Clear Sky Science · nl
Genereren van grensgeval‑testmonsters voor willekeurigheidstesters via intelligente optimalisatie en evolutionaire algoritmen
Waarom bijna‑willekeurigheid van belang is voor alledaagse beveiliging
Iedermaal wanneer u online winkelt, uw telefoon ontgrendelt of een privébericht verstuurt, worden onzichtbare wiskundige dobbelstenen geworpen om uw gegevens te beschermen. Die dobbelstenen verschijnen als lange reeksen zogenaamd willekeurige bits die als cryptografische sleutels worden gebruikt. Als die bits ook maar iets minder willekeurig zijn dan ze zouden moeten zijn, kunnen vastberaden aanvallers soms patronen vinden om te misbruiken. Dit artikel onderzoekt een nieuwe manier om “bijna‑willekeurige” testreeksen te vervaardigen — gegevens die extreem willekeurig lijken maar kleine gebreken verbergen — zodat ingenieurs de apparaten die ons digitale leven beschermen grondig kunnen stress‑testen.
Wanneer willekeurige getallen niet helemaal willekeurig genoeg zijn
Moderne beveiligingssystemen vertrouwen op twee soorten willekeurige getalgeneratoren. Echte willekeurige generatoren putten uit onvoorspelbare fysieke effecten, zoals elektronische ruis of kwantumfluctuaties, terwijl pseudo‑willekeurige generatoren algoritmen gebruiken die korte, toevallige zaden omzetten in lange reeksen. In de praktijk hangt de kwaliteit van beide uiteindelijk af van de fysieke bron van onvoorspelbaarheid, de zogenaamde entropiebron. Helaas zijn entropiebronnen in de echte wereld kwetsbaar: temperatuurschommelingen, veroudering van hardware of ontwerpfouten kunnen hun willekeur in stilte verminderen. Om dergelijke problemen te detecteren, definiëren standaardiseringsinstanties zoals NIST batterijen van statistische tests die controleren of de uitgevoerde bits willekeurig genoeg lijken. Apparaten bevatten steeds vaker “real‑time willekeurigheidstesters” die hun eigen output tijdens werking monitoren. Toch bestond er geen goede manier om realistische, moeilijk te detecteren faalgevallen te genereren om te testen of die ingebedde controlesystemen daadwerkelijk werken.
Ontwerpen van reeksen die net niet door willekeurigheidstests komen
