Clear Sky Science · nl
Correctie van ruisende labels via vergelijkende distillatie: een benadering voor domeinadaptatie
Waarom rommelige data een groeiend probleem is
Moderne kunstmatige intelligentie floreert op data, maar die data is vaak onjuist, onvolledig of inconsistent gelabeld. Wanneer labels ruis bevatten — bijvoorbeeld een foto van een kat die als hond is getagd — kunnen leersystemen op het verkeerde been worden gezet en minder nauwkeurig en minder betrouwbaar worden. Dit artikel pakt dat praktijkprobleem aan: hoe train je beeldherkenningssystemen die nog steeds goed werken, zelfs wanneer de trainingslabels gebrekkig zijn en de afbeeldingen uit verschillende omgevingen komen, zoals webwinkels versus foto’s uit de echte wereld.
Leren over verschillende werelden heen
In de praktijk leren AI-modellen vaak van een “bron”wereld waarin labels zorgvuldig gecontroleerd zijn, en moeten ze presteren in een “doel”wereld waar labels schaars en foutgevoelig zijn. Bijvoorbeeld: kantoorvoorwerpen gefotografeerd in een studio zijn netjes en correct gelabeld, terwijl webcam- of alledaagse foto’s van dezelfde voorwerpen rommelig zijn en inconsistent getagd. Traditionele domeinadaptatiemethoden proberen deze kloof te overbruggen door de algemene statistieken van de twee werelden op elkaar af te stemmen. Ze gaan echter meestal uit van de veronderstelling dat doel‑labels, wanneer aanwezig, correct zijn — een riskante aanname die faalt in echte toepassingen met crowdsourced tags, sensoren van lage kwaliteit of automatische annotatietools.
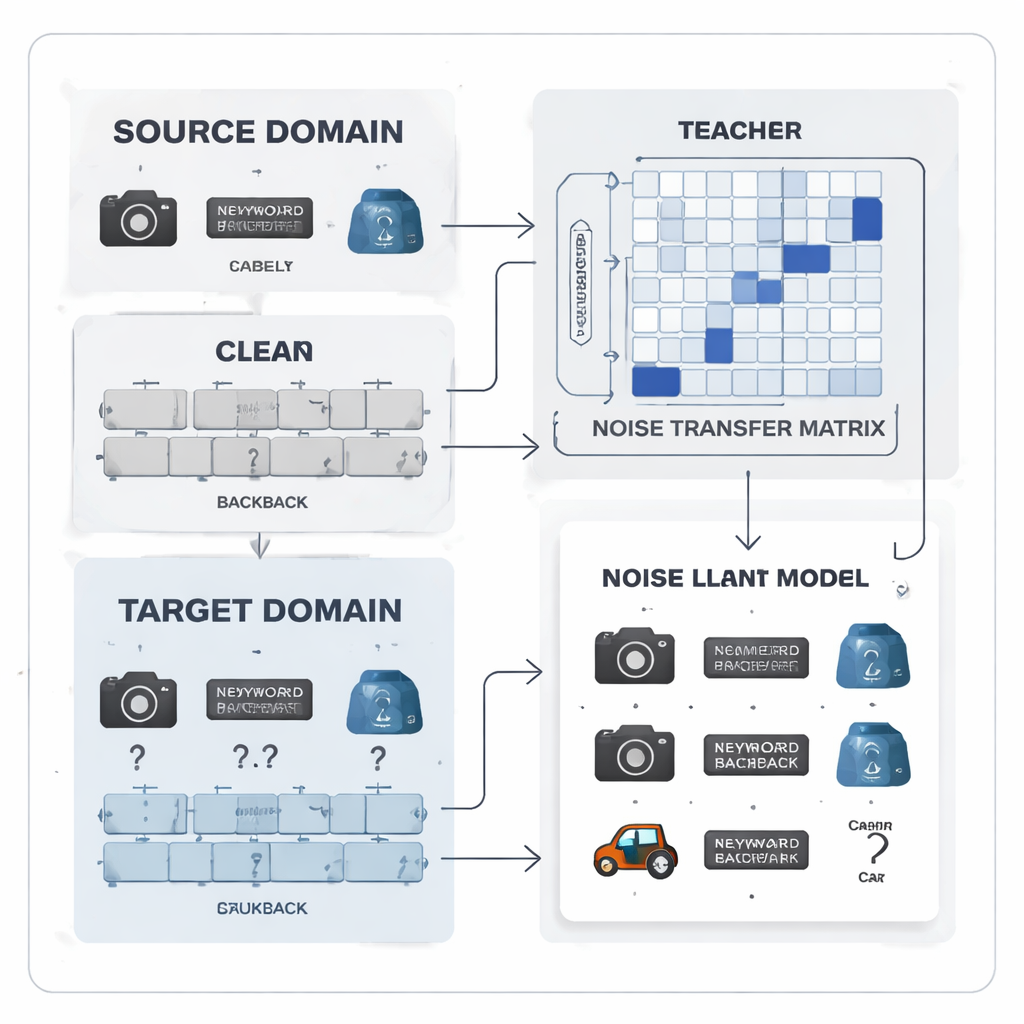
Labelfouten omzetten in een leerbaar patroon
De auteurs stellen voor labelruis niet als willekeurige chaos te zien maar als een leerbaar patroon. Ze introduceren een “ruisoverdrachtsmatrix”, een tabel die vastlegt hoe waarschijnlijk het is dat elke ware klasse als een andere wordt verkeerd gelabeld. In plaats van deze tabel te schatten op basis van een handvol perfecte “ankerpunt”-voorbeelden — wat onrealistisch is wanneer labels ruisen en klassen ongebalanceerd zijn — wordt de matrix direct tijdens training geleerd. Om het leren op gang te helpen, bouwt de methode categorische “prototypes”: gemiddelde feature‑vingerafdrukken voor elke klasse, geëxtraheerd door een sterk vooraf getraind model. De overeenkomsten tussen deze prototypes worden gebruikt om de matrix te initialiseren, zodat verwisselbare categorieën, zoals vergelijkbare kantoorhulpmiddelen, vanaf het begin sterker met elkaar verbonden zijn en het systeem vroeg in staat stellen labels te corrigeren.
