Clear Sky Science · nl
Voorspellingsmodel voor luchtkwaliteit gebaseerd op een hybride deep learning‑kader
Waarom schonere luchtvoorspellingen voor u belangrijk zijn
Wanneer smog een stad bedekt, moeten mensen plotseling praktische keuzes maken: is het veilig om buiten te joggen, kinderen naar school te sturen of fabrieken te laten draaien? Die beslissingen hangen af van hoe goed we fijne vervuilingsdeeltjes, genaamd PM2.5, kunnen voorspellen; deze deeltjes zijn klein genoeg om diep in de longen te blijven zitten. Deze studie introduceert een nieuw computermodel dat gebruikmaakt van recente vorderingen in kunstmatige intelligentie om PM2.5‑niveaus in Chinese steden nauwkeuriger en sneller te voorspellen dan veel bestaande hulpmiddelen, wat het publiek en beleidsmakers mogelijk eerder en betrouwbaarder waarschuwt.
Van grauwe luchten naar slimme data
Luchtvervuiling is in veel stedelijke gebieden een aanhoudende bedreiging voor de gezondheid, vooral in Noord‑China, waar hoge PM2.5‑waarden worden gekoppeld aan ademhalings- en hart‑ en vaatziekten. Steden beheren nu dichte netwerken van meetstations die elk uur PM2.5, andere vervuilende stoffen en lokaal weer volgen. Traditionele voorspelmethoden vertrouwen op vereenvoudigde wiskunde of handgemaakte fysieke modellen, die worstelen met de rommelige, niet‑lineaire realiteit van draaiende wind, temperatuurverschuivingen en menselijke activiteit. In tegenstelling daarmee laat de nieuwe aanpak, CBLA genaamd, de data "zelf spreken" door moderne neurale netwerken te trainen op meerdere jaren observaties uit Beijing en Guangzhou.
Hoe de nieuwe voorspellingsmotor werkt
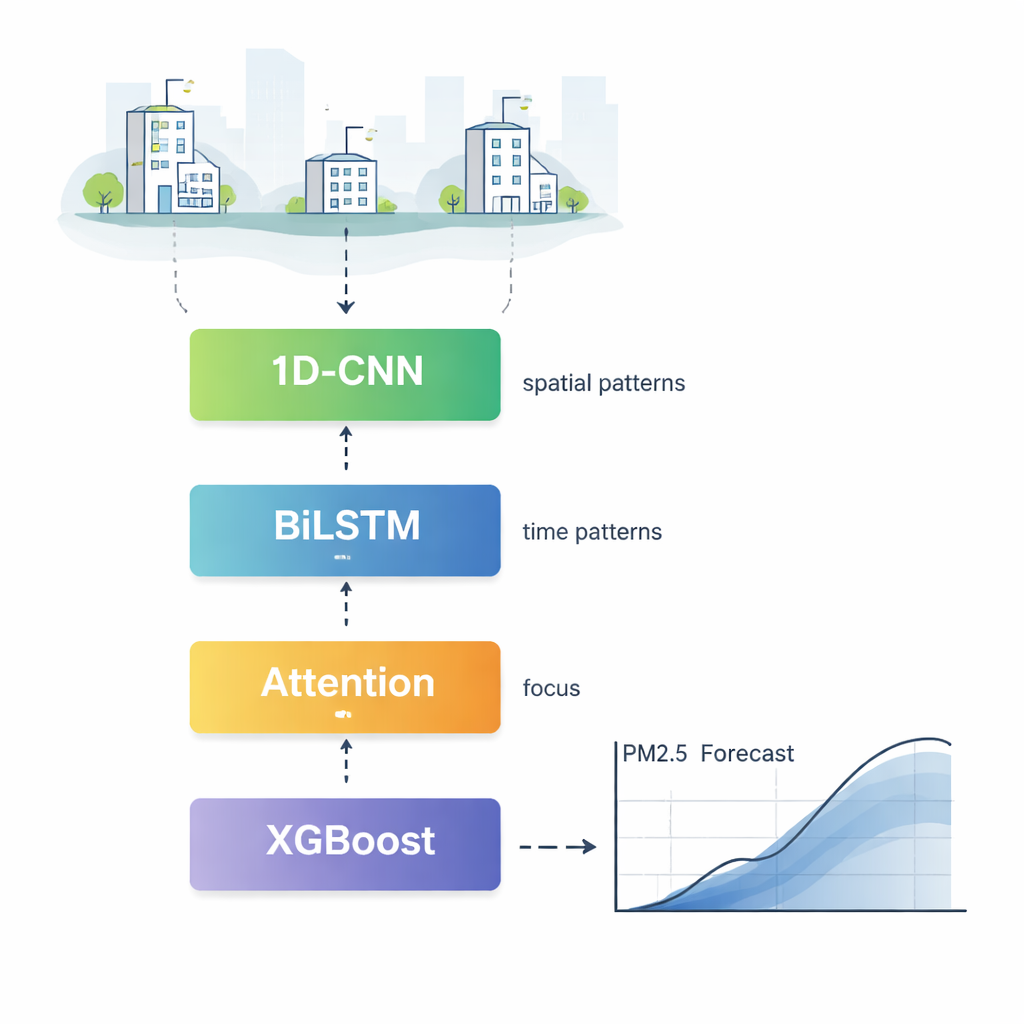
