Clear Sky Science · nl
Efficiënte detectie van inbraken in de TON-IoT-dataset met een hybride aanpak voor featureselectie
Waarom het beschermen van slimme apparaten ertoe doet
Miljarden alledaagse apparaten — van beveiligingscamera’s voor thuis tot sensoren in fabrieken — communiceren nu via internet en vormen wat we het Internet of Things (IoT) noemen. Die verbondenheid brengt gemak en efficiëntie, maar opent ook nieuwe kansen voor hackers. Het hier samengevatte artikel behandelt een eenvoudige maar cruciale vraag: hoe kunnen we betrouwbaar aanvallen signaleren in deze uitgestrekte apparaatsnetwerken zonder zware, energieverslindende beveiligingssoftware?
De uitdaging van het opsporen van digitale inbraken
Om aanvallen op IoT-systemen te bestuderen, vertrouwen onderzoekers vaak op grote, openbare datasets die vastleggen hoe netwerkverkeer eruitziet tijdens zowel normale werking als cyberaanvallen. Een van de meest gebruikte is de ToN-IoT-dataset, die echt verkeer van een realistisch industrieel testbed bevat, met vele soorten aanvallen zoals denial of service, ransomware, wachtwoordkraken en man-in-the-middle-spionage. De auteurs laten echter zien dat deze dataset een verborgen valkuil heeft: veel aanvallen werden gestart vanaf vaste IP-adres- en poortbereiken. Dat betekent dat een model kan “valsspelen” door te leren wie de aanvaller is in plaats van welk gedrag kwaadaardig is. Zulke modellen kunnen in het lab zeer hoge scores halen maar slecht presteren wanneer een aanvaller vanaf een nieuw adres komt.
Van omvangrijke data naar een slanker beeld van gedrag
De originele ToN-IoT-netwerkdata bevat 44 verschillende metingen voor elke verbinding, variërend van IP-informatie tot details over web- en versleuteld verkeer. Allemaal hanteren verhoogt de rekentijd en het geheugenverbruik, wat problematisch is voor kleine IoT-gateways en edge-apparaten. De auteurs gebruiken eerst hun kennis van hoe aanvallen werken om kenmerken weg te laten die ofwel bevooroordeeld zijn (zoals IP-adressen en poortnummers) of niet erg behulpzaam zijn om aanvallen te onderscheiden. Ze beargumenteren dat de meeste IoT-bedreigingen uiteindelijk naar voren komen als afwijkende patronen in hoeveel pakketten en bytes worden verzonden, ontvangen en hoe lang verbindingen duren — ongeacht wie met wie communiceert. Deze eerste stap verkleint de feature-set van 44 naar zeven kernstatistieken van het verkeer gerelateerd aan volume en duur.
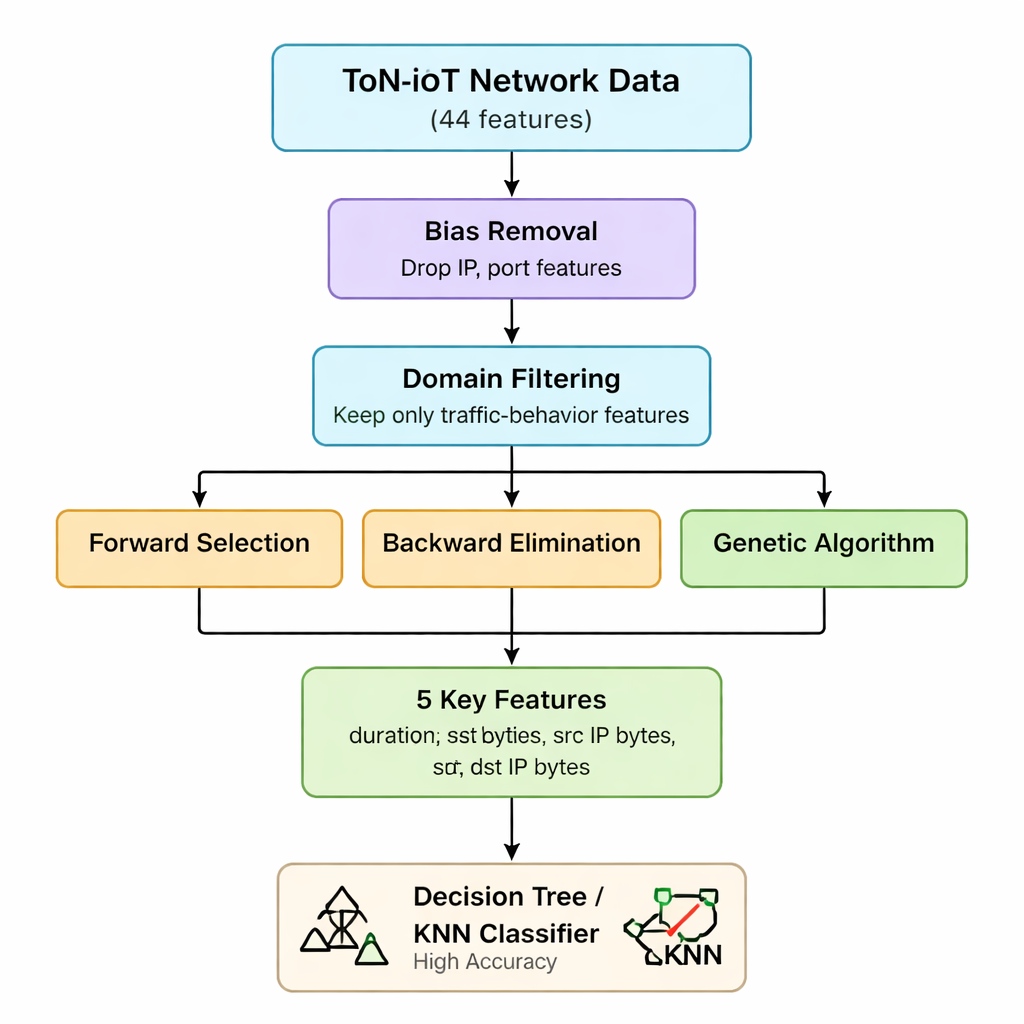
Hybride featureselectie: drie lenzen op dezelfde data
