Clear Sky Science · nl
Rivierextractie uit hoge-resolutie satellietbeelden op basis van niet-uniforme bemonstering en semi-gesuperviseerd leren
Waarom rivieren vanuit de ruimte in kaart brengen belangrijk is
Rivieren vormen onze akkers, steden en overstromingsvlaktes, maar monitoring ter plaatse is duur en ongelijk verdeeld. Hedendaagse aardobservatiesatellieten kunnen elke bocht en zijtak in verbluffend detail vastleggen, maar die beelden omzetten in schone, betrouwbare kaartlagen van rivieren blijft technisch uitdagend. Deze studie presenteert een nieuwe methode om automatisch rivieren te volgen in hoge-resolutie satellietbeelden, met als doel nauwkeurigere informatie te leveren voor irrigatieplanning, overstromingswaarschuwingen, ecosysteembescherming en waterbeheer — en tegelijk de hoeveelheid menselijke labelwerk die normaal nodig is te verminderen.
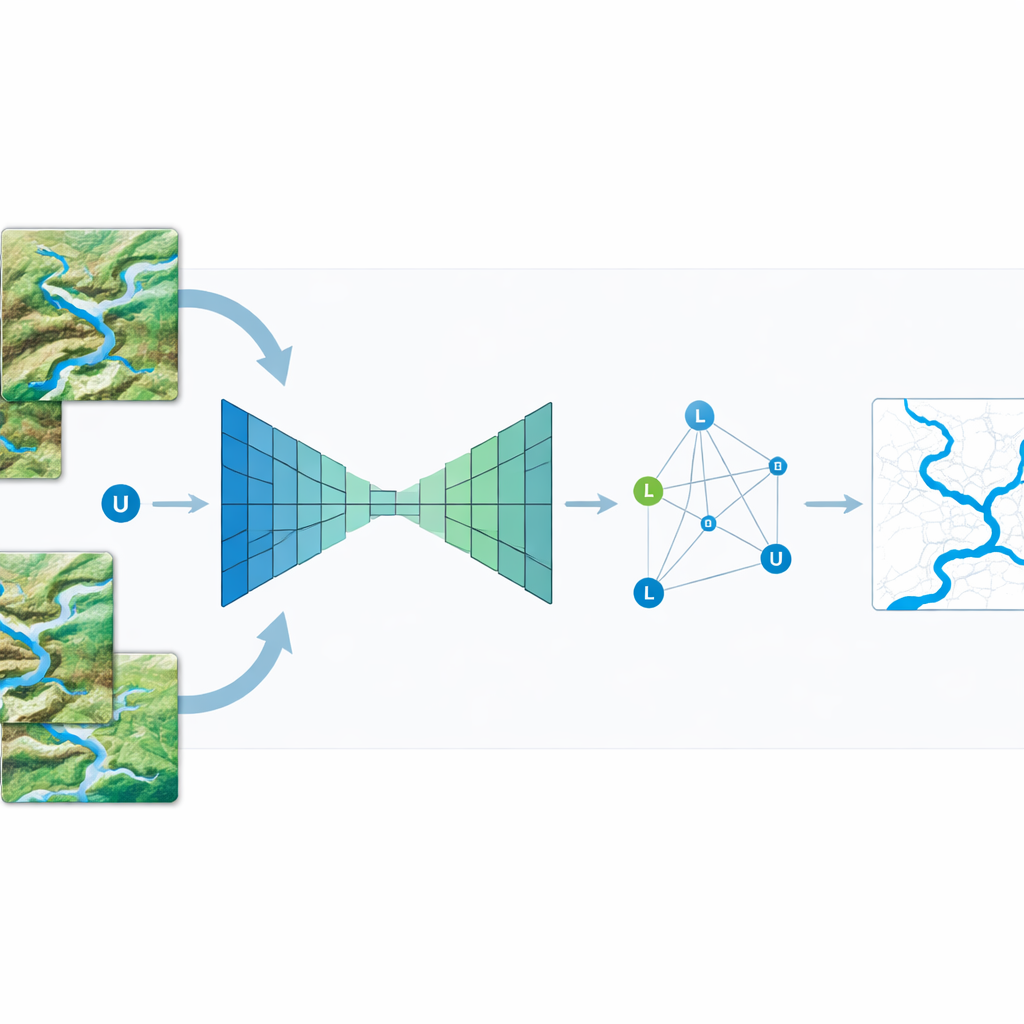
De uitdaging van rivieren vinden in complexe beelden
Moderne kaartsystemen vertrouwen vaak op deep learning, een techniek waarbij computermodellen patronen leren herkennen, zoals water versus land, uit veel voorbeeldbeelden. Deze systemen presteren goed voor grofmazige kenmerken maar hebben moeite met details. In satellietbeelden kunnen rivieroevers slechts enkele pixels breed zijn en verstrengeld zitten met wegen, schaduwen en gebouwen die qua kleur en helderheid veel lijken op water. Standaard encoder–decoder-netwerken behandelen elke pixel evenwaardig tijdens het leren, waardoor ze moeite verspillen aan grote uniforme gebieden zoals velden of meren en onvoldoende aandacht besteden aan smalle grenzen waar fouten het meest tellen. Bovendien is het maken van precieze trainingskaarten — waarbij een mens elke rivier heeft getraceerd — langzaam en kostbaar, waardoor er weinig gelabelde data beschikbaar zijn.