Teamwork tussen teacher en student voor schonere signalen
Centraal in het systeem staat een teacher–studentpaar van neurale netwerken. De teacher is gebaseerd op een groot self‑supervised visueel model dat rijke visuele features heeft geleerd uit enorme hoeveelheden niet‑gelabelde data. De student is een lichter netwerk dat goed moet presteren op de ruisende doeldata. De teacher produceert zachte voorspellingsscores die laten zien hoe gerelateerd verschillende klassen zijn; uit deze scores construeert de methode een klassencorrelatiematrix die samenvat welke labels vaak samen voorkomen. Deze matrix fungeert als gids en stuurt de ruisoverdrachtsmatrix richting realistischer correcties. Tegelijkertijd wordt de student getraind om het gedrag van de teacher te evenaren via distillatie, terwijl contrastief leren beide netwerken aanmoedigt om vergelijkbare interne representaties te geven voor verschillende geaugmenteerde weergaven van dezelfde afbeelding en onderscheidende representaties voor verschillende objecten.
Correcties stabiel houden en overmoedigheid vermijden
De ruisoverdrachtsmatrix vrij laten veranderen zou instabiliteit of overgevoeligheid voor uitbijters kunnen veroorzaken. Om dit te voorkomen gebruiken de auteurs een wiskundige truc gebaseerd op singulierewaardedecompositie, die de matrix uiteenlegt in basisrichtingen van rekking. Door de algehele “volume” die door deze richtingen wordt geïmpliceerd te bestraffen, ontmoedigt de methode extreme vervormingen die ruis zouden versterken. Een ander probleem doet zich voor wanneer het model te zeker van zichzelf wordt en bijna alle waarschijnlijkheid aan één klasse toekent; bij zulke scherpe voorspellingen wordt het moeilijk om foutieve labels aan te passen. Om dit aan te pakken voegt de methode een vorm van entropieregularisatie toe, gebaseerd op Tsallis-entropie, die voorspellingkansen vloeiender houdt. Dit maakt het eenvoudiger voor de ruisoverdrachtsmatrix om waarschijnlijkheidsmassa gedeeltelijk van een onjuiste klasse naar plausibelere alternatieven te herverdelen.
