Clear Sky Science · nl
Cross-lingual SMS-spamdetectie met GAN-gebaseerde augmentatie voor ongebalanceerde datasets
Waarom uw sms’jes nog steeds bescherming nodig hebben
De meesten van ons vertrouwen erop dat ongewenste berichten stilletjes in een spammap belanden, maar achter de schermen is dat een lastig probleem. Echte spam is zeldzaam vergeleken met alledaagse berichten en verschijnt steeds vaker in meerdere talen tegelijk. Dit artikel presenteert een nieuwe manier om gevaarlijke SMS-spam te herkennen door krachtige taalmodellen te combineren met een slimme ‘nepgegevens’-generator, zodat filters van veel meer voorbeelden van schadelijke berichten kunnen leren zonder uw privacy in gevaar te brengen.
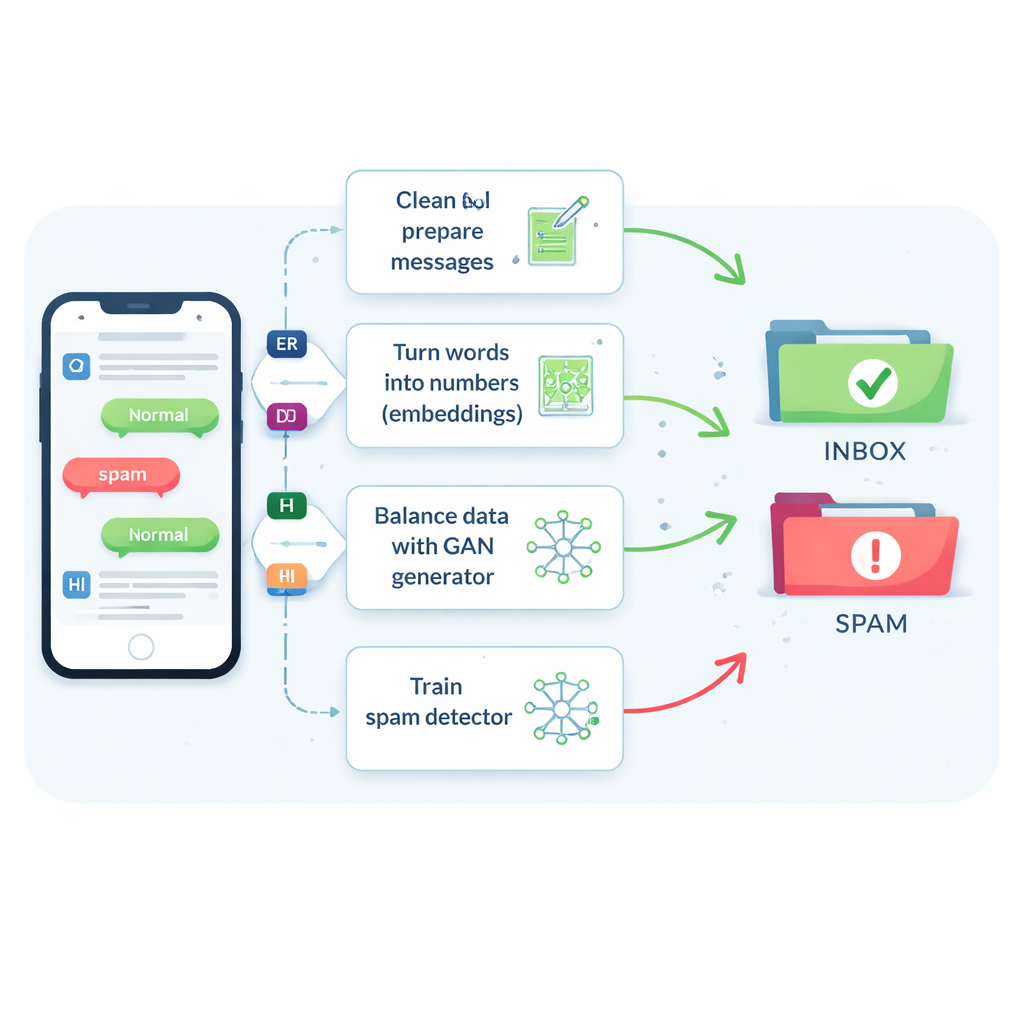
Het probleem van zeldzame en veranderlijke spam
Sms-spam vormt maar ongeveer een op de zeven berichten, maar het missen van zelfs een klein deel ervan kan mensen blootstellen aan oplichting, malware en identiteitsdiefstal. Traditionele filters hebben moeite omdat SMS-berichten kort zijn, vol slang en afkortingen staan en in real time binnenkomen met weinig extra context. Daardoor neigen veel systemen ertoe berichten als veilig te bestempelen, wat gebruikers tevreden houdt maar meer schadelijke berichten doorlaat. Oudere trucs die spamberichten simpelweg dupliceren of nieuwe maken door woorden aan te passen, helpen soms een beetje, maar ze verwarren het filter vaak of creëren onrealistische voorbeelden die niet overeenkomen met wat criminelen daadwerkelijk versturen.
