Clear Sky Science · nl
Een hybride gestapeld ensemble-leerframework voor multilabel emotieherkenning in tekst
Waarom het lezen van emoties in tekst ertoe doet
Dagelijks leggen mensen hun gevoelens vast in berichten op sociale media, recensies en berichten. Verborgen in deze stroom woorden zitten vroege signalen over mentale gezondheidsproblemen, toenemende haatspraak en publieke reacties op crises en rampen. Computers zien echter meestal alleen ‘positieve’ of ‘negatieve’ sentimenten en missen daarmee de mix van emoties die mensen vaak tegelijk uiten. Dit artikel onderzoekt een nieuwe manier om machines meerdere emoties in één tekst te laten herkennen, en dat niet alleen in het Engels maar ook in talen die zelden profiteren van geavanceerde kunstmatige intelligentie.
Voorbij simpel positief of negatief
Traditionele sentimentanalyse-instrumenten zijn als botte thermometers: ze geven aan of de stemming goed of slecht is, maar niet of iemand tegelijkertijd woede, angst, hoop of opluchting voelt. De auteurs betogen dat het begrijpen van dit rijkere emotionele palet cruciaal is voor toepassingen zoals rampenrespons, therapeutische ondersteuning en klantenservice. Een bericht dat angst en urgentie mengt, kan bijvoorbeeld onmiddellijke aandacht vereisen, terwijl een bericht dat verdriet en optimisme combineert om een andere vorm van ondersteuning vraagt. Het vastleggen van meerdere emoties parallel—bekend als ‘multi-label’ emotieherkenning—is daarom een belangrijke stap richting meer gevoelige, mensgerichte systemen.
Een stem geven aan over het hoofd geziene talen
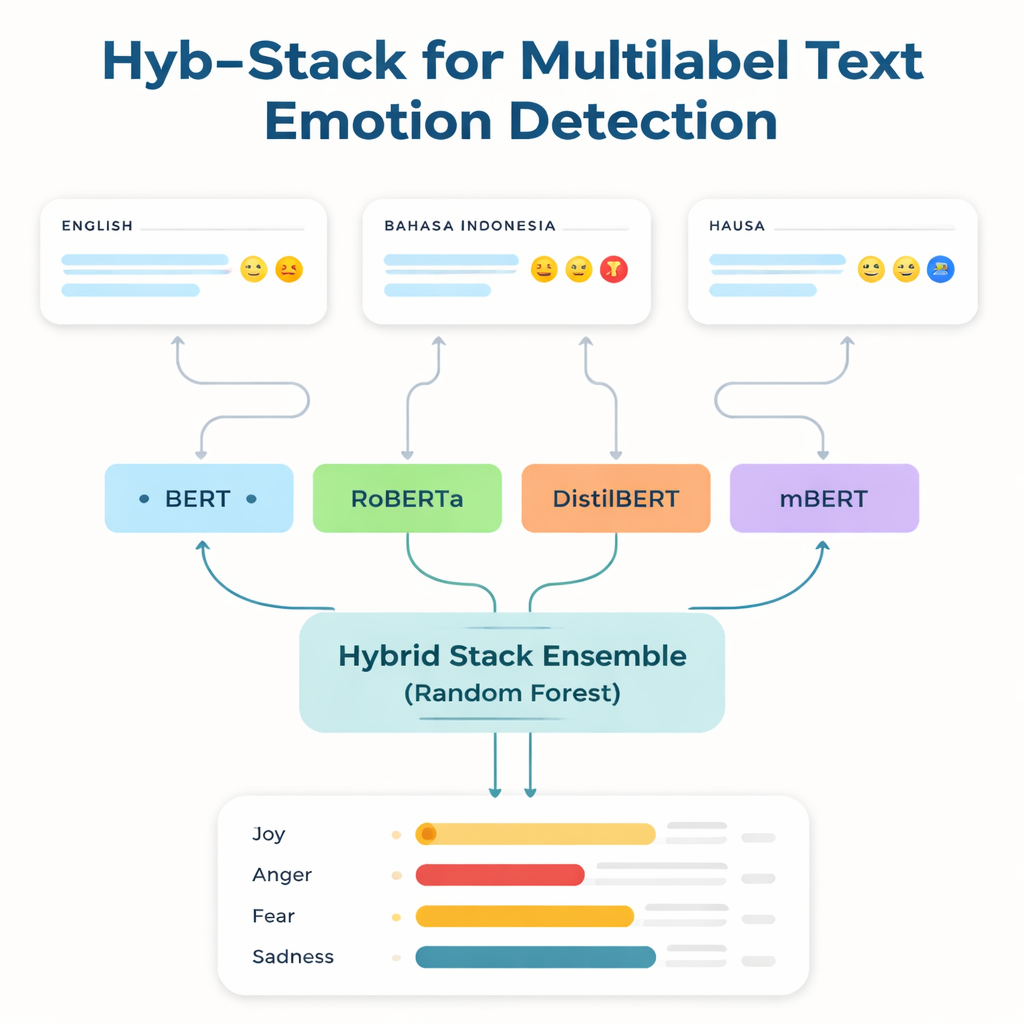
