Clear Sky Science · nl
Fuzzy C-means clustering gebaseerde verticale containerstapeling in containerterminals
Waarom slimmer containerstapelen ertoe doet
Elk jaar verplaatsen bijna een miljard gestandaardiseerde metalen dozen—vrachtcontainers—zich via zeehavens over de hele wereld. Die dozen snel aan en van schepen krijgen is essentieel om goederenstromen gaande te houden en kosten laag te houden. Toch vertraagt een verrassend simpel probleem het proces: als de container die je nodig hebt onder de verkeerde dozen ligt, moeten kranen de stapel herschikken, wat tijd en brandstof kost. Dit artikel onderzoekt een nieuwe, datagestuurde manier om containers op gewicht te stapelen die deze kostbare herschikkingen vermindert, waardoor havens sneller en betrouwbaarder worden zonder extra ruimte of apparatuur te hoeven inzetten.
Het verborgen probleem van rommelige stapels
Containerterreinen lijken van afstand ordelijk, maar de volgorde waarin containers geladen en gelost moeten worden is sterk onzeker. Uitgaande containers arriveren op het terrein voordat een schip binnenkomt, en hun exacte laadvolgorde wordt beïnvloed door scheepsstabiliteitsregels en steeds wisselende stuwageplannen. Zwaardere containers gaan normaal gesproken lager in het schip, lichtere hogerop. Wanneer containers echter binnenkomen, weten medewerkers vaak niet of een bepaalde doos uiteindelijk als “zwaar” of “licht” zal gelden ten opzichte van de uiteindelijke lading. Traditionele strategieën proberen zware containers te prioriteren of werken met vaste gewichtscategorieën, maar dat kan makkelijk tegenwerken: een container die de ene dag als zwaar wordt geclassificeerd, kan de volgende dag als middelzwaar worden gezien, wat extra herschikkingen veroorzaakt bij het laden van het schip.
Verticale stapels en waarom gewichtsbalans telt
Havens gebruiken verschillende manieren om containers te rangschikken: naast elkaar in rijen (horizontaal), omhoog gestapeld per soort in kolommen (verticaal), of een hybride van beide. Deze studie richt zich op verticale stapeling, waarbij containers met vergelijkbare kenmerken in dezelfde kolomachtige stapel worden geplaatst. Verticale stapeling is aantrekkelijk omdat het makkelijker maakt een container van ongeveer het juiste gewicht te bereiken zonder te veel anderen te verstoren. In de praktijk verandert echter het aantal containers in elk gewichtsbereik van vaart tot vaart. Als gewichtsgroepen worden gedefinieerd met starre grenswaarden—bijvoorbeeld elke 5 ton—eindigen veel containers vlak bij die grens in verschillende stapels, terwijl ze bijna hetzelfde wegen. Dat vergroot de gewichtsvariatie binnen stapels en vermindert de voordelen van verticale stapeling.
De data de grenzen laten bepalen
De auteurs stellen een nieuwe strategie voor genaamd Fuzzy C-means-based Vertical Sequence Stacking, of FVSS. In plaats van van tevoren te bepalen waar de grenzen van elke gewichtsgroep liggen, kijkt de methode naar historische gewichtsgegevens van schepen op dezelfde route en laat een fuzzy clustering-algoritme natuurlijke clusters vinden. “Fuzzy” betekent hier dat het gewicht van een container gedeeltelijk tot meerdere groepen kan behoren, wat het ontbreken van een scherpe grens tussen bijvoorbeeld middelzwaar en zwaar weerspiegelt. Het algoritme kiest hoeveel clusters het beste passen bij de historische data van elk schip en identificeert een gewichtscentrum voor elke cluster. Het terrein wordt vervolgens vooraf verdeeld in een aantal stapels evenredig met het aantal containers dat typisch in elk gewichtsgroep valt, en elke stapel krijgt een referentiewicht gebaseerd op die centra.
