Clear Sky Science · nl
Een nieuw stacking-ensemblemodel voor het voorspellen van de loefactor van ondergedompelde meervoudig parallelle radiale schuiven
Waarom slimmer gemaakte waterlopen ertoe doen
Op irrigatielandbouwgebieden bepalen metalen schuiven in kanalen stilletjes wie wanneer water krijgt. Zelfs een kleine onjuistheid in de afstelling kan ertoe leiden dat sommige percelen te veel water krijgen terwijl anderen droogvallen, waardoor een schaarse hulpbron wordt verspild en gewassen schade oplopen. Deze studie pakt dat verborgen probleem aan door geavanceerde computerleer-technieken te gebruiken om de doorstroming door deze schuiven eenvoudiger en veel nauwkeuriger te voorspellen, zonder te vertrouwen op ingewikkelde formules of trial-and-error in het veld.
Verborgen uitdaging binnen kanaalschuiven
Moderne irrigatienetwerken vertrouwen sterk op zogenaamde radiale schuiven, gebogen stalen deuren die omhoog of omlaag worden bewogen om te regelen hoeveel water stroomt. Onder veel reële omstandigheden werken deze schuiven terwijl ze "ondergedompeld" zijn — dat wil zeggen dat het water zowel aan de bovenstroom- als aan de benedenstroomzijde hoog staat. In die situatie bepaalt een cruciale grootheid, de loefactor (discharge coefficient), hoeveel water daadwerkelijk onder een deels geopende schuif doorstroomt. Traditionele methoden om deze factor te berekenen zijn complex, berusten op veel aannames en kunnen tientallen procenten fout zitten wanneer de schuif ondergedompeld is. Voor ingenieurs en waterbeheerders vertalen deze onnauwkeurigheden zich direct naar slechte regeling van leveringen aan boerderijen.
Een model leren van werkelijke rivierdata
De onderzoekers wendden zich tot machine learning, waardoor computers patronen rechtstreeks uit metingen kunnen leren in plaats van alleen op handgemaakte formules te vertrouwen. Ze verzamelden 782 datapunten van drie grote regelinrichtingen in de Nijldelta in Egypte, elk met meerdere gebogen schuiven die honderden duizenden hectares bedienen. Voor elke bedrijfsconditie registreerden ze boven- en benedenstrooms waterniveaus, schuifopening en geometrie, en de resulterende stroming. Deze waarden werden omgezet in eenvoudige verhoudingen — bijvoorbeeld hoe diep het water benedenstrooms is ten opzichte van bovenstrooms — zodat het model zich op de meest invloedrijke aspecten van het schuifgedrag kon richten. Eerder werk had al aangetoond dat de verhouding van beneden- naar bovenstrooms waterdiepte bijzonder belangrijk is, en deze nieuwe analyse bevestigde dat dit de krachtigste enkele voorspeller van de loefactor is.
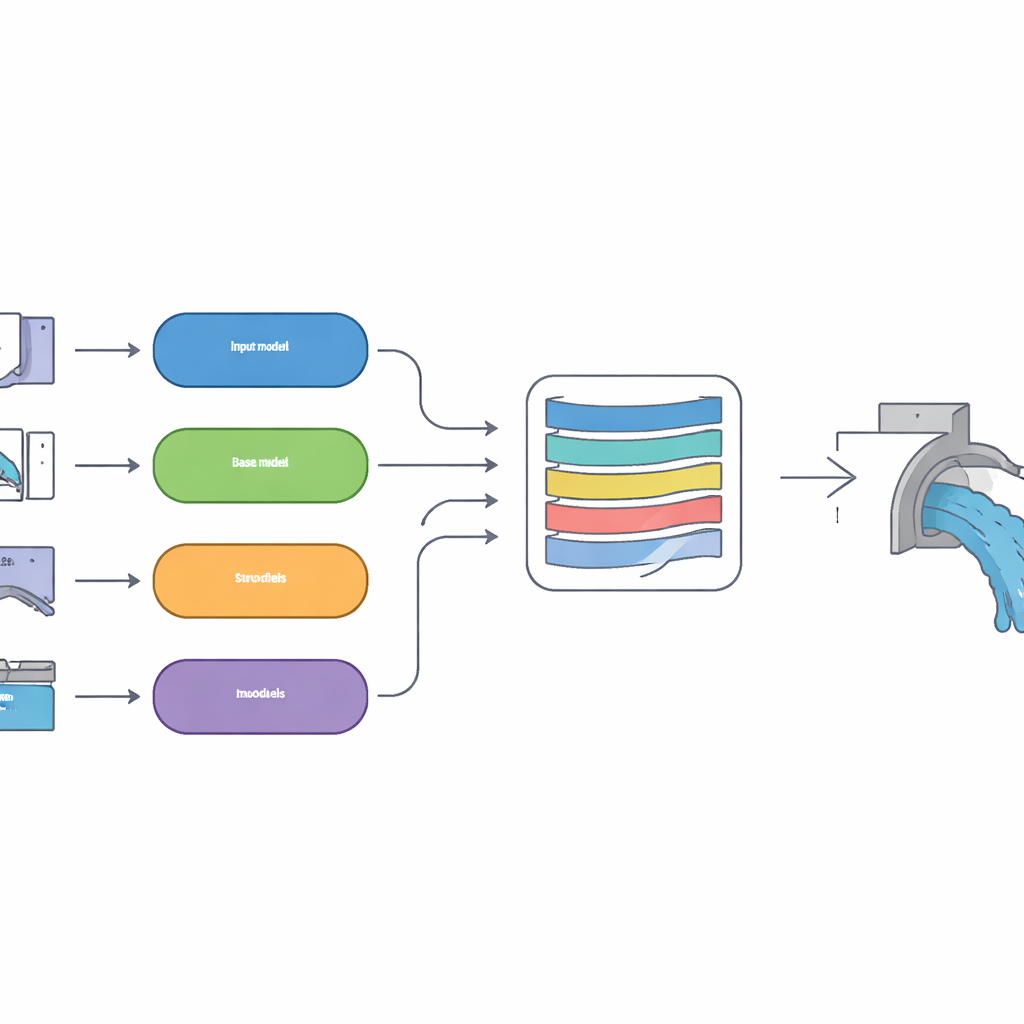
Veeldenkendheid, één eindantwoord