De meeste krachtige taaltechnologieën worden getraind en afgestemd op Engels en een paar andere veelgebruikte talen. Sprekers van talen met weinig middelen—talen met weinig gelabelde data en weinig digitale hulpmiddelen—blijven vaak achter. Om deze kloof aan te pakken, richten de onderzoekers zich op drie datasets: een bekende Engelse emotie-benchmark; een Bahasa Indonesia-verzameling gericht op beledigende en haatdragende taal; en een gloednieuw Hausa-Twittercorpus dat zij hebben gemaakt, HaEmoC_V1 genoemd. De Hausa-dataset bevat meer dan twaalfduizend zorgvuldig schoongemaakte en geannoteerde tweets, elk gelabeld met één of meer van elf emoties zoals woede, vreugde, vertrouwen, pessimisme en anticipatie. Deskundige beoordelaars controleerden de labels en de overeenstemmingsscores toonden aan dat de annotaties zowel consistent als betrouwbaar zijn.
Meerdere slimme lezers combineren tot één
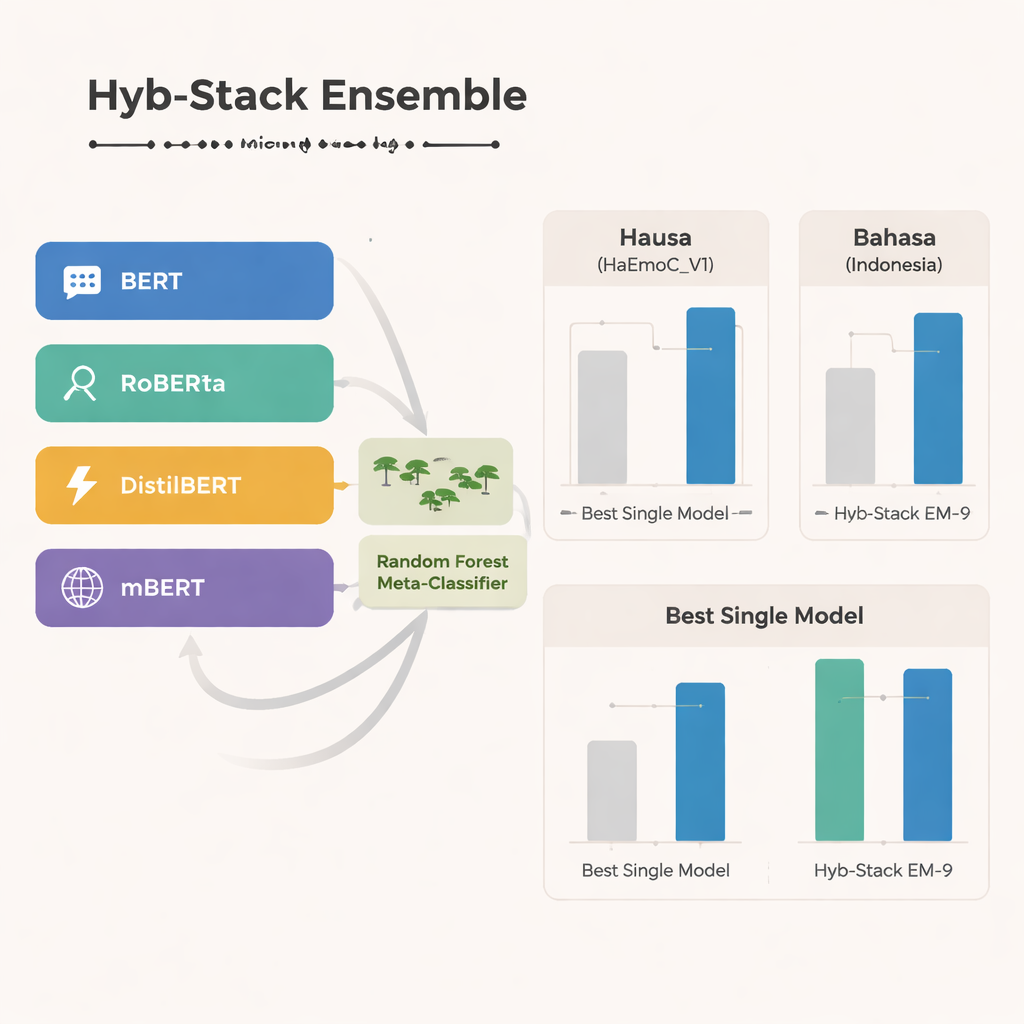
De kern van de studie is Hyb-Stack, een hybride gestapeld ensemble—een soort ‘commissie van experts’ voor taal. Vier geavanceerde transformermodellen (BERT, RoBERTa, DistilBERT en het meertalige mBERT) worden elk fine-tuned om emotionele signalen in tekst te lezen. In plaats van op slechts één model te vertrouwen, laat Hyb-Stack al deze modellen voorspellingen doen en voert vervolgens hun interne scores in een beslisser op tweede niveau: een Random Forest-classifier. Deze meta-classifier leert hoe de verschillende sterke punten van elk model gewogen moeten worden en vangt complexe patronen in hoe emoties samenvallen. Het team test ook eenvoudigere ensemblemethoden die voorspellingen gewoon middelen, met of zonder weging op basis van eerdere prestaties, om te onderzoeken of het meer geavanceerde stapelen echt zijn meerwaarde heeft.
Hoe goed de hybride aanpak presteert
