Clear Sky Science · nl
Een vergelijkende analyse van de prestaties van grote taalmodellen bij het specialisme tandheelkunde-examen
Waarom slimme chatbots belangrijk zijn voor toekomstige tandartsen
Kunstmatige intelligentie verandert snel hoe artsen en tandartsen leren en werken. Een van de meest zichtbare hulpmiddelen is de conversatiechatbot aangedreven door grote taalmodellen—dezelfde technologie achter veel populaire AI-assistenten. Deze studie stelde een eenvoudige maar belangrijke vraag: als tandheelkundestudenten deze hulpmiddelen zouden gebruiken ter voorbereiding op een zeer competitief specialisme-examen in orale en kaakheelkundige radiologie, hoe goed zouden de machines het dan daadwerkelijk doen?
AI testen met een echt examen
Om dat te bepalen gebruikten de onderzoekers het toelatingsexamen voor tandheelkundige specialisatie (DUS) in Turkije, dat helpt bepalen wie toegang krijgt tot vervolgopleidingen. Uit eerdere jaren van deze landelijke toets selecteerden ze 208 meerkeuzevragen die onderwerpen bestrijken die radiologiespecialisten moeten beheersen, van stralingsfysica en beeldvormingstechnieken tot kaaktumoren en bijholteziekten. De meeste vragen waren alleen tekst, maar een kleiner deel vereiste het interpreteren van radiografische beelden, wat het diagnostische werk in de praktijk weerspiegelt.
Zeven chatbots ondergaan dezelfde uitdaging
Het team stelde vervolgens elke vraag, in het Turks, aan zeven veelgebruikte AI-chatbots gebaseerd op verschillende grote taalmodellen: twee versies van ChatGPT, plus Gemini, Copilot, DeepSeek, Claude en Grok. Elke vraag werd zorgvuldig en afzonderlijk ingevoerd om carry-over tussen gesprekken te voorkomen. Een tweede onderzoeker vergeleek elk AI-antwoord met het officiële antwoordmodel en beoordeelde het als juist of onjuist. Ten slotte gebruikten de auteurs gangbare statistische toetsen om de modellen in het algemeen en binnen specifieke onderwerpgebieden te vergelijken.
Wie scoorde het hoogst—en waar ze struikelden
Onder alle chatbots stak ChatGPT 4.0 er met kop en schouders bovenuit en beantwoorde ongeveer 91 procent van de vragen correct. Copilot en Gemini volgden kort daarop met nauwkeurigheid rond de midden-tot-hoge tachtig procent, terwijl ChatGPT 4.5, DeepSeek, Claude en Grok iets achterbleven. Toen de onderzoekers dieper in de onderwerpen doken, presteerden de modellen bijzonder goed op orale pathologie en speekselklieraandoeningen, waar de nauwkeurigheid de 90 procent naderde of overschreed. Daarentegen waren radiografische anatomie en verkalkingen in zacht weefsel duidelijker moeilijker, wat de scores in verschillende systemen naar beneden trok en aanwijzingen gaf voor gebieden waar AI nog moeite heeft met fijnmazige details.