CBLA functioneert als een gelaagd team van specialisten die vervuilingsgegevens vanuit verschillende hoeken bestuderen voordat ze een eindvoorspelling maken. Eerst scant een component, bekend als een eendimensionaal convolutioneel netwerk, metingen van vele meetstations om patronen te vinden die zich ruimtelijk herhalen, zoals hoe rook zich vaak van de ene wijk naar de andere verspreidt. Vervolgens leest een bidirectioneel geheugen‑netwerk vervuilingsgeschiedenis vooruit en achteruit in de tijd, en leert het hoe de niveaus van vandaag afhangen van zowel recente als iets oudere omstandigheden. Een attentiemechanisme markeert daarna de meest invloedrijke uren en kenmerken, waardoor het model zich meer kan richten op bijvoorbeeld de scherpe piek van gisteren en sterke wind, in plaats van op verre, minder relevante metingen.
Weergegevens toevoegen om het beeld te verscherpen
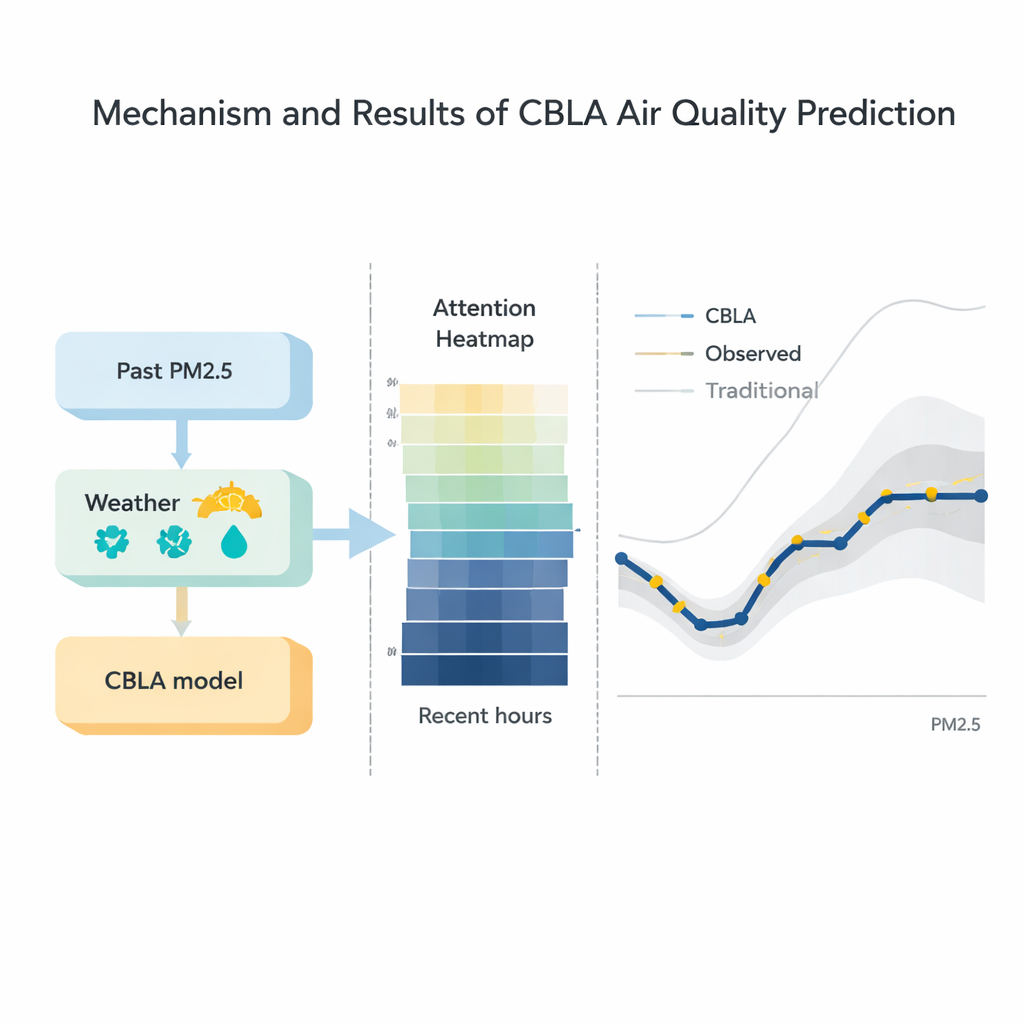
Vervuiling beweegt niet geïsoleerd; het reist mee met veranderend weer. Om deze informatie netjes in te vouwen, voegen de auteurs een tweede fase toe die zowel de voorlopige neurale‑netwerkvoorspelling als gedetailleerde meteorologische gegevens — zoals windsnelheid, luchtvochtigheid en temperatuur — invoert in een krachtig boomgebaseerd algoritme genaamd XGBoost. Deze fase gedraagt zich als een ervaren meteoroloog die de eerste inschatting controleert aan de hand van het actuele weer en de voorspelling iets naar boven of beneden bijstelt. Tests tonen aan dat deze combinatie typische voorspellingsfouten vermindert en verbetert hoe nauwkeurig de uitvoer het werkelijke meetbeeld volgt, vooral tijdens plotselinge opbouws‑ en uitblaasgebeurtenissen van vervuiling.
Getest tegen concurrerende modellen