Een slimmer manier om te focussen op rivierkanten
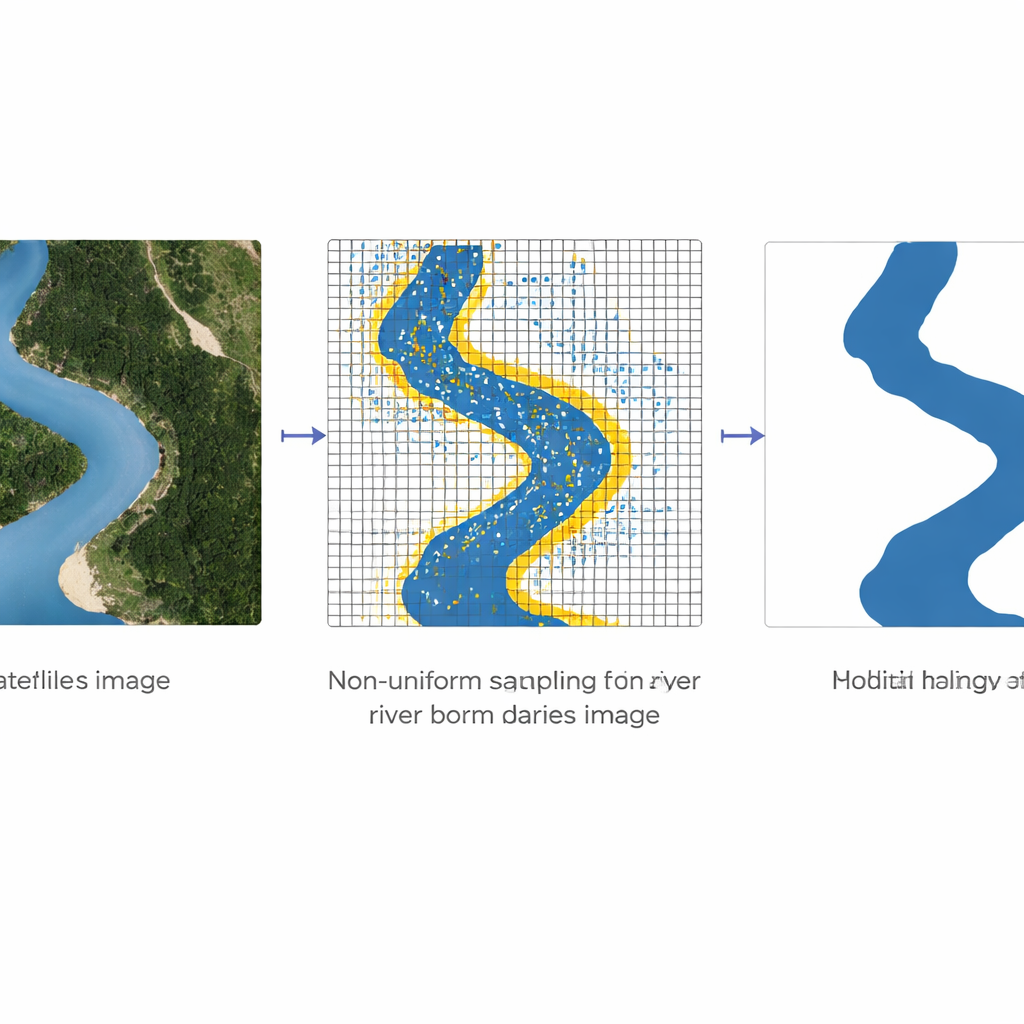
De auteurs pakken deze problemen aan met een techniek genaamd niet-uniforme bemonstering. In plaats van het netwerk alle pixels met gelijke weging te geven, kiezen ze doelbewust meer punten in “hoogfrequente” gebieden — plekken waar kleur en helderheid snel veranderen, zoals de randen tussen water en land — en minder punten in gladde gebieden. Grove informatie uit de diepere lagen van het netwerk, die het grotere geheel zien, wordt gecombineerd met fijne details uit de ondiepere lagen, die scherpe randen vastleggen. Bilineaire interpolatie, een eenvoudige methode om waarden in twee richtingen gemiddeld te combineren, wordt gebruikt om deze grove en fijne signalen te mengen zodat elk geselecteerd punt zowel lokale details als bredere context weerspiegelt. Door alleen deze zorgvuldig gekozen punten herhaaldelijk te verfijnen, kan het model rivieroerlijnen verscherpen zonder de zware kosten van het analyseren van elke pixel op volledige resolutie.