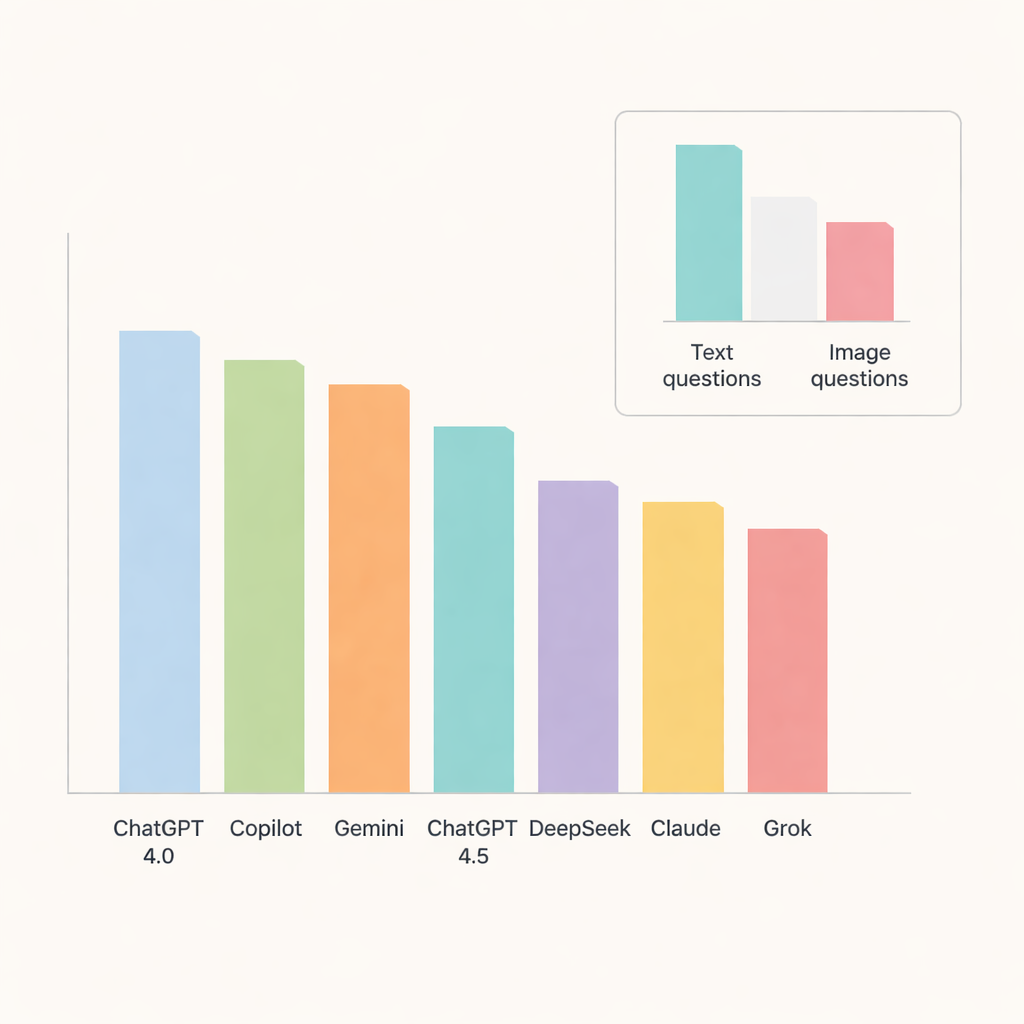
Afbeeldingen blijven lastiger dan tekst
Een cruciale test was of de chatbots afbeeldingen net zo goed aankonden als tekst. Hier werden hun beperkingen duidelijk. De nauwkeurigheid daalde scherp bij beeldgebaseerde vragen, zelfs voor de best presterende modellen. ChatGPT 4.0, Gemini en Copilot leidden deze categorie maar beantwoordden nog steeds slechts ongeveer twee derde van de visuele vragen correct. DeepSeek deed het het slechtst op afbeeldingen, met iets meer dan een derde goed. Voor de meeste modellen was het verschil tussen tekst- en beeldprestaties groot genoeg om statistisch betekenisvol te zijn, wat onderstreept dat het interpreteren van medische beelden een lastige taak blijft voor de huidige algemene AI-systemen.
Wat dit betekent voor studenten en patiënten
De belangrijkste conclusie van de studie is dat moderne chatbots krachtige hulpmiddelen kunnen zijn in de tandheelkundige opleiding, vooral voor het herhalen van feiten en het oefenen met examengerichte vragen in radiologie. Toch maken zelfs de sterkste systemen genoeg fouten—vooral bij visueel veeleisende of zeer specialistische onderwerpen—dat ze niet veilig het oordeel van experts kunnen vervangen. Voor studenten en clinici zijn deze hulpmiddelen het beste te zien als slimme studiepartners of besluitvormingshulpmiddelen, niet als zelfstandige autoriteiten. Bij juist gebruik met passende voorzichtigheid en toezicht kunnen ze het leren versnellen en de toegang tot hoogwaardige uitleg vergroten, terwijl de eindverantwoordelijkheid voor diagnose en behandeling onverminderd bij opgeleide professionals blijft.
Bronvermelding: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Trefwoorden: tandheelkundige opleiding, kunstmatige intelligentie, grote taalmodellen, orale en kaakheelkundige radiologie, medische examens