Clear Sky Science · nl
Een VLM-gestuurde netwerk-koppeling voor degradatiemodellering voor degradatiebewuste fusie van infrarode en zichtbare beelden
Scherper nachtzicht voor een luidruchtige wereld
Moderne camera’s kunnen in het donker zien, warmte waarnemen en de weg voor ons in de gaten houden — maar hun beelden zijn vaak verre van perfect. Straatlantaarns gloeien, schaduwen verbergen details en sensoren voegen korrelig ruis toe. Deze studie presenteert een nieuwe manier om gewone kleurvideo te combineren met warmte-sensorische infraroodbeelden, zodat het eindbeeld helderder en betrouwbaarder wordt, zelfs wanneer beide invoeren sterk gedegradeerd zijn. De methode kan autonome voertuigen, bewakingssysteem en andere slimme camera’s betrouwbaarder maken in de omstandigheden waarin we ze het meest nodig hebben: ’s nachts, bij slecht weer en in rommelige real-world scènes.
Waarom twee ogen beter zijn dan één
Zichtbare-lichtcamera’s leggen de rijke kleuren en texturen vast waaraan mensen gewend zijn, maar ze hebben moeite bij weinig licht, schittering en zware schaduwen. Infraroodcamera’s daarentegen detecteren warmte en kunnen gemakkelijk warme objecten zoals mensen of voertuigen in het donker onderscheiden, hoewel hun beelden vaak vlak lijken en fijne details missen. Fusie van infrarood- en zichtbare beelden probeert het beste van beide te combineren: de scherpe contouren van warme doelwitten uit infrarood met de contextuele details en kleur van zichtbaar licht. Traditioneel veronderstellen de meeste fusiemethoden echter dat beide invoerbeelden al schoon en van hoge kwaliteit zijn — een slechte fit voor echte straten, steden en industriële locaties waar onscherpte, ruis, schemering en overbelichting eerder regel dan uitzondering zijn.
Wanneer voorbewerking tekortschiet
Bestaande systemen pakken slechte beelden doorgaans aan in twee losgekoppelde stappen. Eerst fellen aparte verbeteringshulpmiddelen donkere scènes op, verminderen ze ruis of corrigeren contrast. Pas daarna mengt een fusienetwerk de verbeterde beelden. Deze tweeledige aanpak heeft verschillende nadelen. Het dwingt ingenieurs om verschillende verbeteringshulpmiddelen te kiezen en af te stemmen voor elk type defect en elke sensor, waardoor workflows kwetsbaar en complex worden. Belangrijker nog: informatie die verloren gaat of vervormd raakt