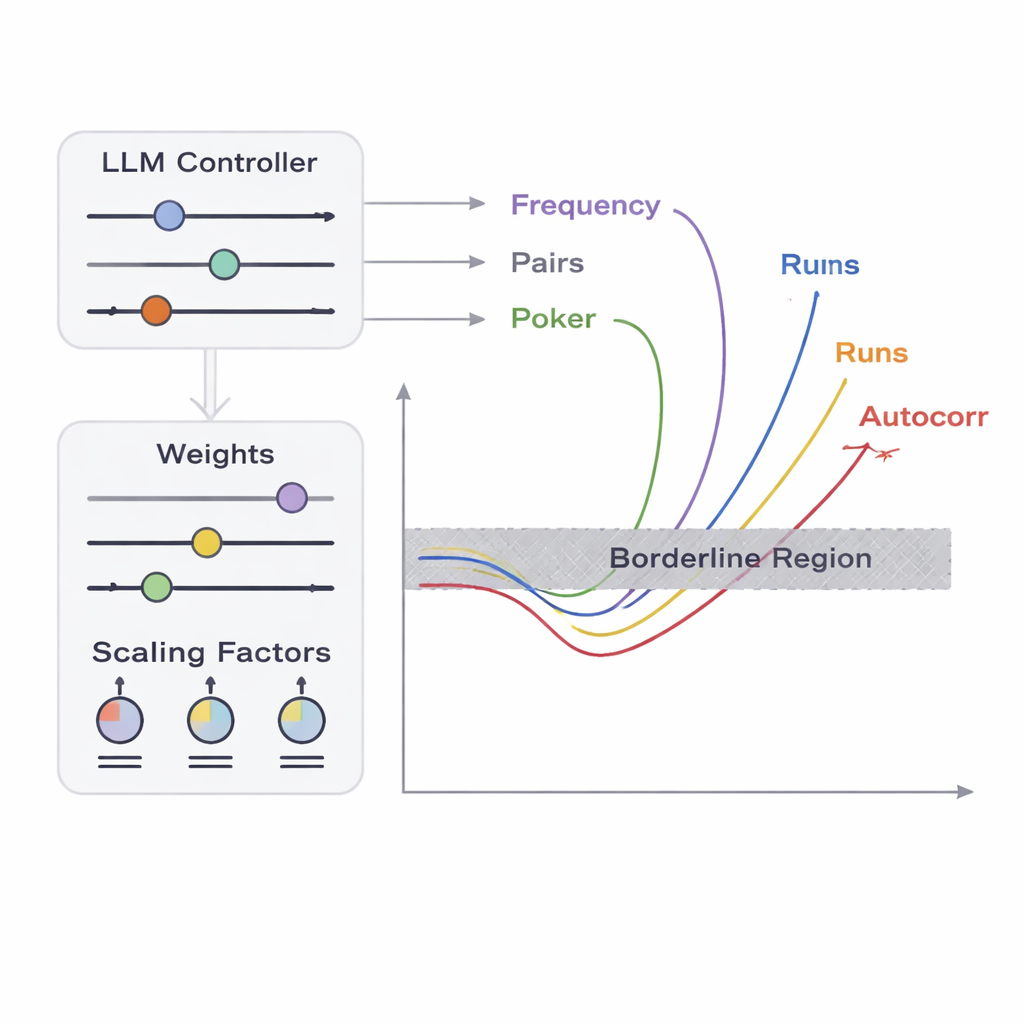
Vanuit het perspectief van een tester zijn triviale fouten — zoals uitvoer die uitsluitend uit nullen bestaat — gemakkelijk te ontdekken. De echte uitdaging is het opsporen van grensgevallen: reeksen die bijna niet te onderscheiden zijn van ideale willekeurigheid maar net één of meer statistische controles niet halen. De auteurs richten zich op vijf klassieke tests die naar verschillende aspecten van bitpatronen kijken, waaronder hoe vaak nullen en enen voorkomen, hoe bittparen zich gedragen, hoe bepaalde korte patronen verdeeld zijn, hoe bits correleren met verschoven kopieën van zichzelf, en hoe de lengtes van runs van identieke bits zijn gerangschikt. Ze definiëren een “grenszone” voor elke test: een smal bereik waarbij de data slechts lichtelijk de gebruikelijke acceptatiedrempels overschrijdt. Het produceren van een lange reeks die zich gelijktijdig binnen al deze smalle zones bevindt is extreem onwaarschijnlijk bij toeval, omdat de tests op ingewikkelde, niet‑lineaire manieren met elkaar interacteren. Hier komen optimalisatie en AI in beeld.
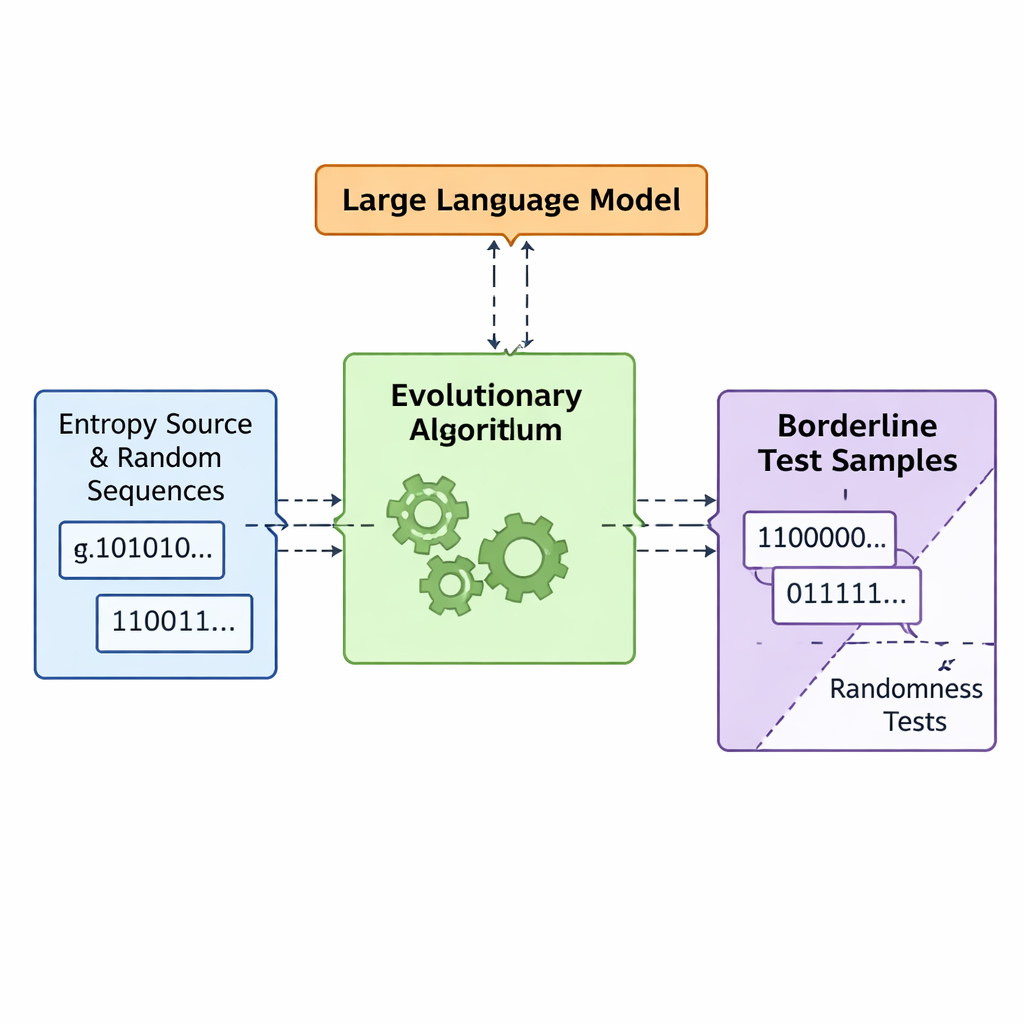
Laat evolutie en taalmodellen samen slechte willekeur ontwerpen
Het team introduceert een kader genaamd APAM‑IGLLM dat sequentiegeneratie behandelt als een hoge‑dimensionaal optimalisatieprobleem. Elke kandidaat‑reeks is een bitstring en de “fitheid” meet hoe dicht deze bij de grenszones van de vijf tests komt. Een genetisch algoritme muteert en recombineert deze reeksen herhaaldelijk en behoudt diegene die dichter naar het doelgebied bewegen. Daarbovenop fungeert een groot taalmodel (LLM) als een soort strategisch coach. In elke generatie onderzoekt het samenvattende statistieken van de populatie en de korte‑termijngeschiedenis, en stelt vervolgens voor hoe interne knoppen moeten worden aangepast — gewichten en schaalfactoren die bepalen hoe sterk elke test de fitheid beïnvloedt. Dit creëert een feedbacklus: het genetisch algoritme verkent de ruimte van mogelijke reeksen, terwijl het LLM de zoektocht stuurt zodat alle vijf testscores convergeren naar de kleine doorsnede waar reeksen net niet‑willekeurig genoeg zijn.