Ook leren van niet-gelabelde beelden
Om de prestaties verder te verbeteren, voegt de studie semi-gesuperviseerd leren toe, waarmee het systeem kan profiteren van veel niet-gelabelde satellietbeelden. De methode behandelt elk afbeeldingspatch — gelabeld of niet — als een knooppunt in een graaf en verbindt vergelijkbare patches met elkaar. Informatie van de enkele patches met bekende rivierslabels verspreidt zich vervolgens door deze graaf, waardoor de voorspellingen voor niet-gelabelde patches geleidelijk worden bijgestuurd zodat ze consistent zijn met hun dichtstbijzijnde buren. In praktische termen betekent dit dat het model structuur kan “lenen” van de niet-gelabelde beelden en leert waar rivieren vaak voorkomen en hoe ze zich verhouden tot het omliggende landschap, zelfs wanneer voor die specifieke scènes geen mens de rivierlijnen heeft getekend.
Hoeveel beter werkt het?
De onderzoekers testten hun aanpak op een grote Chinese satellietdataset (Gaofen-2) en op de wereldwijde OpenEarthMap-collectie. Wanneer ze niet-uniforme bemonstering toepasten op drie veelgebruikte rivierenkaartsystemen — Unet, Linknet en DeeplabV3 — werden ze allemaal accurater en convergeerden ze sneller tijdens het trainen. Gemeten met standaardscores zoals pixelaccuracy en intersection-over-union, verbeterde rivierdectectie grofweg met één tot drie procentpunt alleen al door slimmer te bemonsteren. Toen ze vervolgens semi-gesuperviseerd leren toevoegden en alle beschikbare niet-gelabelde beelden gebruikten, steeg de nauwkeurigheid met ongeveer vijf procentpunt en de overlapscore met meer dan negen punten. De methode vergeleek ook gunstig met toonaangevende semi-gesuperviseerde technieken zoals Mean Teacher en Cross Pseudo Supervision, en deed dat met minder rekenkosten dan een sterke DeeplabV3-baseline.
Wat dit betekent voor kaartvorming van rivieren in de praktijk
Voor niet-specialisten is de conclusie eenvoudig: de auteurs hebben een systeem gebouwd dat rivieren uit satellietbeelden schoner en efficiënter kan volgen door de aandacht te concentreren op rivieroevers en door te leren zowel van zorgvuldig gelabelde voorbeelden als van de enorme voorraad niet-gelabelde beelden. Dit vermindert de handmatige inspanning van experts en levert rivierkaarten op met minder onderbrekingen, scherpere randen en minder verwisselingen met wegen of schaduwen. Hoewel ontwikkeld voor rivieren, kan hetzelfde idee — slimme bemonstering plus semi-gesuperviseerd leren — helpen bij het automatisch in kaart brengen van andere smalle kenmerken zoals wegen en kanalen, waardoor grootschalige milieuobservatie nauwkeuriger en betaalbaarder wordt.
Bronvermelding: Wang, K., Han, L. & Li, L. River extraction from high-resolution remote sensing images based on non-uniform sampling and semi-supervised learning. Sci Rep 16, 6816 (2026). https://doi.org/10.1038/s41598-026-38167-6
Trefwoorden: rivieren in kaart brengen, remote sensing, deep learning, semi-gesuperviseerd leren, satellietbeelden