tijdens losse opschoning kan later door de fusiefase niet worden hersteld. Sommige recente onderzoeken introduceerden speciale netwerken afgestemd op één specifiek soort degradatie of gebruikten taalgestuurde modellen om één slechte modaliteit tegelijk te behandelen. Wanneer echter zowel infrarood- als zichtbare beelden gedegradeerd zijn — en vaak op verschillende manieren — blijven deze strategieën sterk afhankelijk van handmatige voorbewerking en worstelen ze met gemengde, real-world omstandigheden.
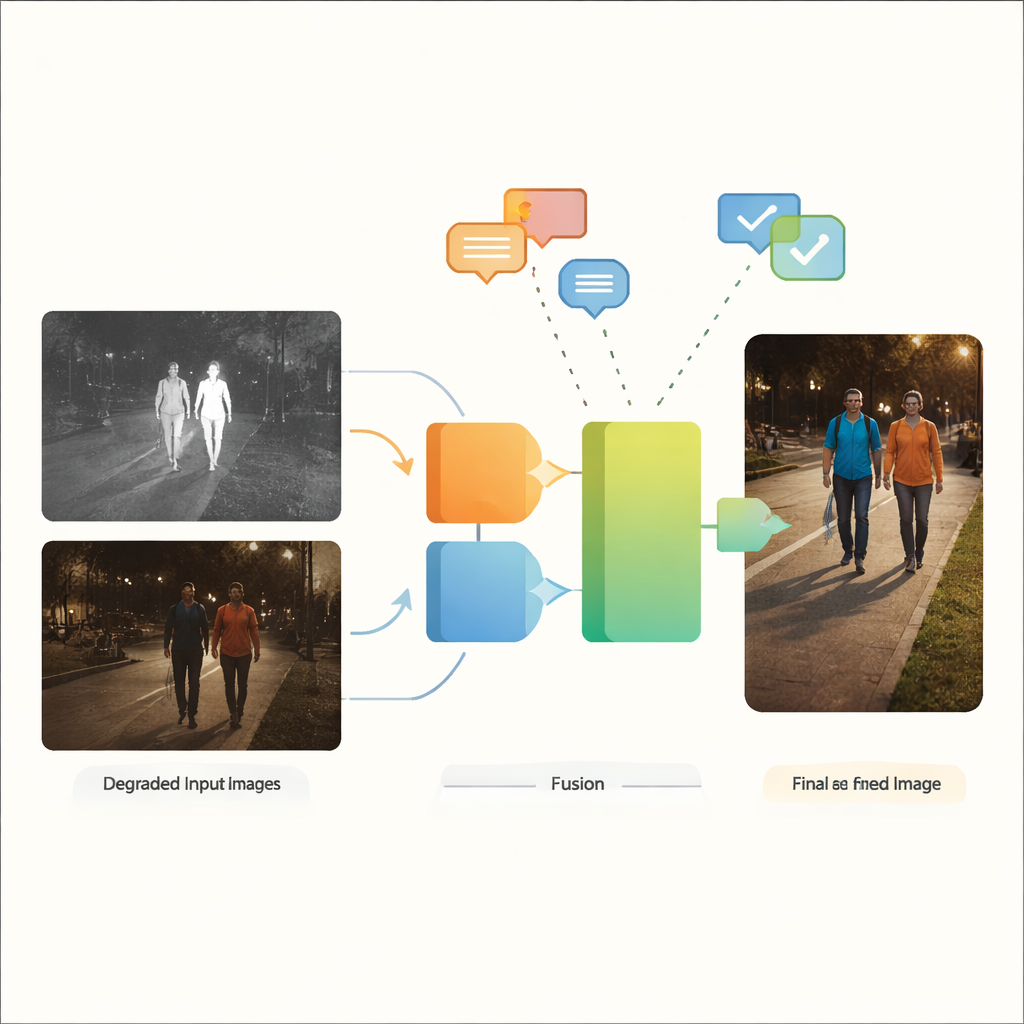
Een fusienetwerk dat degradatie begrijpt
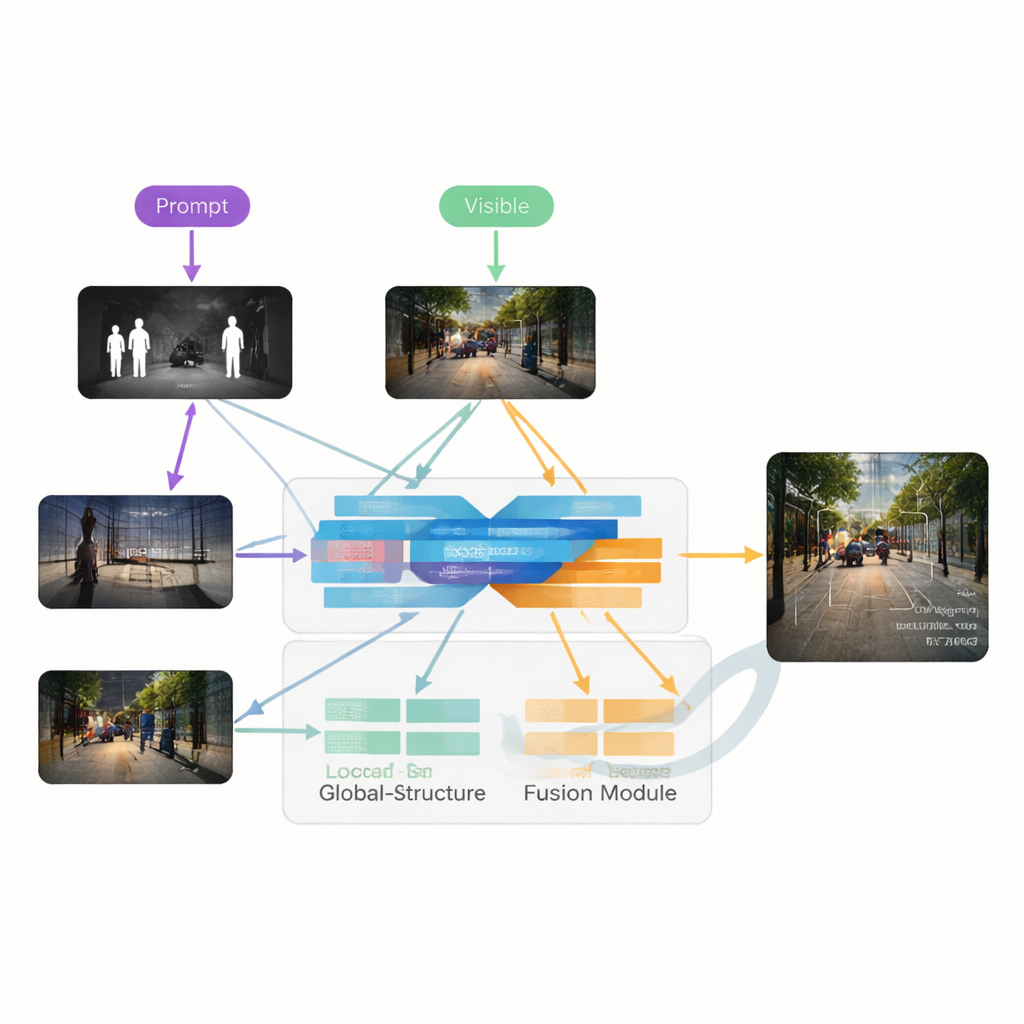
De auteurs stellen VGDCFusion voor, een nieuw deep-learning kader dat degradatieverwerking rechtstreeks in het fusieproces verweeft. Het belangrijkste idee is het netwerk in woorden te laten weten welke problemen het kan verwachten, en die kennis vervolgens bij elke stap van feature-extractie en samenvoeging te gebruiken. Korte tekstprompts beschrijven de taak (infrarood–zichtbare fusie) en de specifieke problemen die aanwezig zijn, zoals weinig licht, overbelichting, laag contrast of ruis. Een krachtig visie–taalmodel — vergelijkbaar in geest met systemen als CLIP — zet deze prompts om in compacte numerieke descriptors. Deze descriptors sturen twee hoofdcomponenten aan: de Specific-Prompt Degradation-Coupled Extractor (SPDCE), die afzonderlijk op elke modaliteit werkt, en de Joint-Prompt Degradation-Coupled Fusion (JPDCF), die informatie over modaliteiten heen mengt terwijl het aandacht blijft besteden aan welke degradatie nog aanwezig is.
Hoe het begeleide fusieproces werkt
Binnen elk SPDCE-module stuurt de prompt-afgeleide begeleiding het netwerk naar features die ertoe doen en weg van artefacten. Multi-schaal convolutielagen kijken naar kleine buurten om randen en texturen te behouden, terwijl Transformer-lagen grotere structuren en context vastleggen. Samen leren ze bijvoorbeeld belangrijke warmtesignaturen in een korrelig infraroodframe te benadrukken of vage wegmarkeringen in een onderbelicht zichtbaar beeld uit te lichten, terwijl sensorruis en lichtproblemen worden onderdrukt. Parallel nemen JPDFC-modules de opgeschoonde features van beide takken en combineren die opnieuw onder promptbegeleiding. Ze gebruiken ruimtelijke en kanaalgerichte aandacht om informatieve regio’s te benadrukken, resterende degradatie te filteren en complementaire aanwijzingen samen te brengen — zoals het uitlijnen van een heldere infraroodcontour van een voetganger met de kleur en achtergrondstructuur van de zichtbare camera — voordat ze een gefuseerd, driedimensionaal kanaaluitvoerbeeld reconstrueren.
