Clear Sky Science · nl
De constructie en verfijnde extractietechnieken van een kenniskader op basis van grote taalmodellen
Slimmere kaarten voor complexe beslissingen
Moderne beslissingen in risicovolle domeinen — zoals grootschalige operaties, beheer van infrastructuur of rampenrespons — hangen af van het snel begrijpen van enorme hoeveelheden verspreide informatie. Handleidingen, sensorgegevens, rapporten en simulaties vertellen allemaal een deel van het verhaal, maar ze zijn zelden georganiseerd op een manier die mensen of computers gemakkelijk kunnen gebruiken. Dit artikel presenteert een methode om die gefragmenteerde informatie om te zetten in levende "kenniskaarten" aangedreven door grote taalmodellen, zodat planners en analisten betere vragen kunnen stellen en sneller en betrouwbaarder antwoorden krijgen.
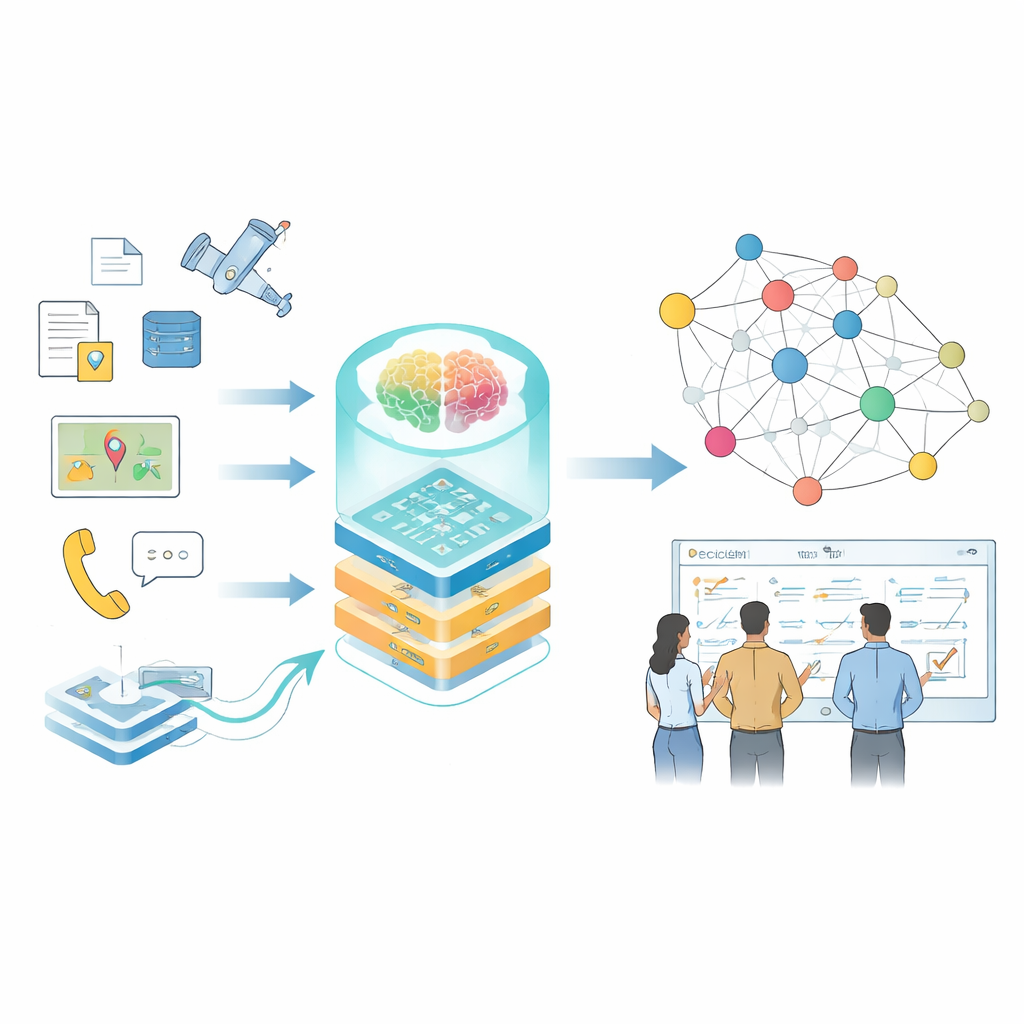
Van verspreide feiten naar verbonden kennis
De auteurs richten zich op kennisgrafieken, een manier om informatie te representeren als een web van verbonden feiten — wie wat deed, met welk systeem, onder welke omstandigheden. In alledaagse toepassingen voeden dergelijke grafieken al zoekmachines en aanbevelingssystemen, maar gespecialiseerde domeinen stellen zwaardere eisen: data is gevoelig, terminologie is complex, formaten variëren van vrijetekstrapporten tot sensorlogboeken, en omstandigheden veranderen snel. Traditionele hulpmiddelen die vertrouwen op handgeschreven regels of kleine modellen hebben moeite om bij te blijven, en algemene taalmodellen interpreteren technische termen vaak verkeerd of missen subtiele relaties die van belang zijn voor beslissingen in de praktijk.
