Clear Sky Science · nl
Toepassing van zwermgebaseerde diepe neurale netwerken en ensemblemodellen voor reconstructie van specific conductance-gegevens
Waarom het vullen van datalekken ertoe doet
Kustwateren vormen de voorpost waar menselijke activiteiten de oceaan ontmoeten. Wetenschappers volgen de zoutheid van deze wateren met een maatstaf genaamd specific conductance, die helpt bij het blootleggen van verontreinigingslekken, veranderingen in zoetwatertoevoer en langetermijnmilieuverschuivingen. Maar sensoren falen, stormen vallen spanningsnetten uit en instrumenten hebben beperkingen. Het resultaat zijn frustrerende gaten in cruciale reeksen—juist wanneer beheerders en onderzoekers continue data het hardst nodig hebben. Deze studie stelt een praktische vraag: kan moderne kunstmatige intelligentie die gebroken reeksen betrouwbaar "repareren" zodat kustbeslissingen gebaseerd zijn op volledige, betrouwbare informatie?
De golf zien ademen
De onderzoekers richtten zich op de Golf van Mexico, een van ’s werelds grootste mariene ecosystemen en een regio onder zware industriële en agrarische druk. Ze gebruikten metingen van vijf US Geological Survey-stations in de buurt van de Pascagoula-rivier en Mullet Lake, elk met een opname van de zoutheid (via specific conductance), temperatuur en waterstand elke 15 minuten. Eén station, aangeduid als E, miste ongeveer 5% van zijn specific conductance-gegevens—precies het soort probleem dat echte meetnetwerken tegenkomen. Gegevens van de vier naburige stations vormden een soort omgevingsveiligheidsnet: zelfs wanneer station E blind werd, bleven de anderen observeren. Het centrale idee was computersystemen te leren hoe alle vijf stations gezamenlijk "ademen", zodat gaten op één locatie kunnen worden afgeleid van volledige reeksen bij de andere stations.
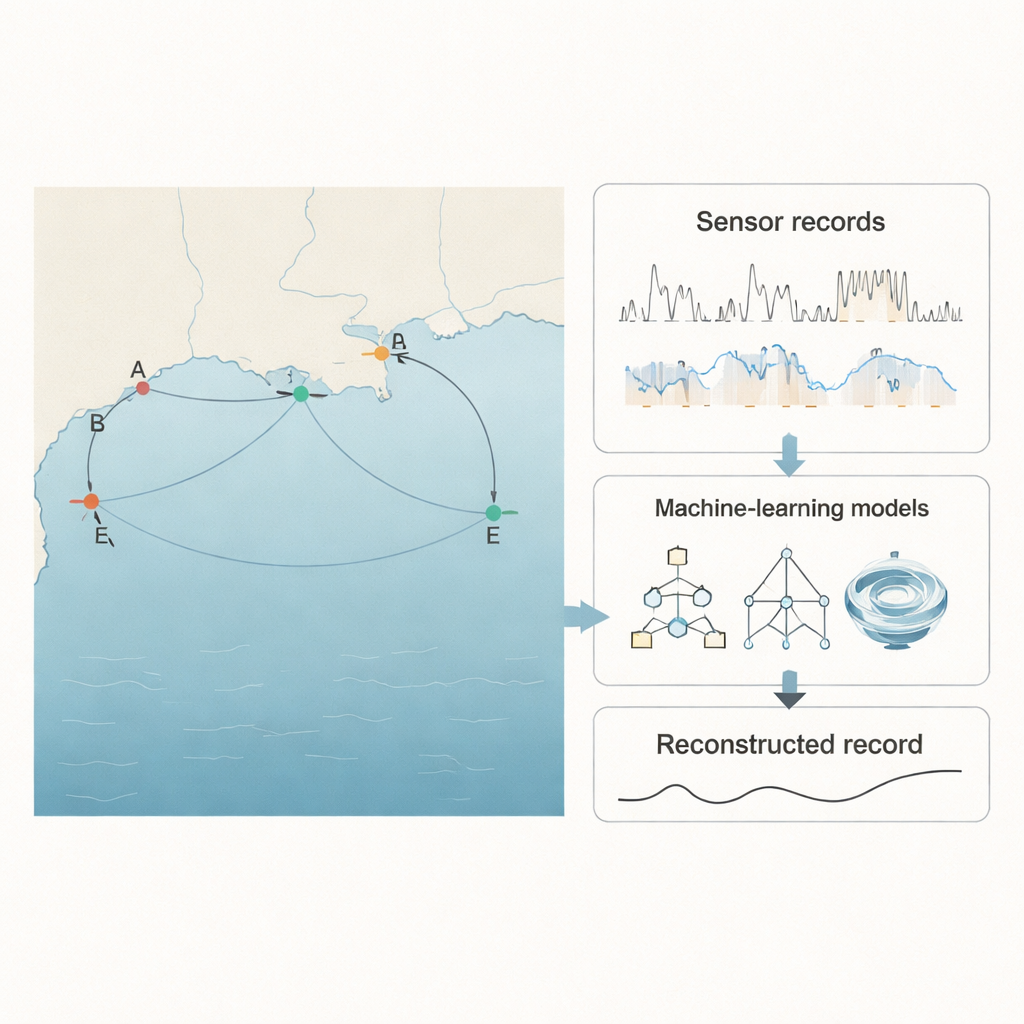
Slimme algoritmen aan de tand voelen
