Clear Sky Science · nl
APMSR: een intelligent QA-systeem voor synthetische biologie aangedreven door adaptieve prompting en multi-bron kennisherwinning
Slimmere antwoorden voor een nieuw type biologie
Synthetische biologie belooft schonere brandstoffen, groenere fabrieken en nieuwe medische behandelingen, maar het vakgebied ontwikkelt zich zo snel dat zelfs experts moeite hebben bij te blijven. Deze studie introduceert APMSR, een slim vraag‑en‑antwoordsysteem dat onderzoekers helpt snel betrouwbare antwoorden te vinden over een belangrijke biobrandstofmicrobe, Zymomonas mobilis. Door grote taalmodellen te combineren met zorgvuldig geselecteerde online en offline bronnen, streeft het systeem ernaar precieze, actuele antwoorden te geven in plaats van zelfverzekerde maar onjuiste gissingen.
De uitdaging van goede vragen stellen
Wetenschappers vertrouwen al op zoekmachines en online databases, maar die tools geven vaak lange lijsten met publicaties in plaats van directe antwoorden. Grote taalmodellen (LLM's) kunnen vloeiend over veel onderwerpen praten, maar in snel veranderende velden zoals synthetische biologie missen ze recente ontdekkingen of verzinnen ze soms feiten. De auteurs richten zich op het praktische probleem van het beantwoorden van vragen op expert‑niveau over Z. mobilis, een bacterie die gewaardeerd wordt omdat ze suikers efficiënt omzet in ethanol. In deze context zijn foutieve antwoorden niet alleen vervelend — ze kunnen experimenten en investeringen de verkeerde kant op sturen.
De AI sturen met de juiste instructies
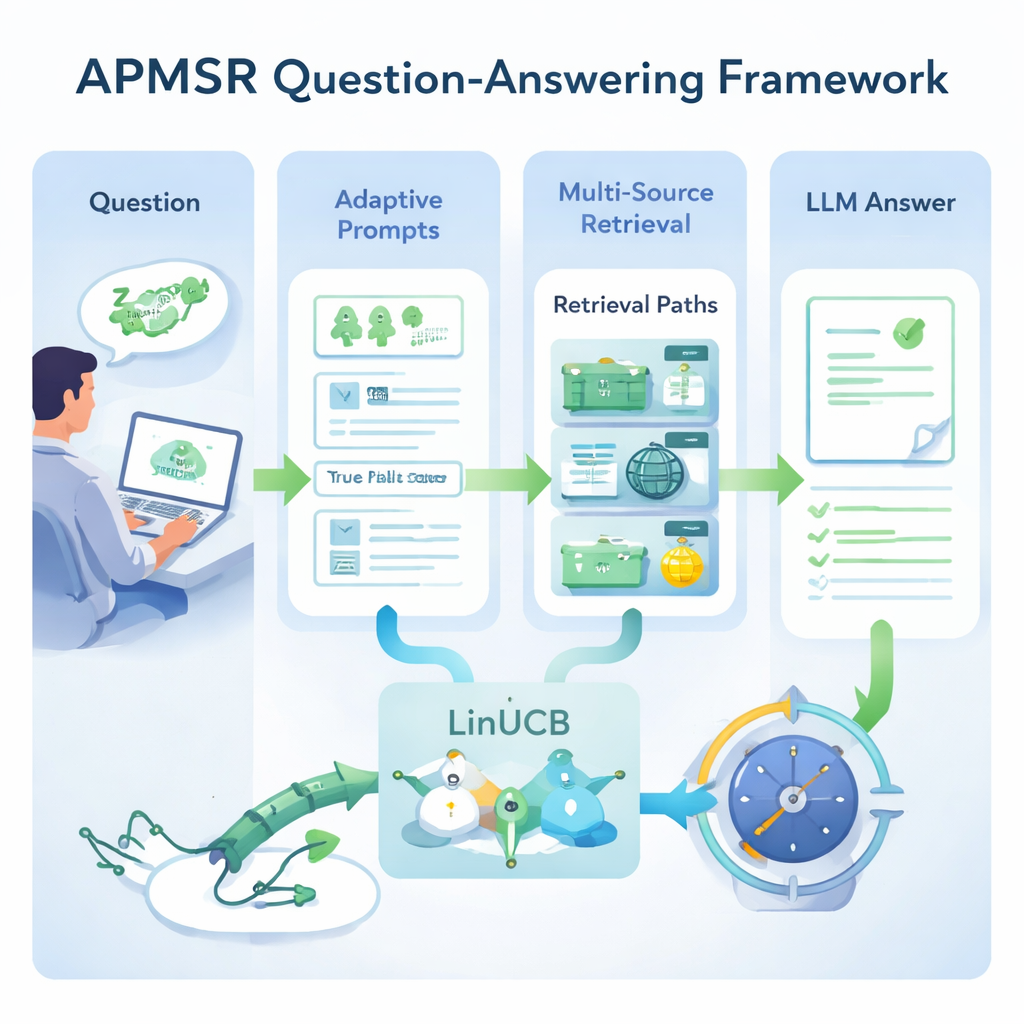
