Clear Sky Science · nl
Modellering en toepassing van predictie van complexe kenmerken bij de ziekte van Alzheimer op basis van multi-task learning
Waarom dit onderzoek belangrijk is voor families en patiënten
De ziekte van Alzheimer is een van de meest gevreesde diagnosen van onze tijd, maar artsen hebben nog steeds moeite om te voorspellen wie snel achteruit zal gaan, wie jarenlang stabiel blijft en welke vroege signalen daadwerkelijk van belang zijn. Deze studie stelt een eenvoudige maar krachtige vraag: als we verschillende Alzheimer-gerelateerde testuitslagen en hersenscans samen bekijken en combineren met iemands genetische informatie, kan moderne kunstmatige intelligentie dan patronen leren die ons helpen het ziekteverloop nauwkeuriger te voorspellen?
Vele verschijningsvormen van dezelfde ziekte
Alzheimer is niet alleen geheugenverlies. Patiënten verschillen in hun prestaties op denkvaardigheidstests, in hoe goed ze dagelijkse taken aankunnen en in hoe hun hersenscans eruitzien. Deze verschillende metingen — zoals gangbare geheugen- en denkschalen, vragenlijsten over dagelijkse functies en PET-scans van hersenmetabolisme of amyloïdeophoping — worden deels door genen beïnvloed. Belangrijk is dat zij ook deels dezelfde genetische oorzaken delen. Traditionele voorspelmethoden richten zich meestal op één maat tegelijk en laten daarbij het nuttige feit liggen dat deze eigenschappen met elkaar verbonden zijn. De auteurs bepleiten dat modellen, net als een arts die het volledige plaatje ziet in plaats van één testuitslag, van meerdere eigenschappen tegelijk moeten leren.
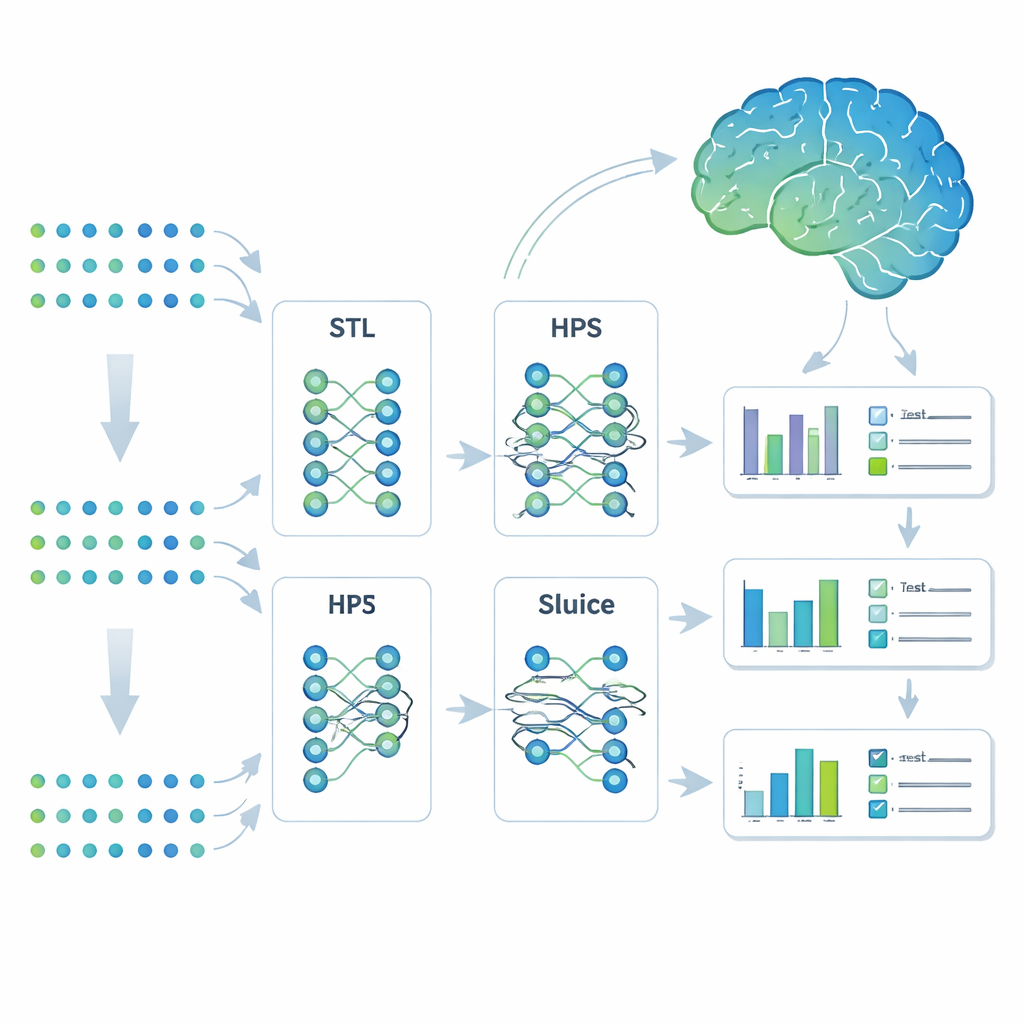
Een model trainen om veel verwante taken te leren
De onderzoekers kozen een machine-learningstrategie die multi-task learning wordt genoemd. In plaats van voor elk uitkomstmaat afzonderlijke modellen te bouwen, trainden ze één systeem om zeven Alzheimer-gerelateerde eigenschappen tegelijk te voorspellen. Ze vergeleken vier benaderingen: volledig afzonderlijke modellen (single-task learning), een eenvoudige gedeelde architectuur die pas aan het einde splitst (hard parameter sharing), een flexibeler vertakkingsontwerp dat taken in subgroepen kan splitsen, en een zeer aanpasbaar ontwerp genaamd het Sluice Network dat precies kan afstemmen hoeveel informatie op elke laag wordt gedeeld. Alle vier de modellen kregen dezelfde genetische invoer; het verschil zat in hoe ze wat ze leerden over de verschillende eigenschappen deelden.