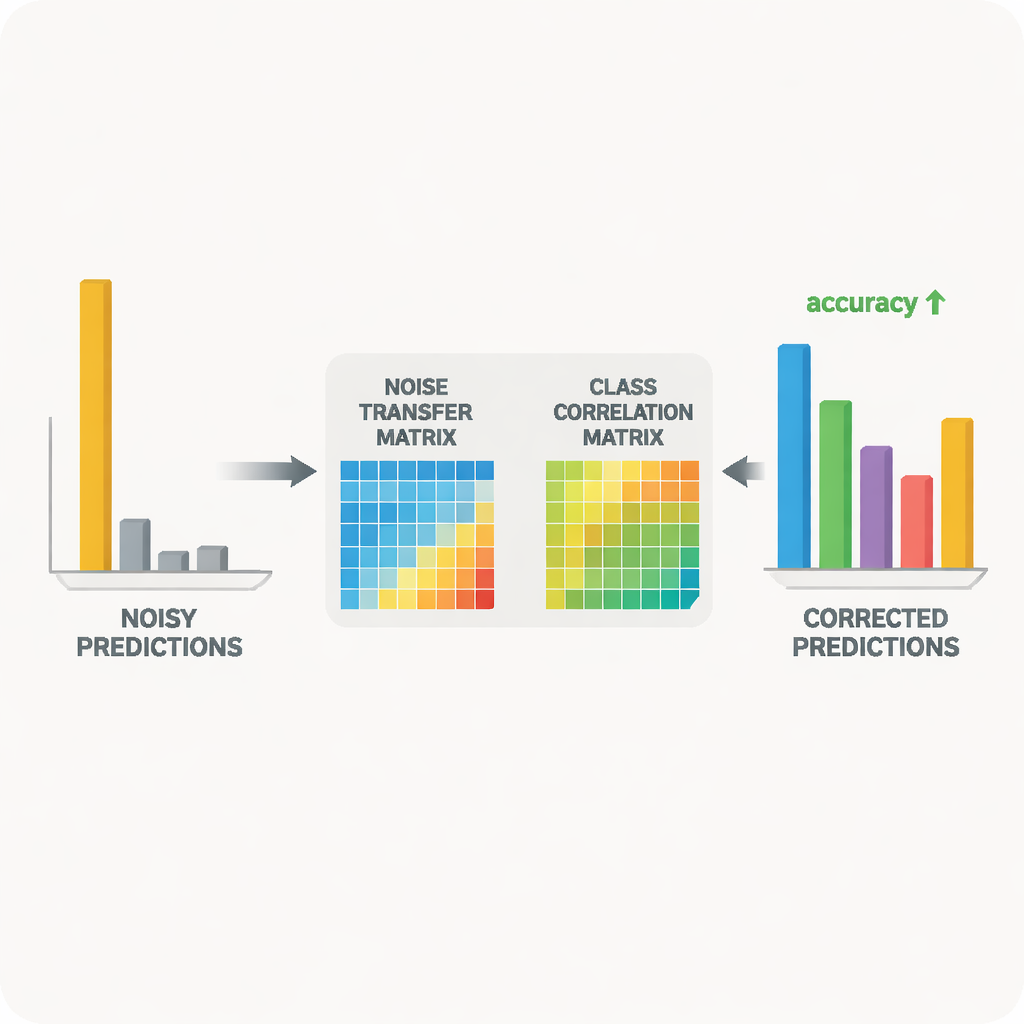
Het idee bewijzen op echte beeldverzamelingen
De onderzoekers testten hun aanpak op twee veelgebruikte benchmarks voor cross‑domain objectherkenning: Office‑31 en Office‑Home, die afbeeldingen van alledaagse kantoorartikelen bevatten in meerdere stijlen zoals productfoto’s, clipart en foto’s uit de echte wereld. Over een reeks taken “train op één stijl, test op een andere” behaalde hun methode vergelijkbare of betere resultaten dan toonaangevende algoritmen, vooral in de moeilijkste gevallen waar de kloof tussen domeinen het grootst is. Gedetailleerde studies toonden aan dat elk onderdeel — de volumebeperking voor de ruismatrix, de klassencorrelatie‑begeleiding en de entropie‑verzachting — meetbare verbeteringen bijdroeg. Visualisaties van de geleerde matrix en van de feature‑ruimte bevestigden dat verkeerd gelabelde voorbeelden tijdens de training geleidelijk naar hun correcte categorieën werden getrokken en dat de bron‑ en doelbeeldverdelingen beter op elkaar werden afgestemd.
Wat dit betekent voor alledaagse AI‑systemen
Voor niet‑specialisten is de belangrijkste conclusie dat dit werk AI‑modellen vergevingsgezinder maakt voor menselijke en machinale labelfouten, vooral wanneer die modellen van schone laboratoriumomstandigheden naar rommeliger echte wereldomgevingen moeten worden overgebracht. Door expliciet te leren hoe labels de neiging hebben fout te gaan en een krachtig teacher‑model te gebruiken om correcties te sturen, kan de methode ruisende trainingssignalen opschonen en nauwkeurigere, robuustere classifiers opleveren. Hoewel de aanpak extra rekenkracht vereist, wijst het op een toekomst waarin grote, onvolmaakte datasets die “in het wild” zijn verzameld veiliger en effectiever kunnen worden benut, waardoor onze afhankelijkheid van moeizaam handmatig annoteren afneemt.
Bronvermelding: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Trefwoorden: ruisende labels, domeinadaptatie, kennisdistillatie, beeldclassificatie, semi-gesuperviseerd leren