Om dit aan te pakken stelde het team een line‑up van tien verschillende modelleerbenaderingen samen. Aan de ene kant stonden vertrouwde hulpmiddelen zoals meervoudige lineaire regressie, die proberen rechte lijnrelaties tussen invoer en uitvoer te leggen. In het midden stonden flexibelere modellen zoals klassieke neurale netwerken, fuzzy-logicasystemen en een speciale long short-term memory (LSTM)-netwerk dat vaak voor tijdreeksen wordt gebruikt. Ze gebruikten ook een zelforganiserende methode genaamd group method of data handling (GMDH) en een niet-lineaire variant (NGMDH) die zelf meerlagige formules kan opbouwen. Ten slotte brachten ze boomgebaseerde methoden in: een enkel beslissingsboommodel (CART) en twee "ensemble"-benaderingen—Random Forest en XGBoost—die vele bomen combineren om tot een eindbeslissing te komen, vergelijkbaar met een panel van experts die over een antwoord stemmen.
Zwermgestuurde diepe leeroplossingen
Het trainen van diepe neurale netwerken is berucht lastig: hun vele knoppen en schakelaars kunnen gemakkelijk in suboptimale configuraties vastlopen. Om ze te verbeteren koppelden de auteurs LSTM en NGMDH aan een recent optimalisatiemechanisme geïnspireerd op ronzend water, genaamd turbulent flow of water-based optimization (TFWO). In dit schema wordt elke mogelijke set modelparameters voorgesteld als een "deeltje" dat in een draaikolkachtig patroon door de oplossingsruimte beweegt. Over vele cycli worden de deeltjes richting regio’s gestuurd die kleinere voorspelfouten opleveren. Deze zwermachtige zoektocht maakte beide netwerktopologieën merkbaar nauwkeuriger dan hun standaardversies, met een vermindering van de gemiddelde fouten van ongeveer 6–11 procent. Toch werden zelfs deze verbeterde diepe modellen uiteindelijk voorbijgestreefd door de boomgebaseerde benaderingen.
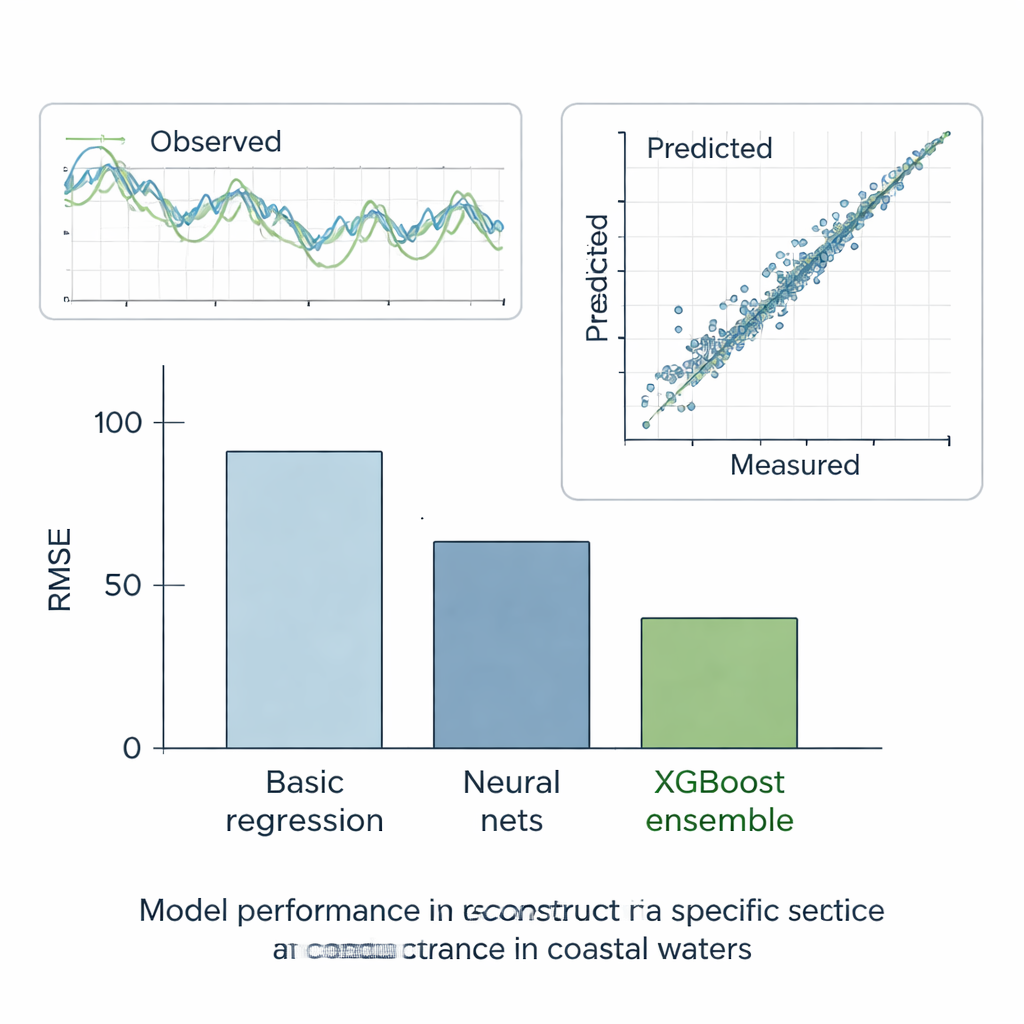
Ensembles pakken de leiding