Ideeën testen in gesimuleerde genoomdata
Voordat ze een model aan echte patiënten toevertrouwden, bouwde het team gedetailleerde simulaties met echte genetische patronen afkomstig van het Alzheimer’s Disease Neuroimaging Initiative (ADNI), maar met uitkomsten die ze volledig konden controleren. Ze creëerden scenario’s waarin alle eigenschappen dezelfde genetische oorzaken deelden, waarin eigenschappen overlappende groepen vormden, en waarin elke eigenschap eigen, onderscheidende oorzaken had. Ze varieerden ook hoe sterk de genetische signalen waren en hoeveel ruis ze toevoegden, om de rommelige realiteit van menselijke data na te bootsen. In bijna alle omstandigheden gaf het Sluice Network de meest nauwkeurige voorspellingen en bleef het stabiel, zelfs wanneer eigenschappen slechts zwak gerelateerd waren. Eenvoudiger gedeelde modellen presteerden goed wanneer eigenschappen veel genetische factoren gemeen hadden, maar faalden wanneer die overlap klein was, terwijl volledig afzonderlijke modellen consistent maar over het algemeen minder nauwkeurig waren.
Data uit de echte wereld en de kracht van genetische groepering
De auteurs pasten deze modellen vervolgens toe op echte ADNI-data van 463 personen, met bijna 3.800 genetische markers afkomstig uit 56 genen die eerder aan Alzheimer waren gekoppeld. Hier voegden ze een biologisch geïnspireerde wending toe: in plaats van duizenden individuele genetische markers rechtstreeks in te voeren, groepeerden ze eerst markers per gen en liet het netwerk een compacte "samenvattende" signaalwaarde voor elk gen leren voordat het de zeven uitkomsten voorspelde. Deze aggregatie op gen-niveau verbeterde de prestaties voor de meeste modellen en vooral voor het Sluice Network, dat zijn gemiddelde correlatie met de echte uitkomsten ongeveer verdubbelde. De winst was het duidelijkst voor PET-imagingmetingen en bepaalde cognitieve en functionele scores, wat erop wijst dat subtiele genetische effecten beter detecteerbaar worden wanneer ze op gen-niveau worden gecombineerd in plaats van als geïsoleerde markers te worden behandeld.