Over alle drie talen heen springt het meertalige mBERT eruit als het sterkste afzonderlijke model; het presteert bijzonder goed op de nieuw opgebouwde Hausa-data en de Bahasa Indonesia-hatestelling. Toch gaat het hybride ensemble nog een stap verder. Een specifieke combinatie—EM-9 genoemd, die BERT, DistilBERT en mBERT binnen het Hyb-Stack-framework samenvoegt—levert consequent de beste resultaten. Het behaalt hogere F1-scores, een veelgebruikte maat voor nauwkeurigheid, dan elk individueel model of eenvoudige middelenbenaderingen, met de grootste winst in de Hausa- en Bahasa Indonesia-datasets met beperkte middelen. Gedetailleerde foutanalyses tonen aan dat resterende fouten meestal voorkomen tussen sterk verwante emoties, zoals vreugde versus verrassing of verdriet versus angst, wat de natuurlijke vaagheid van menselijke gevoelens weerspiegelt in plaats van duidelijke systeemfouten.
Wat dit betekent voor systemen in de echte wereld
Voor de algemene lezer is de belangrijkste conclusie dat het slim combineren van meerdere AI-modellen computers kan helpen emoties in tekst nauwkeuriger te lezen, vooral in talen die lange tijd zijn verwaarloosd in de technologie. Door een hoogwaardige Hausa-emotiecorpus op te bouwen en te laten zien dat hybride ensembles beter presteren dan losse modellen en eenvoudige stemschema’s, tonen de auteurs een praktische weg naar meer inclusieve, emotioneel bewuste hulpmiddelen. Toekomstig werk zal de aanpak uitbreiden naar subtielere emotionele nuances, code-gemengde taal, emoji’s en extra ondervertegenwoordigde talen, met als doel systemen te creëren die niet alleen kunnen inschatten of mensen blij of verdrietig zijn, maar ook hoe en waarom ze zich zo voelen—ongeacht welke taal ze spreken.
Bronvermelding: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Trefwoorden: emotieherkenning, meertalige NLP, ensemble learning, transformermodellen, talen met beperkte middelen