Clear Sky Science · nl
Risicogevoelige twin distributionele critici met een lambda lager betrouwbaarheids-ondergrens voor continuë-controlevraagstukken in reinforcement learning
Robots leren voorzichtig te zijn
Veel van de meest indrukwekkende robots en spelprogramma’s van vandaag vertrouwen op reinforcement learning, een leerproces door vallen en opstaan waarbij softwareagenten leren door beloningen te verzamelen. Maar deze agenten jagen vaak op de hoogst mogelijke score en negeren daarbij hoe risicovol hun beslissingen zijn, wat kan leiden tot instabiel leren en af en toe crashes. Dit artikel introduceert een methode genaamd TDC-λ (Twin Distributional Critics met een Lambda Lower Confidence Bound) die dergelijke agenten leert niet alleen hoog te mikken, maar ook betrouwbaar veilig te blijven tijdens het leerproces.
Waarom stabiliteit belangrijk is in leerende systemen
Standaard algoritmen voor continue besturing, zoals het veelgebruikte TD3 en Soft Actor–Critic (SAC), hebben robots in staat gesteld te rennen, te springen en te balanceren in complexe simulaties. Deze methoden beoordelen acties meestal echter met één enkel getal: een schatting van hoeveel beloning een actie op de lange termijn zal opleveren. Die eenvoudige score kan misleidend zijn wanneer het leerproces ruis bevat, waardoor het systeem de waarde van bepaalde acties overschat. Het resultaat is een leercurve die er gemiddeld goed uitziet maar sterk wisselt tussen runs, wat problematisch is als hetzelfde algoritme fysieke machines of veiligheidkritische systemen moet besturen.
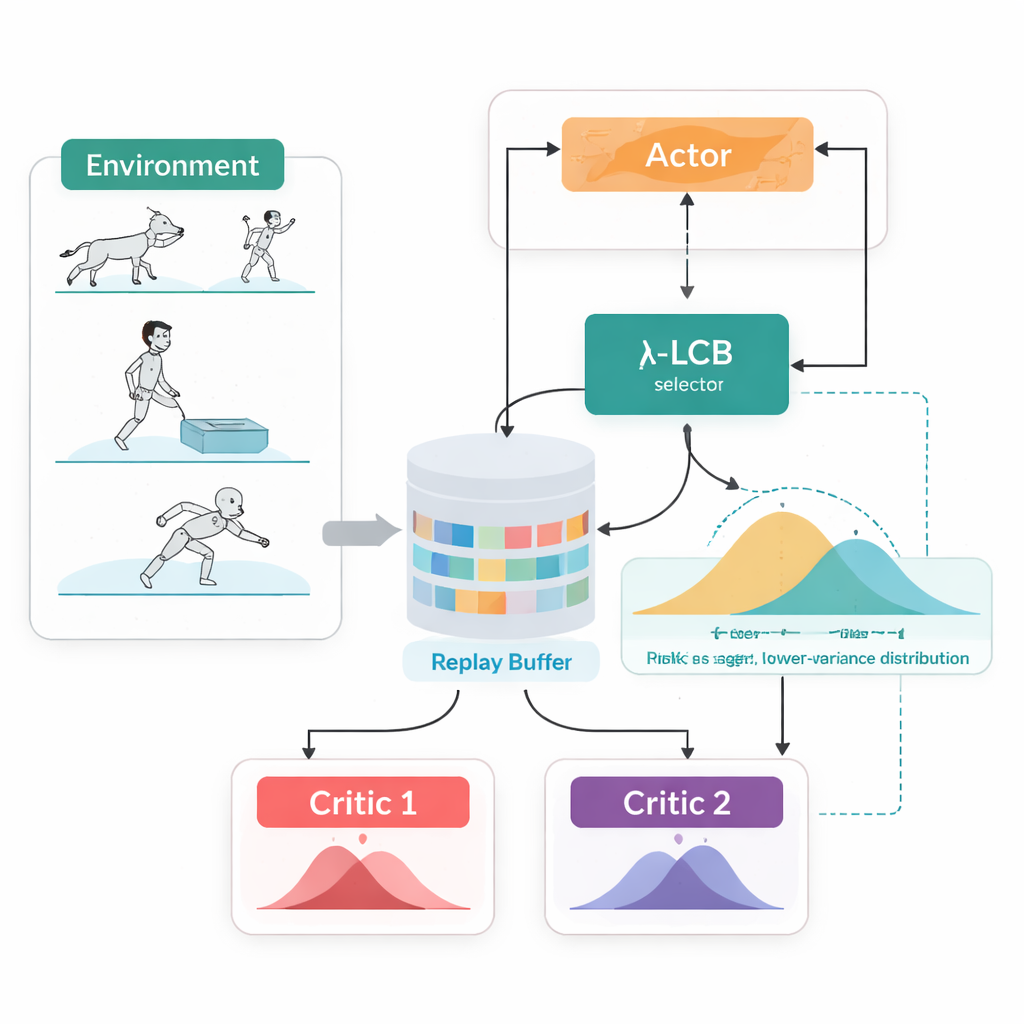
Kijk naar volledige toekomsten, niet naar enkele getallen
TDC-λ pakt dit probleem aan door te veranderen hoe de agent zijn toekomst evalueert. In plaats van voor elke actie slechts één verwachte beloning te voorspellen, leert het twee aparte "critici" die elk een volledige distributie over mogelijke toekomstige opbrengsten uitgeven. Vanuit deze distributies berekent het algoritme niet alleen de gemiddelde uitkomst maar ook hoe verspreid de mogelijkheden zijn. Die spreiding weerspiegelt onzekerheid of risico. Met een