Machines leren berichtbetekenis te begrijpen
De auteurs beginnen met het vergelijken van acht verschillende leeralgoritmen, van bekende tools zoals support vector machines en beslisbomen tot meer geavanceerde neurale netwerken die tekst als een reeks verwerken, zoals long short-term memory (LSTM)-netwerken. Ze testen ook vijf manieren om woorden om te zetten in getallen die een computer kan gebruiken. Eenvoudige tellingen van hoe vaak elk woord voorkomt (bekend als bag-of-words of TF–IDF) zijn snel maar blind voor betekenis. Nieuwere “embeddings” zoals Word2Vec en GloVe plaatsen woorden met vergelijkbare betekenissen dicht bij elkaar in een numerieke ruimte. Het meest geavanceerd zijn transformer-gebaseerde modellen zoals BERT, die de representatie van een woord aanpassen afhankelijk van de omliggende zin, waardoor het systeem bijvoorbeeld een vriendelijke herinnering kan onderscheiden van een overtuigende oplichterij.
Slimme “nep”-spam gebruiken om een scheve dataset te corrigeren
De kerninnovatie is de manier waarop de studie het tekort aan spamexemplaren aanpakt. In plaats van volledige nepzinnen te genereren, traint het team een type neuraal netwerk dat een Generative Adversarial Network (GAN) heet direct op de numerieke embeddings van spamberichten. Een deel van de GAN, de generator, leert synthetische spamachtige punten te creëren in deze hoog-dimensionale ruimte, terwijl een ander deel, de discriminator, leert ze van echte voorbeelden te onderscheiden. Door deze rivaliteit produceert de generator realistische nieuwe spamembeddings die de trainingsset uitbreiden. Een kwaliteitscontrole op basis van gelijkenis zorgt ervoor dat alleen synthetische voorbeelden die sterk op echte spam lijken worden behouden, waardoor het risico op onzinnige data die de classificator kunnen misleiden wordt verminderd.
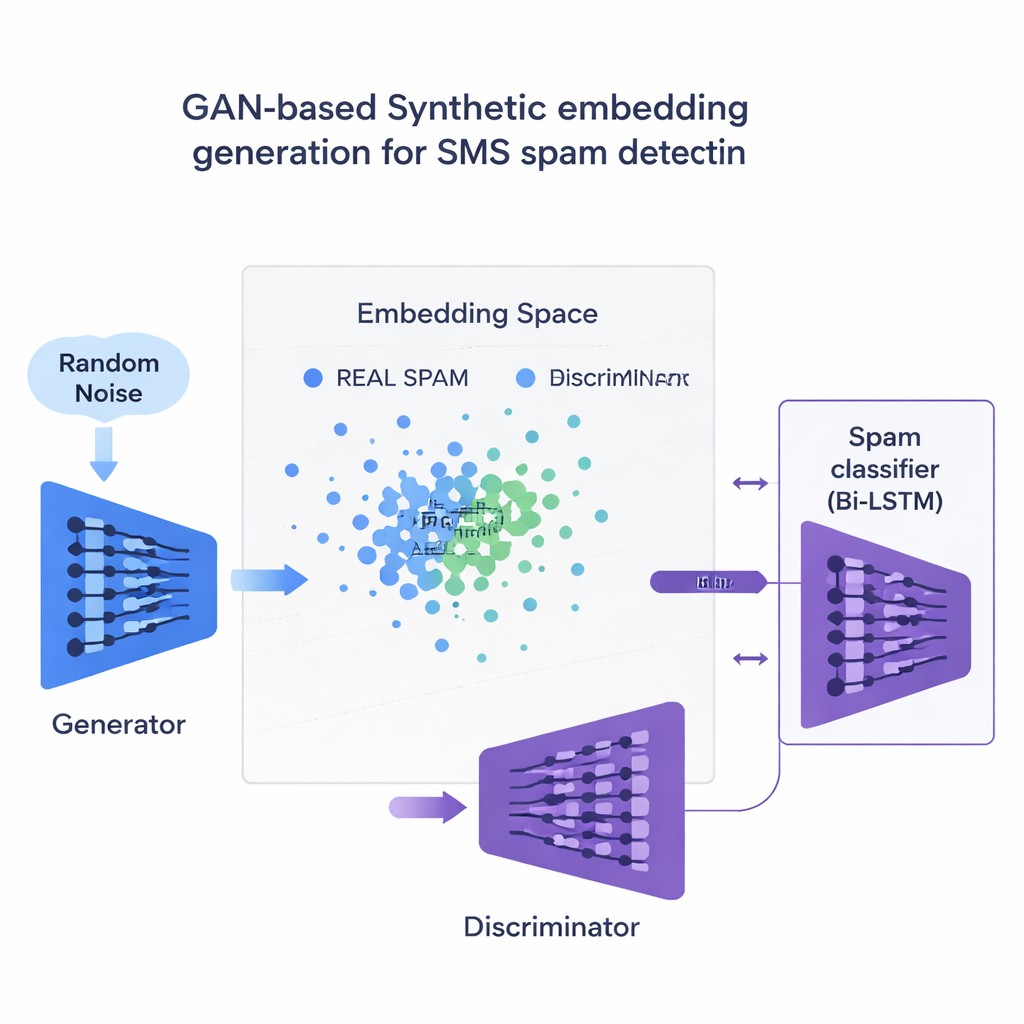
Resultaten over talen en apparaten heen