Een centraal idee in APMSR is dat hoe je het model aanstuurt net zo belangrijk is als wat je vraagt. In plaats van één vaste instructie vraagt het systeem eerst aan het LLM welk type vraag het voor zich heeft — bijvoorbeeld een meerkeuzevraag of een juist/onjuist‑stelling. Zodra het type is herkend, kiest APMSR automatisch een bijpassende “prompttemplate” die het model vertelt hoe het moet redeneren en hoe het antwoord geformatteerd moet worden. Meerkeuzevragen worden bijvoorbeeld aangespoord om opties zorgvuldig te vergelijken, terwijl juist/onjuist‑vragen worden gestuurd om de juistheid van een bewering te controleren en uit te leggen waarom. Deze adaptieve prompting helpt het model gefocust te blijven en vermindert onsamenhangende, off‑topic antwoorden.
De beste plekken kiezen om feiten te zoeken
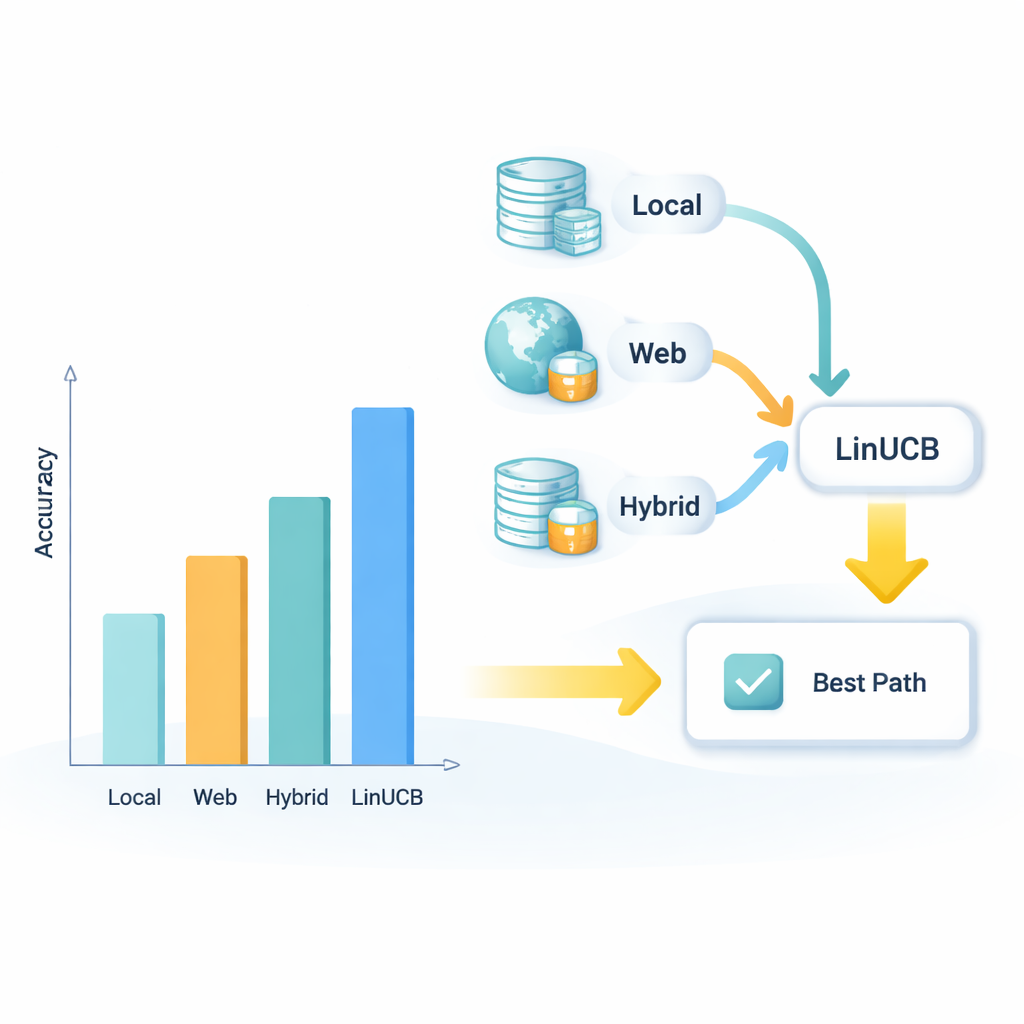
Goede instructies alleen zijn niet genoeg; het systeem moet ook op de juiste plaatsen zoeken. APMSR maakt verbinding met drie typen informatiebronnen: een lokale bibliotheek met zorgvuldig geselecteerde wetenschappelijke artikelen, live webbronnen, en een hybride die beide samenvoegt. Voor elke gebruikersvraag behandelt het systeem deze drie keuzes als concurrerende “paden” en gebruikt het een wiskundige strategie genaamd LinUCB, oorspronkelijk ontwikkeld om risico en opbrengst in beslisproblemen in balans te brengen. LinUCB beoordeelt hoe goed elk pad lijkt te werken op basis van eerdere vragen en hun uitkomsten, en kiest vervolgens het pad dat het meest waarschijnlijk een correct antwoord oplevert, terwijl het af en toe alternatieven blijft proberen. In de loop van de tijd leert deze feedbacklus het systeem welke combinaties van bronnen voor verschillende vraagstijlen het meest betrouwbaar blijken te zijn.
Het systeem op de proef stellen
Om te onderzoeken of deze ideeën daadwerkelijk helpen, bouwde het team een gespecialiseerde testset van 220 expertvragen over Z. mobilis, gelijk verdeeld tussen meerkeuze- en juist/onjuist‑formaten, allemaal afgeleid van peer‑reviewed studies. Ze vergeleken drie opstellingen: een