In plaats van te wedden op één leermethode bouwde het team een "stacking"-benadering die meerdere verschillende voorspellingsinstrumenten combineert. Vier basismodellen, elk met een andere stijl van patroonherkenning, produceren eerst hun eigen schattingen van de loefactor. Dit omvat methoden die goed zijn in het uitdrukken van onzekerheid, methoden die goed omgaan met complexe krommen en methoden die subtiele relaties herkennen. Hun uitkomsten worden vervolgens gevoed aan een hoger niveau deep learning-model, een long short-term memory-netwerk dat is uitgerust met een aandachtmechanisme. Deze bovenlaag leert hoeveel vertrouwen ze aan elk basismodel moet schenken onder verschillende stromingscondities, vergelijkbaar met een ervaren ingenieur die meerdere expertmeningen weegt voordat hij een definitieve waarde kiest.
Hoe goed werkt het?
Het gecombineerde systeem is getraind en getest met zorgvuldige cross-validatie, waarbij de data herhaaldelijk in aparte leergroepen en controlegroepen worden opgesplitst om overfitting te voorkomen. In deze tests produceerde het ensemblemodel consequent loefactoren die uitzonderlijk goed overeenkwamen met veldmetingen. De typische fout was slechts enkele procenten, en het overtrof elk afzonderlijk basismodel evenals meerdere veelgebruikte traditionele regressietechnieken. Visuele vergelijkingen toonden dat de voorspellingen van het model vrijwel exact op de ideale één-op-één-lijn met de geobserveerde waarden lagen, wat aangeeft dat het nauwkeurig bleef over het volledige bereik van bedrijfscondities dat in de kanalen werd waargenomen.
Wat dit betekent voor echte kanalen
Voor niet-specialisten is de praktische conclusie simpel: door meerdere leermethoden te laten "stemmen" en vervolgens een slimme eindbeslisser te leren hoe deze stemmen te wegen, kunnen ingenieurs met hoge betrouwbaarheid voorspellen hoeveel water door ondergedompelde radiale schuiven stroomt. Omdat de vereiste invoer slechts waterstanden, schuifopeningen en vaste schuifafmetingen zijn — waarden die in de meeste geautomatiseerde kanalenystemen al worden gemeten — kan de methode worden geïntegreerd in bestaande besturingssoftware als een besluitondersteunend instrument. Juist toegepast binnen het bereik van omstandigheden waarop het getraind is, kan dit soort intelligent ensemblemodel irrigatieautoriteiten helpen water eerlijker te verdelen, verspilling te verminderen en zelfverzekerder te reageren op veranderende vraag en klimaatgedreven druk op rivieren.
Bronvermelding: Abdelazim, N.M., Hosny, M., Abdelhaleem, F.S. et al. A novel stacking ensemble model for predicting discharge coefficient of submerged multi parallel radial gates. Sci Rep 16, 7953 (2026). https://doi.org/10.1038/s41598-026-38117-2
Trefwoorden: irrigatiekanalen, radiale schuiven, machine learning, waterbeheer, debietvoorspelling