Vervolgens past het team drie verschillende "wrapper"-methoden toe die herhaaldelijk een model trainen terwijl ze features toevoegen, verwijderen of hercombineren om te zien welke subset echt het meest telt. Voorwaartse selectie bouwt op vanaf een lege set en behoudt een feature alleen als die de nauwkeurigheid verhoogt. Achterwaartse eliminatie begint met alle zeven en verwijdert features die de nauwkeurigheid niet schaden wanneer ze worden weggelaten. Een genetisch algoritme verkent veel combinaties parallel en evolueert over generaties betere subsets. Alle drie worden getest met een eenvoudige decision tree-classifier, waarbij nauwkeurigheid het meetinstrument is. Door de resultaten te kruisen komen de auteurs tot een stabiele kern van vijf features: verbindingsduur, verzonden bytes, ontvangen bytes en de overeenkomstige IP-level byte-aantallen. Deze vijf variabelen vangen effectief abnormale pieken of onevenwichtigheden in verkeer die veel verschillende aanvalstypen signaleren.
Lightweight modellen die toch sterk presteren
Met deze versmalde, op gedrag gerichte dataset evalueren de onderzoekers hoe goed eenvoudige machine learning-modellen veilig verkeer van aanvallen kunnen onderscheiden. Met alleen de vijf gekozen features haalt een decision tree 98,6% nauwkeurigheid voor de basisclassificatie “aanval versus normaal” en 97,2% nauwkeurigheid bij het onderscheiden van meerdere aanvalscategorieën. Een k-nearest neighbor-model presteert vergelijkbaar, en complexere ensemble-methoden zoals random forests of gradient boosting bieden slechts kleine verbeteringen terwijl ze meer rekenkracht en geheugen eisen. Cruciaal is dat de auteurs via statistische tests bevestigen dat hun gekozen features echt informatief zijn en geen artefacten van de manier waarop de data verzameld is. Ze merken wel op dat subtiele man-in-the-middle-aanvallen — ontworpen om op normale stromen te lijken — moeilijker te detecteren blijven, wat suggereert dat toekomstig werk rijkere protocol- of timingkenmerken nodig kan hebben voor deze gevallen.
Wat dit betekent voor beveiliging in de praktijk
Voor niet-specialisten is de belangrijkste conclusie dat je niet altijd enorme modellen of tientallen technische metingen nodig hebt om IoT-systemen te beschermen. Door aanwijzingen weg te laten die alleen in één labopstelling werken en in plaats daarvan te focussen op een handvol verkeersgedragingen, tonen de auteurs aan dat eenvoudige, snelle algoritmen toch de meeste aanvallen met hoge betrouwbaarheid kunnen oppikken. Hun vijf-feature-versie van de ToN-IoT-dataset is makkelijker te verwerken op beperkte apparaten aan de rand van het netwerk, wat het praktisch maakt voor routers, gateways en kleine hubs die in realtime op bedreigingen moeten reageren. Kortom, de studie wijst op een pad naar betrouwbaardere en beter inzetbare indringingsdetectie voor de alledaagse slimme apparaten die ons steeds meer omringen.
Bronvermelding: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Trefwoorden: IoT-beveiliging, indringingsdetectie, machine learning, featureselectie, netwerkverkeer