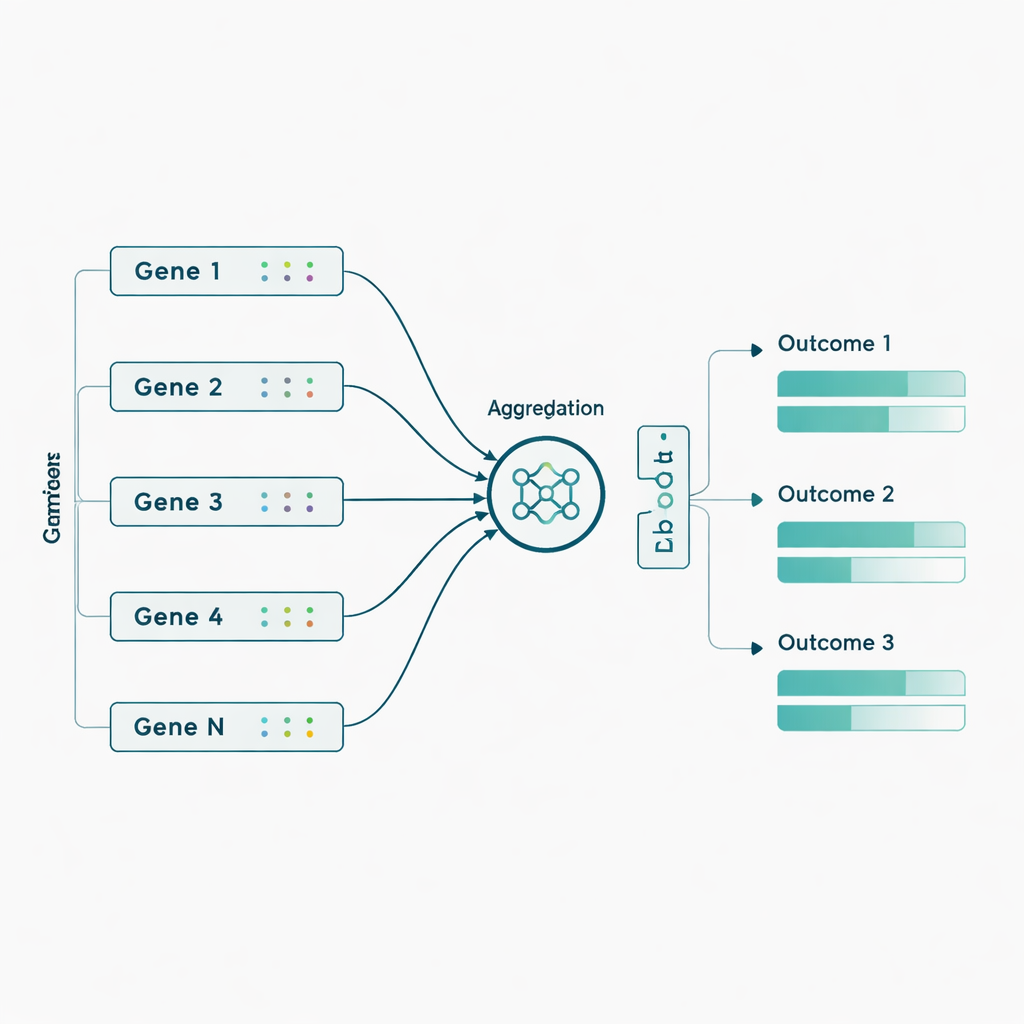
Wat dit betekent voor toekomstige voorspelling en zorg
Voor niet-specialisten is de conclusie dat slimmer, flexibeler AI meer inzicht kan halen uit dezelfde genetische en klinische gegevens door van meerdere verwante uitkomsten tegelijk te leren en rekening te houden met hoe biologie is georganiseerd in genen. Hoewel de huidige verbeteringen bescheiden zijn en nog ver verwijderd van een klinische test, wijst de benadering op meer betrouwbare hulpmiddelen om iemands risicoprofiel in te schatten, waarschijnlijke progressie te volgen en mogelijk toezicht of interventies beter af te stemmen. Bij complexe ziekten zoals Alzheimer, waarin veel kleine genetische effecten op elkaar inwerken, kunnen methoden die informatie over eigenschappen heen delen en zwakke signalen aggregeren een helderder, informatiever beeld bieden dan traditionele één-eigenschap-per-keer-scores.
Bronvermelding: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Trefwoorden: Genetica van de ziekte van Alzheimer, multi-task learning, deep learning-voorspelling, neuroimaging-biomarkers, aggregatie op gen-niveau