De onderzoekers vergeleken CBLA met een breed scala aan alternatieven, van klassieke technieken zoals regressie en ARIMA‑tijdreeksmodellen tot geavanceerde deep‑learninghybriden die grafnetwerken en transformers combineren. Over drie echte datasets produceerde CBLA consequent de laagste gemiddelde fout en de strakste aansluiting op waargenomen PM2.5‑niveaus. Belangrijk is dat het vergelijkbare nauwkeurigheid behaalde als enkele van de meest geavanceerde moderne modellen, terwijl het slechts ongeveer een derde van hun trainingstijd op standaardhardware nodig had. Visualisaties van het attentiemechanisme toonden aan dat het model van nature de meeste waarde toekent aan de meest recente uren data en aan fysiek betekenisvolle factoren zoals windsnelheid en eerdere PM2.5‑waarden, wat inzicht geeft in hoe de beslissingen overeenkomen met meteorologische intuïtie.
Wat dit betekent voor het dagelijks leven
Concreet laat de studie zien dat het zorgvuldige combineren van meerdere AI‑technieken kan leiden tot een vervuilingsvoorspellingsinstrument dat niet alleen nauwkeuriger is, maar ook sneller en gemakkelijker te interpreteren. Stadsbeheerders zouden zo’n model kunnen gebruiken om gezondheidsadviezen te activeren, verkeersbeperkingen aan te passen of industriele activiteiten preventief terug te schalen uren voordat gevaarlijke smogpieken optreden. Voor bewoners betekenen betere voorspellingen duidelijkere richtlijnen over wanneer maskers te dragen, luchtreinigers te gebruiken of kinderen binnen te houden. Hoewel het werk zich richt op Chinese steden en PM2.5, kan hetzelfde kader worden aangepast aan andere regio’s en verontreinigende stoffen, wat wijst op een toekomst waarin datagedreven voorspellingen miljoenen mensen helpen iets makkelijker te ademen.
Bronvermelding: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Trefwoorden: voorspelling luchtkwaliteit, PM2.5, deep learning, stedelijke vervuiling, meteorologie