Clear Sky Science · nl
Een lichtgewicht convolutioneel neuraal netwerkarchitectuur voor het detecteren van geweld in videosequenties
Mensen niet langer continu laten kijken naar menigtes
Van concerten en sportarena's tot metrostations en winkelcentra: camera's houden tegenwoordig bijna elke drukke ruimte in de gaten. Toch worden veel van die videobeelden nog steeds door vermoeide menselijke ogen bekeken, die de eerste signalen van een vechtpartij of paniek gemakkelijk kunnen missen. Dit artikel onderzoekt hoe een slanke, snelle vorm van kunstmatige intelligentie livevideo in realtime kan scannen op gewelddadig gedrag, zelfs op goedkope hardware, en zo beveiligingspersoneel helpt snel te reageren voordat situaties uit de hand lopen.
Waarom geweld op video zo moeilijk te herkennen is
Op het eerste gezicht lijkt het eenvoudig: laat een computer “vechtpartij” onderscheiden van “geen vechtpartij” — detecteer mensen die elkaar slaan. In werkelijkheid is het probleem complex. De verlichting kan slecht zijn of plotseling veranderen, menigten kunnen het zicht blokkeren en camera's hangen op allerlei verschillende hoeken. Een propvol rockconcert lijkt chaotisch, ook als er niets gevaarlijks gebeurt, terwijl een bokswedstrijd gewelddadig oogt maar volkomen normaal is in de ring. Traditionele visiesystemen keken naar handgemaakte bewegingspatronen en randen frame voor frame; hoewel die in het laboratorium werkten, waren ze in drukke, realistische bewakingsnetwerken vaak te traag of niet nauwkeurig genoeg.
Een slimmere, compacte ‘hersenen’ voor camerabeelden
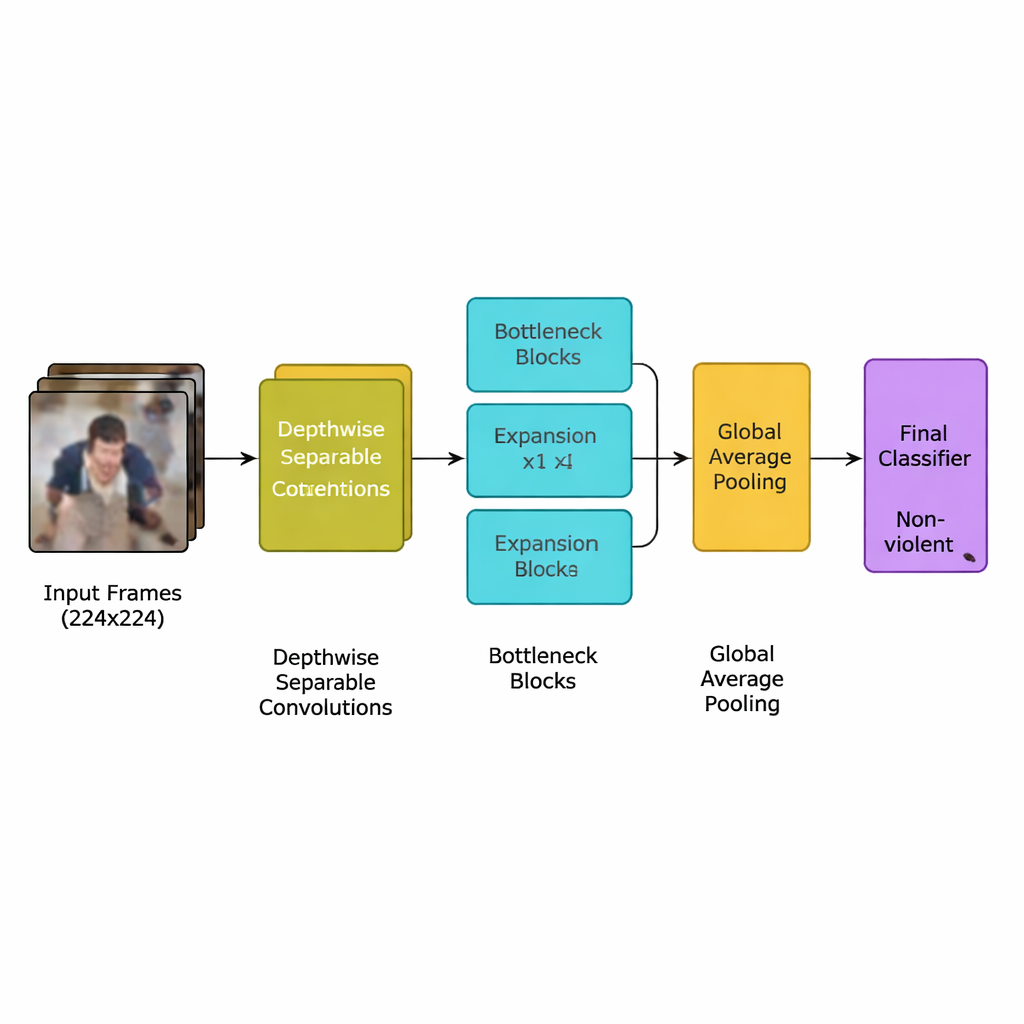
De auteurs presenteren een nieuw deep‑learningmodel dat specifiek voor deze taak is ontworpen: een lichtgewicht convolutioneel neuraal netwerk (CNN) afgeleid van een efficiënte modelfamilie bekend als MobileNetV2. In plaats van veel zware lagen te gebruiken die krachtige grafische processors vereisen, berust het netwerk op depthwise separable convolutions — kleine, gerichte berekeningen die het aantal bewerkingen drastisch verminderen. Het gebruikt ook zogenaamde “inverted bottleneck”-blokken, die informatie kort uitbreiden en vervolgens comprimeren om belangrijke bewegingssignalen te behouden en redundantie te verwijderen. Daarbovenop voegt het team een aandachtmechanisme toe, squeeze‑and‑excitation genoemd, dat het netwerk helpt te focussen op ruimtelijke en temporele bewegingspatronen die typisch zijn voor gewelddadige incidenten, terwijl afleidende achtergronddetails worden genegeerd.
