Clear Sky Science · nl
MSRCTNet: een nieuw multi-schaal capsule-tripletnetwerk voor efficiënte verwijdering van redundante frames in draadloze capsule-endoscopievideo's
Een camera doorslikken, verdrinken in beelden
Stel je voor dat je darmaandoeningen diagnosticeert door een vitaminegrote camera door te slikken die stilletjes je hele spijsverteringskanaal fotografeert. Draadloze capsule-endoscopie maakt dit al mogelijk, maar elk onderzoek levert ongeveer 55.000 beelden op, waarvan de meeste bijna hetzelfde lijken. Artsen moeten door deze visuele stortvloed zoeken naar kleine vlekjes bloed, ontsteking of tumoren. De studie achter MSRCTNet stelt een eenvoudige maar cruciale vraag: kan een intelligent systeem veilig de sterk gelijkende frames weggooien, zodat artsen alleen zien wat echt belangrijk is?
Waarom te veel foto’s problematisch kan zijn
Conventionele endoscopie vereist een flexibele buis die via mond of rectum wordt ingebracht, een procedure die veel patiënten onaangenaam vinden en die niet altijd het hele dunne darmkanaal bereikt. Capsule-endoscopie lost dit op door een pilcamera door de darm te laten drijven die elke seconde een foto maakt. Het nadeel is overbelasting: slechts ongeveer 1% van de frames bevat duidelijk bruikbare informatie, terwijl de rest veelal dezelfde plooien weergaf. Het doorzoeken van zulke hoeveelheden is traag en vermoeiend, wat het risico vergroot dat een uitgeputte clinicus een subtiel letsel mist. Eerdere computermethoden probeerden te helpen door vergelijkbare frames te clusteren, data te comprimeren of te vertrouwen op eenvoudige kleur- en textuursignalen, maar ze faalden vaak bij veranderende belichting, complexe darmbewegingen of wanneer zeldzame afwijkingen slechts in een paar voorbeelden voorkwamen.
Een slimmer manier om herhaling te herkennen
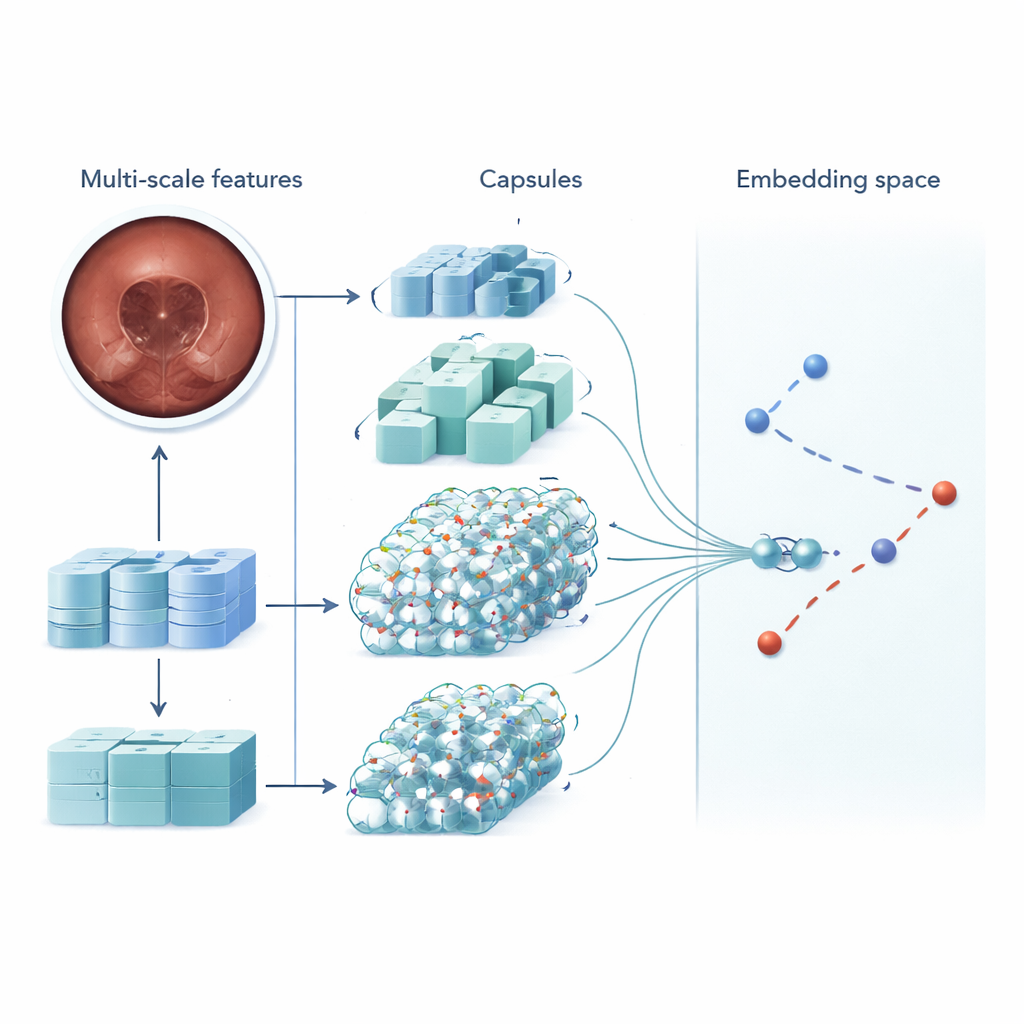
