Clear Sky Science · nl
Efficiënte berekening en ontwerp van een hogesnelheids double-precision Vedic-multiplierarchitectuur
Waarom sneller rekenen ertoe doet
Elke keer dat u een video streamt, navigatie op uw telefoon gebruikt of een AI-systeem medische beelden laat analyseren, voert gespecialiseerde computerhardware stilletjes miljarden kleine berekeningen per seconde uit. Een groot deel van die bewerkingen zijn vermenigvuldigingen met "drijvende-komma"-getallen, de standaardmanier waarop computers reële waarden zoals 3,14159 representeren. Dit artikel onderzoekt een slimmere manier om een van die kerncomponenten te bouwen: een hogesnelheids-, energie-efficiënte vermenigvuldiger die put uit ideeën uit de oude Vedic-wiskunde om moderne digitale hardware te verbeteren.
Van oude rekentrucs naar moderne chips
Drijvende-komma rekenkunde vormt de basis van digitale signaalverwerking, beeldverwerking, communicatie en acceleratoren voor deep learning. Standaardvermenigvuldigers moeten brede binaire woorden aankunnen—64 bits voor double precision—en dat snel doen zonder onnodige chipruimte of energie te verspillen. Traditionele benaderingen, zoals Booth-, Karatsuba- en array-vermenigvuldigers, balanceren afwegingen tussen snelheid, hardwaregrootte en ontwerpcomplexiteit. Vedic-wiskunde, een systeem van 16 klassieke rekenregels ontwikkeld in India, bevat een vermenigvuldigingsmethode genaamd Urdhva Tiryakbhyam, of "verticaal en kruisgewijs." Deze methode vormt partiële producten op een sterk parallelle manier, wat het aantal tussentijdse stappen en de benodigde hardware kan verminderen. Onderzoekers hebben deze ideeën recentelijk aangepast voor digitale schakelingen, maar bestaande ontwerpen brengen nog steeds overhead met zich mee bij gebruik voor double-precision drijvende-komma bewerkingen.
Wat deze nieuwe vermenigvuldiger bijzonder maakt
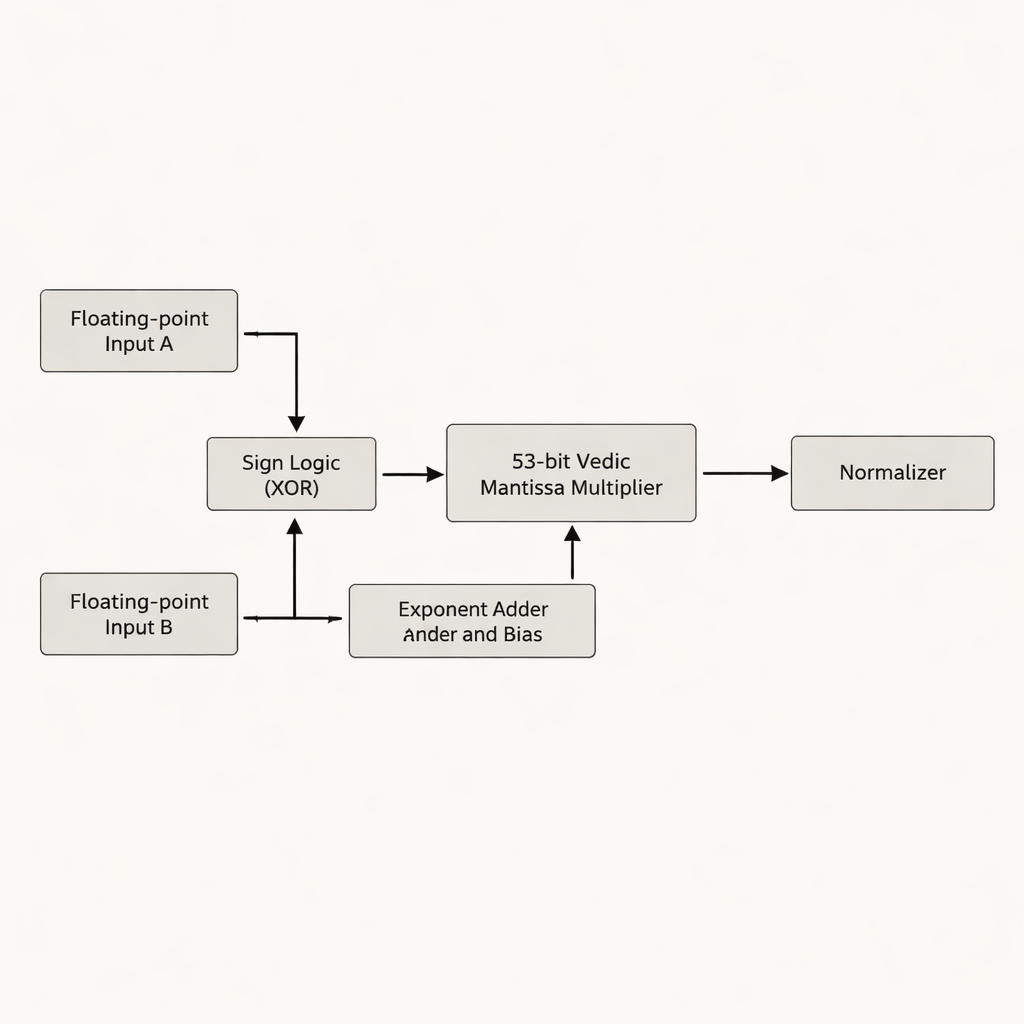
De auteurs stellen een double-precision drijvende-komma vermenigvuldiger voor die zich richt op de mantisse—het deel van een drijvende-komma getal dat het grootste deel van de significante cijfers bevat. In plaats van de 52-bit mantisse op te vullen tot 54 bits, zoals veel eerdere ontwerpen doen, werken ze met de werkelijke 53-bit effectieve mantisse en vermijden ze verspilde "witte ruimte"-bits die extra opslag en bedrading op een chip vergen. Het hart van het ontwerp is een 53-bit Vedic-vermenigvuldiger gebaseerd op Urdhva Tiryakbhyam, gerangschikt in een hiërarchie van kleinere bouwblokken: 3-bit eenheden vormen 6-bit eenheden, die 12-bit, 13-bit, 26-bit en 52-bit eenheden opbouwen, die samenkomen in de uiteindelijke 53-bit fase. De architectuur splitst het werk in drie hoofdphases—tekenberekening, exponentoptelling en bias-correctie, en mantissevermenigvuldiging gevolgd door normalisatie—wat overeenkomt met de IEEE-754 drijvende-komma standaard terwijl overbodige schakeling wordt teruggesnoeid.
Priem-grootte bouwblokken voor schonere hardware
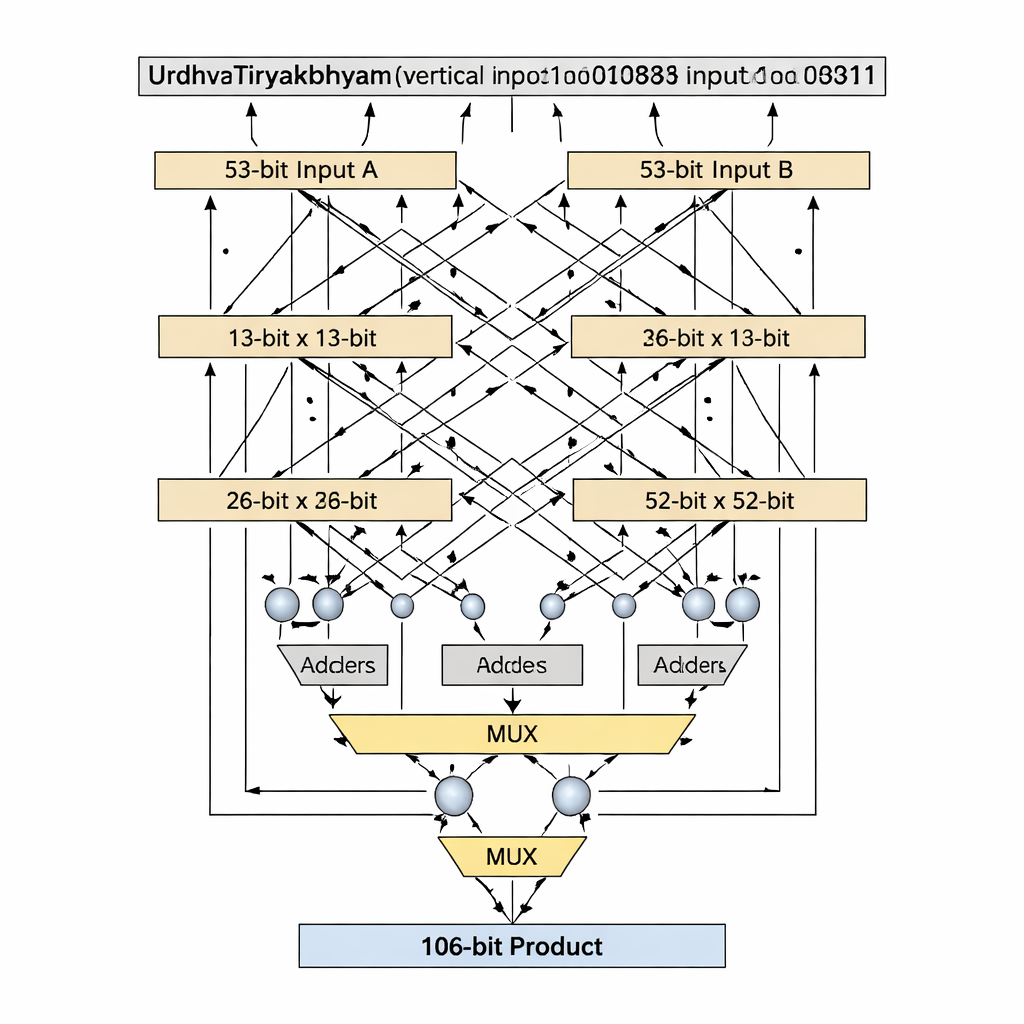
Een belangrijke innovatie is hoe het ontwerp omgaat met bitbreedtes die priemgetallen zijn, zoals 13 en 53, die niet netjes in gelijkwaardige blokken te verdelen zijn. Standaard Vedic-decomposities veronderstellen gelijk verdeelde inputs, maar dat wordt onhandig of verspild voor priemlengtes. De auteurs introduceren een "priem-bit" algoritme dat slim een kleiner (n−1)-bit Vedic-vermenigvuldiger hergebruikt, plus adders, multiplexers en één extra logische poort, om een n-bit vermenigvuldiger te emuleren zonder opvulling. Voor de 13‑bit fase worden de inputs opgesplitst in 1-bit en 12-bit secties; partiële producten worden gemaakt met een 12-bit Vedic-vermenigvuldiger, voorwaardelijke selectie (via multiplexers) op basis van de meest significante bits, en een klein aantal adders. Hetzelfde patroon schaalt naar 53 bits met een 52-bit kern. Deze op maat gemaakte decompositie verkort het kritieke pad—de langste keten van logica die een signaal moet doorlopen—terwijl het aantal logische elementen laag blijft.
Gemeten winst in snelheid, omvang en vermogen
Het ontwerp werd beschreven in Verilog hardwarebeschrijvingstaal en geïmplementeerd op een Xilinx Zynq field-programmable gate array (FPGA) met Vivado-tools. Over 13-, 26-, 52-, 53- en 64-bit Vedic-vermenigvuldigers toont de voorgestelde 53-bit eenheid een gunstige balans van vertraging, logica-gebruik (lookup tables en I/O-pinnen) en geschat vermogen. In vergelijking met eerdere double-precision vermenigvuldigers gebaseerd op Booth, Karatsuba en andere Vedic-opstellingen vermindert de