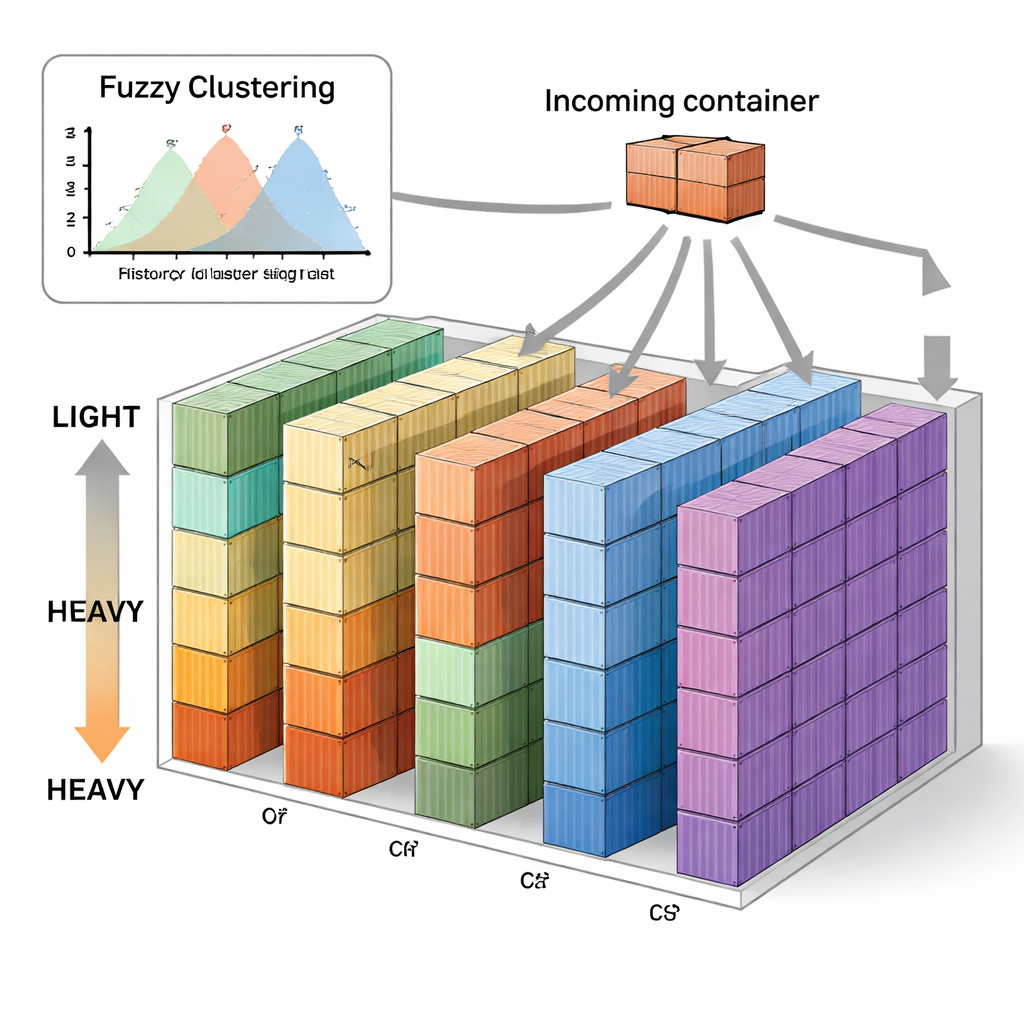
Eenvoudige regels voor realtime beslissingen
Als het terrein eenmaal op deze manier is ingericht, volgen de dagelijkse operaties een eenvoudige regel. Zodra een container arriveert, wordt zijn benaderende gewichtsklasse bepaald met behulp van de fuzzy clusters. Als er vrije ruimte is in de stapels die voor die klasse gereserveerd zijn, gaat de container daarheen. Zijn die stapels vol of zijn meerdere opties beschikbaar, dan kiest het systeem de stapel waarvan het referentiewicht het dichtst bij het werkelijke gewicht van de container ligt. In de loop van de tijd leidt dit ertoe dat containers met vergelijkbaar gewicht vanzelf in dezelfde stapels komen te staan, zonder ingewikkelde optimalisatie of voortdurende machine-learningtraining. De auteurs testten deze aanpak op tien maanden echte data van het Busan Container Terminal in Korea, en vergeleken het met verschillende bekende methoden, waaronder willekeurig stapelen, een hybride horizontaal–verticaal strategie, en eerdere technieken gebaseerd op Gaussian mixture models en online learning.
Wat de resultaten voor havens betekenen
De belangrijkste maat in de studie is hoe sterk de containergewichten binnen elke stapel variëren—een kleinere spreiding betekent dat het makkelijker is geschikte containers te vinden tijdens het laden van een schip met minder herschikkingen. Over meerdere schepen en twee terreininrichtingen (5 en 10 stapels) verminderde de FVSS-strategie de gewichtsvariantie veel sterker dan de concurrerende benaderingen, met verbeteringen tot 78% vergeleken met willekeurig stapelen en aanzienlijke winst ten opzichte van andere geavanceerde methoden. Cruciaal is dat de prestatie sterk bleef, zelfs toen de onderzoekers containergewichten opzettelijk verstoorden om fouten en last-minute wijzigingen na te bootsen. Voor havenexploitanten betekent dit dat ze soepelere kraanoperaties en kortere omlooptijden van schepen kunnen bereiken door te vertrouwen op een geautomatiseerde maar transparante regelsset die makkelijk te updaten is naarmate nieuwe reizen worden voltooid, zonder te investeren in zware rekeninfrastructuur of ingewikkelde leersystemen.
Bronvermelding: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
Trefwoorden: containerterminals, stapelplaats, fuzzy clustering, maritieme logistiek, operationele efficiëntie