MSRCTNet (Multi-Scale Capsule Triplet Network) is een deep-learning systeem dat is ontworpen om als intelligente filter voor capsulevideo’s te fungeren. In plaats van elk beeld als een plat plaatje te behandelen, bekijkt het systeem patronen op meerdere schalen tegelijk — fijne texturen van het darmslijmvlies en bredere vormen van de darmwand — en gebruikt het een attentiemechanisme om de meest informatieve details te benadrukken. Deze verrijkte kenmerken worden vervolgens doorgegeven aan een capsule-achtige laag die bewaart hoe delen van het beeld ruimtelijk tot elkaar verhouden, zoals de oriëntatie en rangschikking van plooien of laesies. Ten slotte vergelijkt een gespecialiseerd similariteitsmodule triplets van frames — één referentiebeeld, één dat vergelijkbaar zou moeten zijn en één dat verschillend zou moeten zijn — om een representatie te leren waarin echt redundante frames strak clusteren en onderscheidende frames uit elkaar blijven staan.
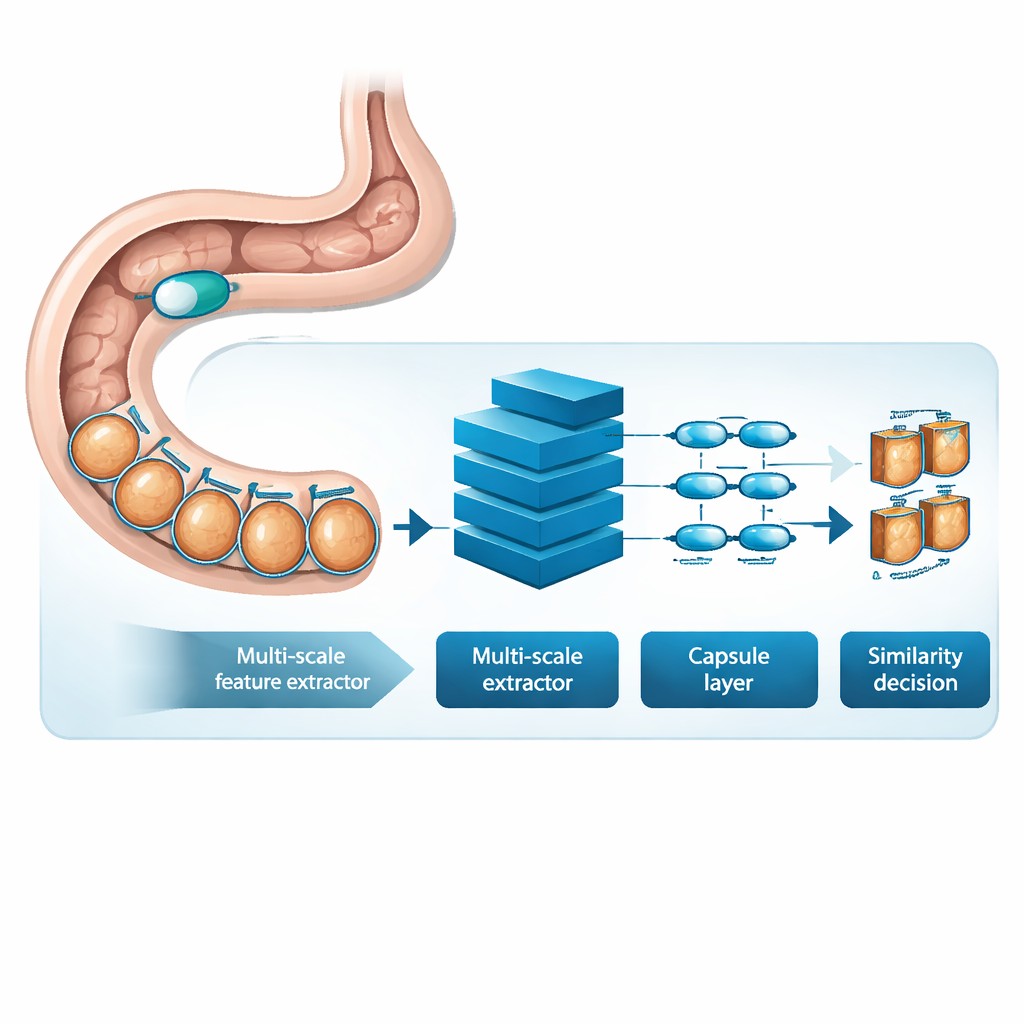
Leren van echte patiëntonderzoeken
Om MSRCTNet te testen, verzamelden de onderzoekers een grote dataset van 257.362 beelden uit 60 capsuleonderzoeken uitgevoerd in een ziekenhuis in China. De beelden omvatten normaal weefsel, door bellen verstoorde regio’s en duidelijke afwijkingen zoals bloedingen en ontstekingen, allemaal gelabeld door ervaren clinici. Het systeem werd getraind om te beoordelen of paren frames vergelijkbaar waren of niet, met een combinatie van twee leerdoelen: één die frames van dezelfde categorie naar elkaar toe trekt en frames van verschillende categorieën uit elkaar duwt, en een andere die het netwerk direct leert te zeggen of een paar vergelijkbaar is. Nadat het getraind was, bekijkt het model een video drie frames tegelijk en besluit welke van de nabije beelden echt redundant zijn. Door eenvoudige regels toe te passen op deze vergelijkingsbeslissingen, verwijdert het herhaalde weergaven en behoudt het representatieve sleutelbeelden.
Snelheid, nauwkeurigheid en minder gemiste problemen