naakt LLM zonder externe documenten, een standaard retrieval‑augmented systeem dat alleen een lokale database gebruikt, en hun volledige APMSR‑ontwerp. De nauwkeurigheid steeg van 54% voor het naakte model naar 80% met standaard retrieval, en vervolgens naar 93% toen adaptieve prompts en de LinUCB‑gebaseerde padselector werden toegevoegd. Het geoptimaliseerde systeem presteerde ook ongeveer 19 procentpunt beter dan een bestaand model gericht op synthetische biologie, SynBioGPT, wat suggereert dat slimme coördinatie van prompts en retrieval belangrijker kan zijn dan alleen een groter model trainen.
Wat dit betekent voor toekomstig labwerk
Voor niet‑specialisten is de belangrijkste conclusie dat de auteurs een soort “onderzoeks‑co‑piloot” hebben gebouwd die niet alleen vloeiend kan formuleren, maar ook weet wanneer meerdere bronnen gecontroleerd moeten worden en hoe het eigen denken gestructureerd moet worden. Door zowel de manier waarop vragen worden geformuleerd als de manier waarop informatie wordt verzameld te verfijnen, vermindert APMSR misleidende antwoorden sterk in een complex, snel evoluerend veld. Hoewel het huidige systeem gericht is op een enkele microbe en op quiz‑achtige vragen, kan dezelfde aanpak worden uitgebreid naar bredere gebieden van de biologie en daarbuiten, waarmee wetenschappers, ingenieurs en mogelijk uiteindelijk clinici geholpen worden betere vragen te stellen en betrouwbaardere antwoorden van AI‑hulpmiddelen te krijgen.
Bronvermelding: Wang, J., Cao, Z., Tian, Z. et al. APMSR: an intelligent QA system for synthetic biology empowered by adaptive prompting and multi-source knowledge retrieval. Sci Rep 16, 7331 (2026). https://doi.org/10.1038/s41598-026-38006-8
Trefwoorden: synthetische biologie, vraagbeantwoording, grote taalmodellen, retrieval augmented generation, Zymomonas mobilis