nieuwe architectuur de worst-case vertraging en de benodigde FPGA-resources aanzienlijk, zonder extra complexiteit toe te voegen aan de omliggende drijvende-komma schakeling. Omdat de mantissevermenigvuldiging sneller is en de logische diepte ondieper, neemt de switching-activiteit af, wat wijst op een beter power–delay product hoewel directe technologie-overschrijdende vermogensvergelijkingen moeilijk te maken zijn.
Invloed op AI en signaalverwerking
Om het ontwerp in een echte werklast te testen, integreerden de auteurs hun Vedic double-precision vermenigvuldiger in de convolutionele motor van een Convolutional Neural Network, waar multiply-and-accumulate bewerkingen de looptijd domineren. Het vervangen van conventionele IEEE-754 en eerdere Vedic-vermenigvuldigers door het nieuwe ontwerp verkortte de convolutievertraging, verminderde het energieverbruik en verlaagde de inferentietijd, terwijl dezelfde classificatienauwkeurigheid behouden bleef. Vergelijkbare voordelen worden verwacht bij andere rekentheavy taken, zoals digitale filtering, randdetectie en medische beeldverwerkingspijplijnen, waar snellere vermenigvuldigers direct de doorvoer verhogen en apparaten koeler of op kleinere batterijen kunnen laten werken.
Wat dit betekent voor alledaagse technologie
In eenvoudige bewoordingen laat het artikel zien dat het lenen van een slimme vermenigvuldigingsmethode uit de Vedic-wiskunde en het zorgvuldig afstemmen op moderne binaire formaten kan resulteren in een vermenigvuldiger die kleiner, sneller en energie-efficiënter is dan standaardontwerpen. Dit verbeterde bouwblok kan worden ingebouwd in processors, signaalverwerkingschips en AI-acceleratoren, wat leidt tot snellere data-analyse, responsievere apparaten en mogelijk lager energieverbruik in systemen variërend van smartphones tot medische scanners. De auteurs schetsen ook toekomstige richtingen, waaronder reversibele logica voor nog lager energieverbruik en integratie in grotere verwerkingsunits, wat suggereert dat dit huwelijk van oude rekenkunst en moderne hardware nog maar net begonnen is.
Bronvermelding: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Trefwoorden: Vedic-multiplier, drijvende-komma rekenkunde, FPGA-ontwerp, digitale signaalverwerking, convolutionele neurale netwerken