De auteurs testten alle methoden rigoureus in zes scenario’s. In vijf "wat‑als"-gevallen verborgen ze stukken van anders volledige reeksen en controleerden hoe goed elk model de ontbrekende waarden kon reconstrueren. In het laatste, reële geval vroegen ze de modellen om de echte hiaten bij station E op te vullen met behulp van gegevens van de buren. Over deze tests presteerde de eenvoudigste rechte‐lijnmethode het slechtst, terwijl standaard machine‑learningmodellen veel beter deden en de fout ongeveer halveerden. Beslissingsbomen, die data automatisch in meer uniforme groepen splitsen, leverden verdere verbetering. Maar de duidelijke winnaar was het ensemble XGBoost: door honderden bomen te bouwen die elk de fouten van de vorige corrigeren, bereikte het een extreem lage fout en een bijna perfecte overeenkomst tussen voorspelde en gemeten specific conductance. De reconstructies volgden de waargenomen tijdreeksen nauwkeurig en reproduceerden het algemene statistische gedrag van de waterkwaliteitsreeksen.
Wat dit betekent voor kusten en verder
Voor niet‑specialisten is de kernboodschap eenvoudig: zorgvuldig ontworpen AI kan betrouwbaar ontbrekende delen van kustwaterkwaliteitsreeksen invullen, vooral wanneer nabijgelegen stations context bieden. Hoewel geavanceerde neurale netwerken krachtig zijn, toont deze studie aan dat boomgebaseerde ensemblemethoden zoals XGBoost nog nauwkeuriger zijn en in de praktijk waarschijnlijk de beste keuze vormen om milieugegevenssets te repareren. Met robuuste gap‑filling‑hulpmiddelen kunnen wetenschappers subtiele veranderingen in kustzoutheid beter volgen, verontreinigingsevenementen identificeren en beheerbeslissingen ondersteunen zonder gehinderd te worden door onvermijdelijke sensorstoringen. Dezelfde strategieën zijn aanpasbaar aan veel andere technische en milieuvraagstukken waarbij datastromen rijk, ruisig en af en toe incompleet zijn.
Bronvermelding: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Trefwoorden: kwaliteit van kustwateren, specific conductance, machine learning, reconstructie van ontbrekende gegevens, XGBoost