eenvoudige regel, samengevat als een lagere betrouwbaarheidsondergrens, geeft TDC-λ de voorkeur aan de criticus die een veiliger resultaat voorspelt: een voorspelling die misschien iets minder optimistisch is maar door consistenter bewijs wordt ondersteund. Eén enkele instelling, de risicoparameter λ, stelt soepel in hoe voorzichtig deze selectie is—van gedrag dat lijkt op een conventionele TD3-achtige methode bij λ = 0 tot steeds conservatiever naarmate λ groter wordt.
Één trainingslus, twee manieren om te handelen
Een andere praktische eigenschap van TDC-λ is dat het zowel deterministische als stochastische manieren van actiekeuze binnen één verenigd raamwerk ondersteunt. Tijdens training kunnen gebruikers kiezen voor een klassieke deterministische policy of een tanh-gesquashte Gaussian policy die acties sampelt en zo exploratie bevordert. Ongeacht die keuze worden de twin distributionele critici op dezelfde manier getraind, en bij evaluatie wordt altijd de deterministische gemiddelde actie gebruikt. Dit ontwerp benut eerdere bevindingen dat deterministisch gedrag tijdens testtijd vaak even goed of beter presteert dan sampling, terwijl het tijdens het leren toch rijke, exploratievriendelijke policies mogelijk maakt.
De methode op de proef gesteld
De auteurs evalueerden TDC-λ op vijf populaire MuJoCo-benchmarktaken waarin gesimuleerde robots zoals HalfCheetah, Hopper, Ant, Walker2d en Humanoid moeten leren efficiënt te bewegen. Over deze taken heen evenaarde of verbeterde de nieuwe methode de eindprestatie van sterke referenties waaronder TD3, DDPG, SAC en een geavanceerde flow-gebaseerde aanpak genaamd MEOW, terwijl het consequent minder variabiliteit tussen herhaalde runs liet zien. In zwaardere, hogere-dimensionale taken zoals Humanoid leidden iets hogere waarden van λ—dus voorzichtiger doelschattingen—tot de beste langetermijnopbrengsten en de kleinste prestatiebanden. Aanvullende experimenten in andere simulatoren (PyBullet en NVIDIA Isaac) en diagnostieken die de variabiliteit van het leersignaal volgen, versterkten de conclusie dat TDC-λ het leren stabieler maakt zonder het te vertragen.
