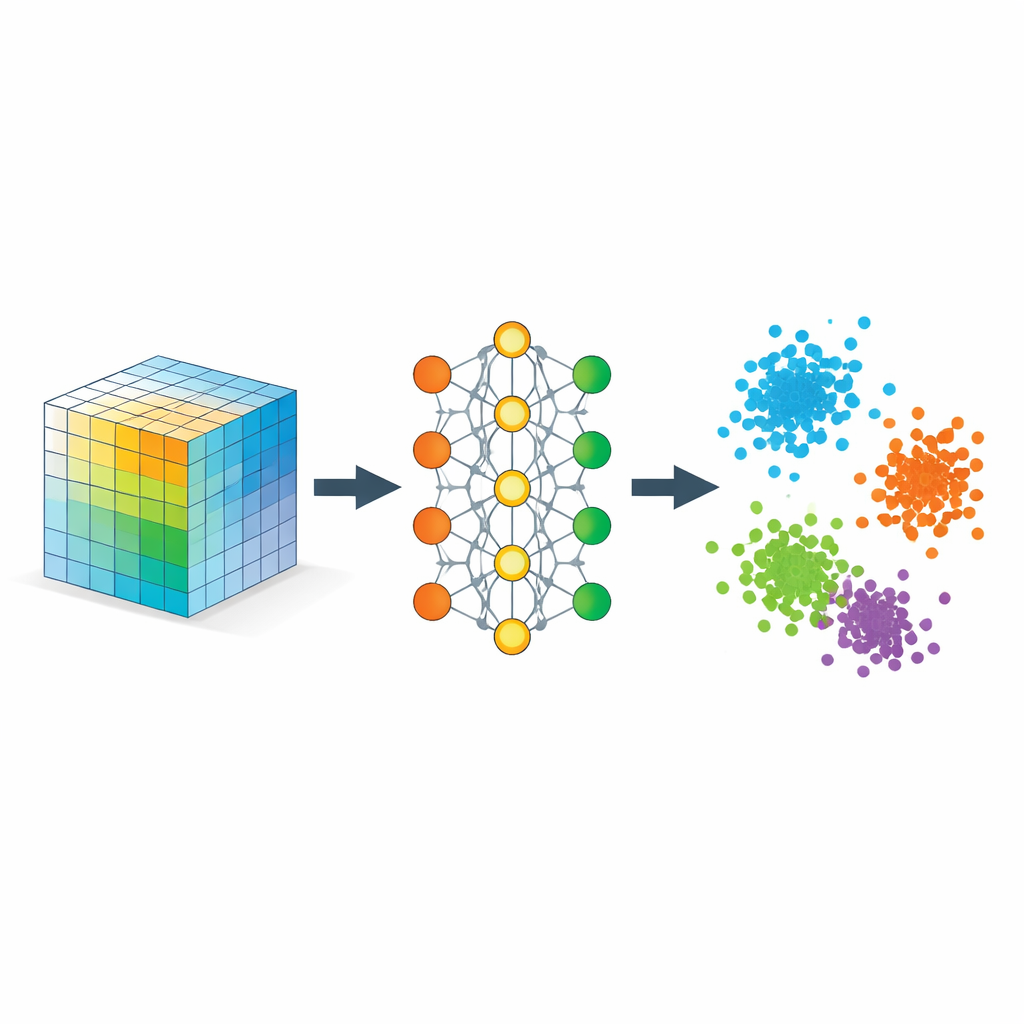
Het netwerk leren wat “dicht” zou moeten betekenen
Het sleutelingrediënt is een strategie die metrisch leren wordt genoemd, hier geïmplementeerd via triplets van voorbeelden: een ankervoorbeeld, een positief voorbeeld van hetzelfde type en een negatief voorbeeld van een ander type. Tijdens het trainen wordt het netwerk beloond wanneer het anker dichter bij het positieve staat dan bij het negatieve met een veiligheidsmarge. Over veel zulke triplets boetseert deze eenvoudige regel de embedruimte zodat afstanden semantische gelijkenis weerspiegelen in plaats van ruwe pixels. Extra regularisatoren moedigen het netwerk aan informatie gelijkmatig over dimensies te verspreiden, te voorkomen dat alles in één lijn instort, en lokale buurten ruwweg intact te houden, zodat punten die oorspronkelijk dichtbij lagen ook dichtbij blijven na embeddingen.
Wiskundig laten de auteurs zien dat deze embedding zich gedraagt als een flexibele tensorontbinding, maar zonder een vooraf bepaalde rang. De geleerde coördinaten kunnen worden geïnterpreteerd als factoren in een klassieke ontbinding van een gelijkenistensor waarvan de elementen meten hoe sterk verschillende delen van de data op elkaar aansluiten. Omdat het model redundante richtingen straft, heeft het de neiging alle embed-dimensies effectief te gebruiken, en laat het de data zelf bepalen hoeveel betekenisvolle componenten nodig zijn. Tegelijkertijd leveren zij theoretische garanties dat standaard trainingsprocedures convergeren en dat de resulterende geometrie klassen betrouwbaar scheidt zonder lokale betekenisvolle relaties sterk te vervormen.