De onderzoekers testen 120 verschillende combinaties van modellen, embeddings en methoden voor het in balans brengen van data, zowel op een Engelse SMS-dataset als op een meertalige versie vertaald naar Frans, Duits en Hindi. Algemeen presteren contextuele embeddings zoals BERT beter dan oudere woordtellingbenaderingen. De beste opzet — een bidirectionele LSTM gevoed met BERT-embeddings en getraind met door GAN gegenereerde spamexemplaren — bereikt een F1-score rond 97,6% op Engelse berichten en 94,4% op de meertalige set, en overtreft daarmee bestaande state-of-the-art systemen. Belangrijk is dat dit gebeurt terwijl het aantal valse alarmen extreem laag blijft, een cruciale eis zodat eenmalige wachtwoorden en bankmeldingen niet per ongeluk voor gebruikers verborgen worden. De studie vergelijkt deze GAN-strategie ook met meer gebruikelijke balancing-tools zoals SMOTE en ADASYN, en vindt dat de GAN schonere, realistischer trainingsdata produceert en een iets betere algehele prestatie levert.
Wat dit betekent voor alledaagse gebruikers
Voor niet-specialisten is de conclusie dat spamfilters beginnen de betekenis en context van uw berichten te begrijpen, niet alleen individuele woorden, en dat ze kunnen worden “getraind” met zorgvuldig samengestelde synthetische data in plaats van meer van uw echte berichten te zien. Door direct te werken in de ruimte waarin de betekenis van berichten is gecodeerd, geeft de voorgestelde methode beveiligingssystemen een rijker beeld van hoe spam eruitziet in veel talen, zonder ze te overspoelen met lompe neptrucs. Dit vergroot de kans dat gevaarlijke berichten worden opgepikt en echte berichten worden afgeleverd, en biedt zo een sterkere, adaptievere bescherming voor mobiele gebruikers nu oplichters hun tactieken blijven veranderen.
Bronvermelding: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Trefwoorden: SMS-spamdetectie, GAN-gegevensaugmentatie, BERT-tekstrepresentaties, meertalige cyberbeveiliging, mobiele phishing