Op de testdata hanteerde MSRCTNet redundantie correct in ongeveer 96% van de gevallen, met een false-alarmrate onder 3% en een gemist-framepercentage van minder dan 0,2%. In de praktijk betekent dit voor een onderzoek met 50.000 frames dat er minder dan 100 mogelijk relevante frames worden gemist — klein genoeg dat omliggende beelden nog context bieden bij zes frames per seconde. Vergeleken met verschillende eerdere technieken gebaseerd op clustering, bewegingsanalyse of eenvoudigere neurale netwerken was MSRCTNet zowel nauwkeuriger als robuuster wanneer de data uit balans waren, dat wil zeggen wanneer normale beelden zeldzame laesies ver overtroffen. Het systeem draaide ook snel: ongeveer 0,02 seconden per frame, of ongeveer 15 minuten om een volledig onderzoek terug te brengen tot ongeveer 2.500 sleutelbeelden, een volume dat veel beter beheersbaar is voor menselijke beoordeling.
Wat dit betekent voor patiënten en artsen
Voor patiënten verandert de vooruitgang beschreven in dit artikel de capsule die ze doorslikken niet, maar het kan hun onderzoek effectiever maken. Door automatisch bijna-duplicaatbeelden te trimmen zonder handmatig ingestelde drempels of kwetsbare heuristieken, stelt MSRCTNet clinici in staat zich te concentreren op een beknopte, informatie-rijke samenvatting van de reis door de darm. De benadering behoudt klinisch belangrijke bevindingen terwijl vermoeidheid en leestijd op het consolescherm worden verminderd, waardoor niet-invasieve capsuleonderzoeken mogelijk aantrekkelijker en breder inzetbaar worden. In wezen verandert de methode een stortvloed aan foto’s in een zorgvuldig samengestelde highlights-collectie, en brengt daarmee de belofte van kunstmatige intelligentie een stap dichter bij de dagelijkse zorg voor spijsverteringsziekten.
Bronvermelding: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Trefwoorden: draadloze capsule-endoscopie, medische videosamenvatting, deep learning, verwijdering van redundante frames, gastro-intestinale beeldvorming