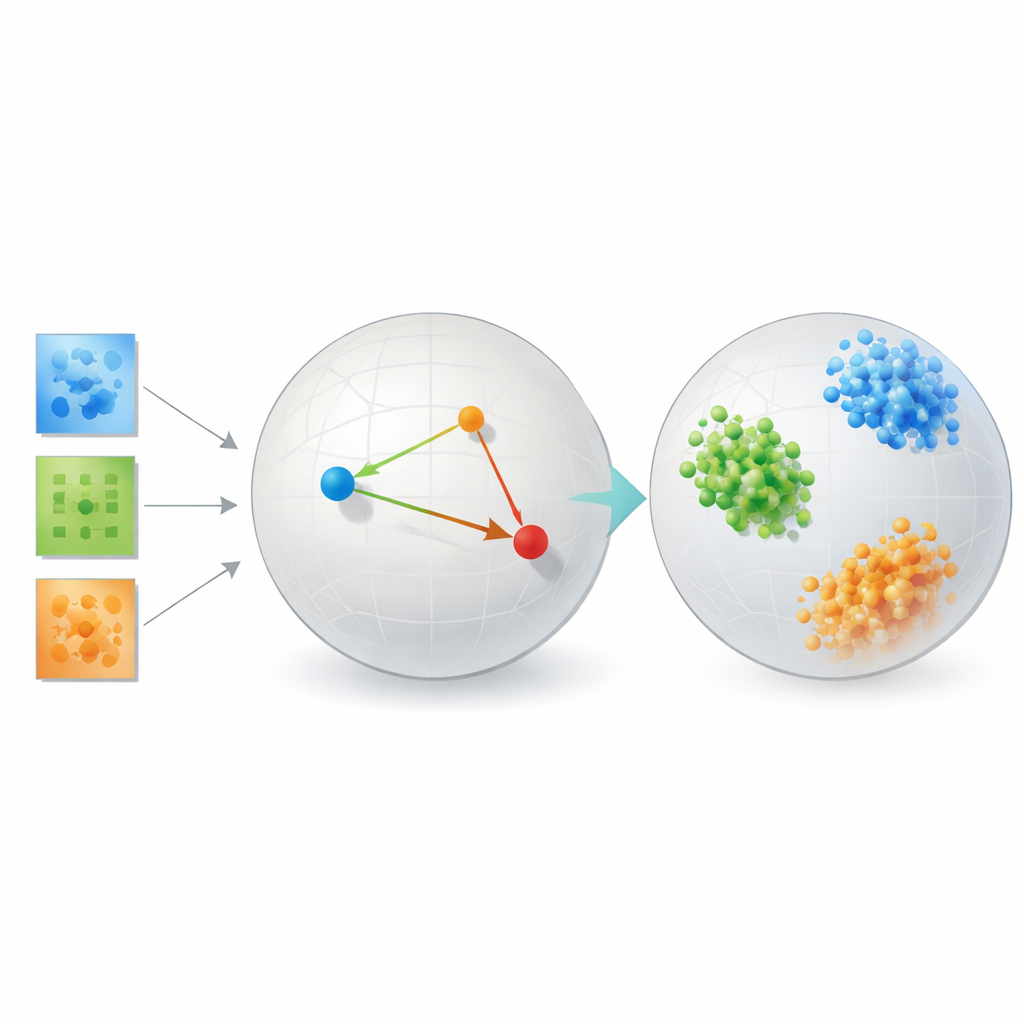
De methode op de proef stellen
Om te laten zien dat hun aanpak niet alleen elegante theorie is, testen de auteurs het op verschillende, zeer verschillende problemen. In gezichtserkenning-benchmarks groeperen de geleerde embeddings afbeeldingen van dezelfde persoon in strakke, goed gescheiden clusters en presteren ze aanzienlijk beter dan klassieke methoden zoals hoofdcomponentenanalyse, populaire visualisatietools zoals t-SNE en UMAP, en traditionele tensorontbindingen die afhankelijk zijn van vaste rangen. Bij hersenconnectiviteitsdata van mensen met en zonder autisme ontdekt de methode een ruimte waarin de twee groepen schoner van elkaar zijn gescheiden dan met reconstructiegerichte tensorhulpmiddelen of autoencoder-netwerken, wat erop wijst dat het klinisch relevante patronen in de interactie tussen hersengebieden oppikt.
De studie bevat ook gecontroleerde simulaties van galaxievormen en kristalstructuren, waarbij de “ware” categorieën exact bekend zijn. Hier clustert het metrisch-leren-kader bijna perfect de synthetische galaxieën en kristallen op hun onderliggende fysieke typen. In al deze settings ruilt de methode consequent wat trouw aan de oorspronkelijke pixellay-out in voor een representatie waarin gelijkenis en verschil samenkomen met wetenschappelijke betekenis. Belangrijk is dat het dit doet zonder de enorme data- en rekenmiddelen die vaak nodig zijn om transformer-gebaseerde diepe modellen te trainen, welke moeite hadden met deze relatief kleine wetenschappelijke datasets.
Waarom dit belangrijk is voor toekomstige wetenschappelijke data
Voor wetenschappers die patronen zoeken in beperkte, hoog-dimensionale data biedt dit werk een aantrekkelijke verschuiving in perspectief. In plaats van een rang te raden en te optimaliseren voor reconstructie, kunnen onderzoekers direct vragen om een embedding die de relaties weerspiegelt die zij belangrijk vinden: dezelfde diagnose, dezelfde materiefase, dezelfde astrofysische klasse. Het voorgestelde geen-rang metrisch-leren-kader laat zien dat zulke embeddings zowel interpreteerbaar als krachtig kunnen zijn, vooral wanneer data schaars zijn. Zoals de auteurs opmerken blijven uitdagingen bestaan — waaronder omgaan met klasse-imbalance en opschalen naar veel categorieën — maar de boodschap is duidelijk: in veel wetenschappelijke problemen kan het leren van een goede notie van gelijkenis waardevoller zijn dan elk detail van het oorspronkelijke signaal te reconstrueren.
Bronvermelding: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Trefwoorden: metrisch leren, tensorontbinding, representatie leren, dimensionaliteitsreductie, wetenschappelijke data-analyse