Een nieuwe specialiteit aanleren aan grote taalmodellen
Om dit aan te pakken, finetunen de onderzoekers een krachtig basis-taalmodel op een zorgvuldig ontworpen, domeinspecifieke dataset. De dataset put uit commandocommunicatie, apparaathandleidingen, gesimuleerde scenario’s en vakliteratuur. Voordat dit materiaal het model bereikt, wordt het grondig gedesensibiliseerd: concrete coördinaten worden relatieve locaties, eenheidsnamen veranderen in generieke codes, en gevoelige logica wordt gedeeltelijk gemaskeerd terwijl de algemene patronen behouden blijven. De gegevens worden opgeslagen in een gestructureerd formaat dat de bredere situatie beschrijft, de specifieke taken (zoals planning, dreigingsrangschikking of vraagbeantwoording) en de verbanden daartussen. Deze structuur laat het model niet alleen geïsoleerde feiten leren, maar ook hoe verschillende taken context delen.
Adaptatielagen voor verschillende taken
In plaats van elke parameter van het taalmodel opnieuw te trainen — een kostbaar en risicovol proces — gebruiken de auteurs een techniek genaamd low-rank adaptation, georganiseerd in meerdere lagen die elk op een ander aspect van het probleem focussen. De ene laag legt basisterminologie en -concepten vast, een andere embed operational regels en beperkingen, en een derde specialiseert zich in het aanpassen aan specifieke taken, zoals planning of dreigingsanalyses. Een aparte controlecomponent, het "routing"-netwerk, bekijkt elk invoerstuk en beslist welke combinatie van deze lichte adapters het model moet gebruiken. Dit ontwerp stelt het systeem in staat efficiënt tussen taken te wisselen terwijl zowel algemene taalvaardigheid als domeinspecifieke expertise behouden blijven.
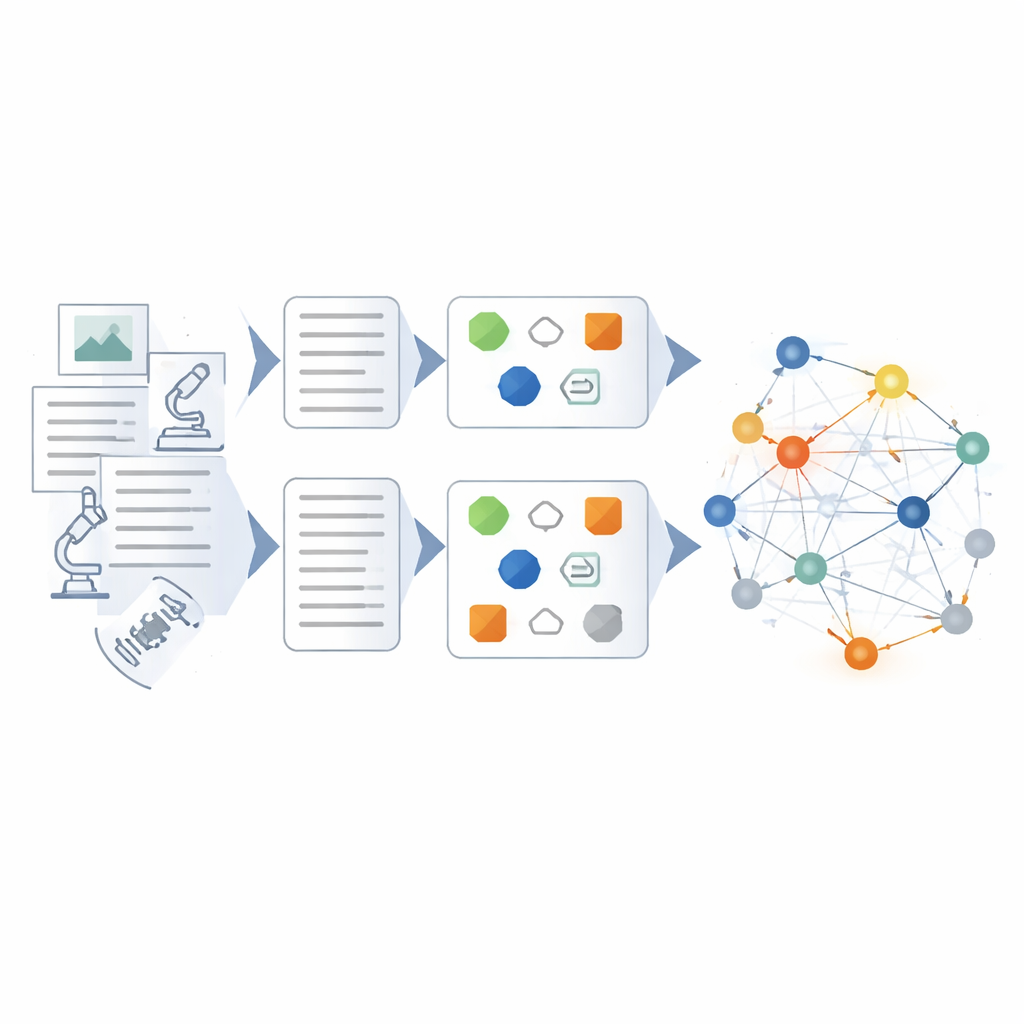
Het kennisknooppunt bouwen en controleren
Bovenop het getunede model ontwerpen de auteurs een hybride pijplijn voor het bouwen van de kennisgrafiek zelf. Eerst worden ruwe gegevens opgeschoond en gestandaardiseerd zodat termen en formaten consistent zijn. Vervolgens halen regelgebaseerde methoden en door experts gemaakte sjablonen duidelijke entiteiten en gebeurtenissen eruit. Het gefinetunede taalmodel komt in actie voor complexere taken: rommelige rapporten inkorten tot beknopte samenvattingen, sleutelspelers en apparatuur identificeren, en relaties afleiden zoals oorzaak-gevolgketens of coördinatie tussen eenheden. Elk geëxtraheerd feit wordt vanuit meerdere invalshoeken gescoord — hoe goed het past bij bekende patronen, hoe sterk het verbonden is met andere feiten, en of het overeenkomt met multi-stappaden van redenering door de grafiek. Alleen resultaten met hoge confidentie worden toegevoegd, en laaggekwalificeerde resultaten worden gemarkeerd voor beoordeling.
Bewezen winst in nauwkeurigheid en betrouwbaarheid
Het team evalueert hun benadering op drie kerntaken die echte behoeften weerspiegelen: complexe vragen beantwoorden over regels en uitrusting, actieplannen voorstellen voor gegeven situaties, en verschillende dreigscenario’s rangschikken op ernst. Over deze taken heen presteert het aangepaste model consequent beter dan bekende algemene systemen, inclusief toonaangevende modellen met veel meer generieke training. Het beantwoordt meer vragen correct, genereert realistischere plannen en rangschikt dreigingen accurater. De resulterende kennisgrafiek is zowel groot als sterk verbonden, met meer dan 90 procent van de opgeslagen feiten die strenge confidentiecontroles doorstaan en planners helpen sneller tot goede beslissingen te komen.
Waarom dit er in de toekomst toe doet
Voor een niet‑specialist is de kernboodschap dat taalmodellen van gladde woordvoerders in zorgvuldige, gespecialiseerde analisten kunnen worden omgevormd — als ze op de juiste data worden getraind, beperkt worden door duidelijke regels en continu op kwaliteit worden gecontroleerd. Dit werk toont hoe dat kan in een gevoelig, snel veranderend domein terwijl privégegevens worden beschermd. Het raamwerk organiseert niet alleen verspreide kennis in een bruikbaar web, maar houdt dat web ook actueel en betrouwbaar, en biedt een blauwdruk voor toekomstige besluitvormingssystemen in elk veld waar het juist nemen van complexe beslissingen echt van levensbelang is.
Bronvermelding: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Trefwoorden: kennisgrafiek, groot taalmodel, besluitvorming, domeinaanpassing, gegevensdesensitisatie