De methode op de proef stellen
Om het nut aan te tonen, evalueerde het team VGDCFusion op verschillende openbare datasets die onderbelichte en overbelichte zichtbare beelden bevatten evenals ruisige of laag-contrast infraroodbeelden. Ze vergeleken hun methode met een reeks state-of-the-art fusietechnieken, variërend van auto-encoders, convolutionele netwerken, generatieve adversariële netwerken tot Transformers. Met behulp van standaard beeldkwaliteitsmaatregelen produceerde VGDCFusion consequent gefuseerde beelden met scherpere randen, beter contrast en natuurlijkere kleuren, zelfs wanneer concurrerende methoden het voordeel kregen van zorgvuldig afgestemde voorbewerking. De nieuwe aanpak verbeterde sleutelmetrieken met ongeveer 15% gemiddeld in zwaar gedegradeerde scenario’s. Toen de gefuseerde beelden werden gevoed aan een populair objectdetectiesysteem, leidde dat ook tot een hogere detectieaccuratesse dan het gebruik van alleen infrarood- of zichtbare beelden, of het gebruik van andere fusienetwerken.
Helderder zicht voor veiligere systemen
Kort gezegd toont dit werk aan dat het vertellen aan een beeldfusienetwerk welke visuele problemen het kan verwachten — en het laten herstellen en samenvoegen in één nauw verbonden stap — schonere, meer informatieve beelden kan opleveren dan het behandelen van verbetering en fusie als afzonderlijke taken. Door degradatiemodellering te koppelen aan het fusieproces en taalgestuurde aanwijzingen op elke laag te gebruiken, kan VGDCFusion zich aanpassen aan gevarieerde en gemengde vormen van beelddegradatie zonder constante handmatige herafstemming. Dit soort intelligente, degradatiebewuste fusie kan toekomstige visiesystemen helpen, van zelfrijdende auto’s tot beveiligingscamera’s, betrouwbaarder te zien in de rommelige, imperfecte omstandigheden van de echte wereld.
Bronvermelding: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Trefwoorden: infrarood- en zichtbare fusie, weinig-licht beeldvorming, visie-taalmodellen, beelddegradatie, waarneming voor autonoom rijden