Van ruwe video naar geweldswaarschuwingen
Het volledige systeem volgt een helder stappenplan. Eerst worden videostreams opgesplitst in frames, en wordt alleen elk vijfde frame bewaard om bijna‑duplicaten te verwijderen en toch plotselinge bewegingen te behouden die vaak op een vechtpartij wijzen. Frames worden herschaald naar een standaard van 224×224 pixels, licht vervaagd om achtergrondruis te verminderen, en tijdens training willekeurig gespiegeld of geroteerd zodat het model leert omgaan met verschillende camerahoeken. Deze voorbereide afbeeldingen voeden het lichtgewicht CNN, dat geleidelijk ruwe pixels omzet in hogere‑niveau patronen van menigtegedrag. Na een laatste poolingstap die elk frame samenvat, geeft een kleine classifier een eenvoudige beslissing: gewelddadig of niet‑gewelddadig. Omdat het model slechts ongeveer 1,94 miljoen parameters gebruikt — minder dan zijn MobileNet- en MobileNetV2‑voorgangers — kan het realtime draaien op bescheiden apparaten die dicht bij de camera's worden geplaatst in plaats van in een verre datacenter.
Het systeem op de proef stellen
Om te onderzoeken of dit compacte ontwerp kon concurreren met zwaardere netwerken, trainden en evalueerden de onderzoekers het op twee veelgebruikte benchmarks. De Real‑Life Violence Situations Dataset bevat 2.000 korte clips van YouTube met zowel alledaagse scènes als echte vechtpartijen op verschillende locaties. De Hockey Fight Dataset bevat 1.000 clips van professionele ijshockeywedstrijden, verdeeld tussen gewoon spel en vechtpartijen op het ijs. Op deze datasets labelde het voorgestelde model ongeveer 97 procent van de clips in realistische situaties correct en 94 procent in hockeybeelden, waarmee het grotere CNN's zoals InceptionV3 en VGG‑19 evenaarde of overtrof terwijl het veel minder rekencapaciteit gebruikte. Cross‑testing tussen de twee datasets — trainen op de ene en testen op de andere — liet zien dat het systeem nog steeds redelijk goed presteerde, wat suggereert dat het algemene bewegingspatronen vastlegt in plaats van één omgeving te memoriseren.
Wat dit betekent voor de dagelijkse veiligheid
Voor niet‑experts is de belangrijkste conclusie dat het nu mogelijk is camerasystemen te bouwen die waarschijnlijk geweld snel en goedkoop signaleren, zonder enorme servers of constante menselijke aandacht. De studie toont aan dat een zorgvuldig afgeslankt en afgestemd neuraal netwerk veel streams tegelijk kan bekijken, waarschuwingen kan verzenden bij detectie van gevaarlijk gedrag en toch kan draaien op energiezuinige hardware die geschikt is voor openbaar vervoer, scholen, ziekenhuizen en stadsstraten. Hoewel uitdagingen blijven — zoals het omgaan met zeer donkere scènes, extreme drukte of het toevoegen van geluidssignalen — wijst dit werk op een toekomst waarin slimme camera's fungeren als onvermoeibare vroegwaarschuwingssensoren, waardoor beveiligingsteams mensen effectiever kunnen beschermen en de last op menselijke toezichthouders wordt verminderd.
Bronvermelding: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Trefwoorden: gewelddetectie, videobewaking, lichtgewicht CNN, MobileNetV2, openbare veiligheid