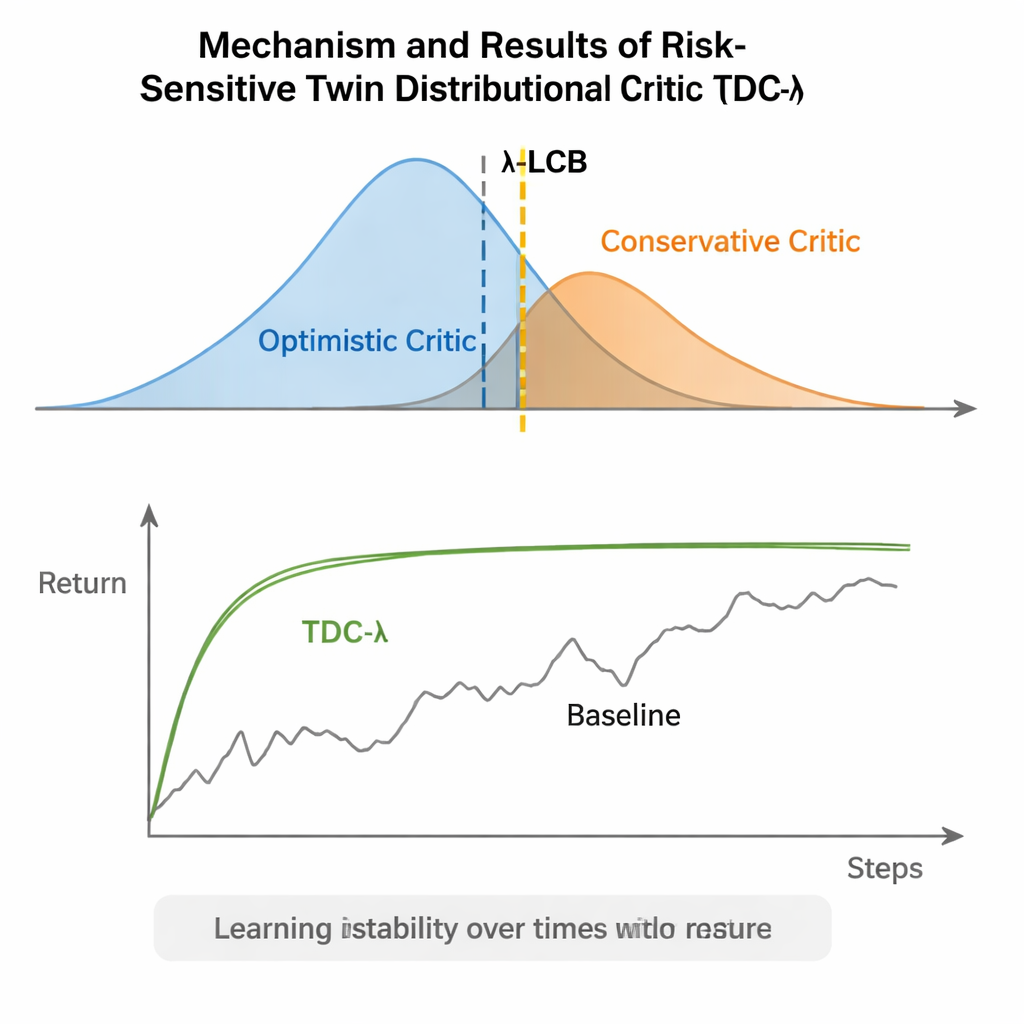
Een eenvoudige knop voor veiliger leren
In gewone bewoordingen geeft TDC-λ reinforcement-learning-systemen een "veiligheidsmarge" bij het bepalen hoeveel ze hun eigen optimisme moeten vertrouwen. Door volledige distributies van mogelijke uitkomsten te leren en vervolgens met behulp van de λ-knop naar de veiligere criticus te neigen, vermindert het algoritme wilde schommelingen tijdens training terwijl het een hoge eindprestatie behoudt. Voor praktijkmensen biedt dit een praktische manier om betrouwbaardere controllers voor robots en andere systemen voor continue besturing te bouwen: begin met een matig conservatieve λ en pas die aan op basis van hoe volatiel het leerproces lijkt. De bredere boodschap is dat het zorgvuldig vormgeven van waar de agent van leert—zijn trainingsdoelen—veel van de robuustheid kan leveren die vaak aan complexere architecturen wordt toegeschreven, waardoor geavanceerde reinforcement learning zowel stabieler als toegankelijker wordt.
Bronvermelding: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Trefwoorden: reinforcement learning, continue besturing, risicogevoelig leren, distributionele critici, robotica