Hoe dicht bij perfecte willekeur kan gebrekkige data er uitzien?
Om te beoordelen of hun kunstmatige gebreken realistisch overkomen, vergelijken de auteurs hun gegenereerde reeksen met veelgebruikte benchmarks. Ze berekenen zowel Shannon‑entropie als min‑entropie, maatstaven voor hoe onvoorspelbaar elke byte lijkt, en vinden waarden rond 7,6–8 bits per byte — zeer dicht bij het theoretische maximum van 8 en vergelijkbaar met commerciële hardwarebronnen van willekeurigheid en NIST’s eigen publieke randomness beacon. Ze voeren ook de volledige NIST SP 800‑22 statistische testbatterij uit en observeren dat hun grensreeksen slagen en falen in vrijwel hetzelfde patroon als echte, hoogwaardige willekeurige data. Met andere woorden: voor standaardhulpmiddelen zien deze monsters er in wezen normaal uit, hoewel ze bewust zo zijn geconstrueerd dat ze dicht bij meerdere faaldrempels liggen. Dit maakt ze ideale “adversariële” invoer om te controleren hoe robuust ingebedde willekeurigheidstesters werkelijk zijn.
Wat dit betekent voor beveiliging in de praktijk
Voor de leek biedt dit werk een nieuwe manier om de willekeurmachine waarmee versleuteling wordt ondersteund, veilig te testen. In plaats van apparaten alleen te testen met duidelijk gebroken of duidelijk gezonde willekeur, kunnen ingenieurs ze nu bestoken met zorgvuldig vervaardigde, bijna‑goede reeksen die subtiele hardwarefouten of omgevingsafwijkingen nabootsen. Als een real‑time willekeurigheidstester deze grensgevallen mist, duidt dat op een potentieel blinde vlek die vóór inzet in bankieren, beveiligde communicatie of blockchain‑systemen moet worden verholpen. Door evolutionair zoeken te combineren met sturing door een taalmodel bieden de auteurs een praktisch hulpmiddel om dergelijke veeleisende testdata te genereren, waarmee de verborgen fundamenten van digitale beveiliging naar hogere betrouwbaarheidsniveaus worden gebracht.
Bronvermelding: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Trefwoorden: willekeurige getalgeneratoren, entropiebronnen, evolutionaire algoritmen, grote taalmodellen, cryptografische tests