Clear Sky Science · nl
DNS‑vingerafdruk gebaseerd op gebruikersactiviteit
Waarom uw webbezoeken een verborgen spoor achterlaten
Elke keer dat u op internet surft, vraagt uw computer stilletjes een speciaal soort adresboek, het Domain Name System (DNS), hoe hij een bepaalde site kan bereiken. Die vragen verdwijnen niet zomaar. Over dagen en weken vormen ze een patroon van welke soorten sites u bezoekt, wanneer en hoe vaak. Dit artikel toont aan dat die patronen onderscheidend genoeg zijn om te fungeren als een gedragsvingerafdruk, waardoor krachtige algoritmen gebruikers van elkaar kunnen onderscheiden — zelfs als hun zichtbare IP‑adres verandert — wat zowel kansen voor beveiliging als serieuze privacyvragen oproept.
De telefoonlijst van het internet en uw gewoonten
DNS bestaat om mensleesbare webadressen, zoals www.google.com, te vertalen naar de numerieke IP‑adressen die computers gebruiken om met elkaar te communiceren. De meeste mensen staan er niet bij stil, maar elke zoekopdracht, videostream, e‑mailcontrole of app‑update veroorzaakt één of meer DNS‑vragen. Deze queries worden gewoonlijk afgehandeld door lokale of openbare DNS‑servers en gelogd als eenvoudige records: welk IP‑adres vroeg naar welk domein en wanneer. Verzamel genoeg van deze records en u krijgt een gedetailleerd beeld van op welke online diensten een gebruiker vertrouwt, van zakelijke tools en cloudopslag tot sociale netwerken en streamingplatforms. Terwijl eerder onderzoek deze sporen gebruikte om malware te detecteren of apparaattype te identificeren, stelt deze studie een directere vraag: kunnen ze individuele gebruikers of machines identificeren puur op basis van hun terugkerende DNS‑gedrag?
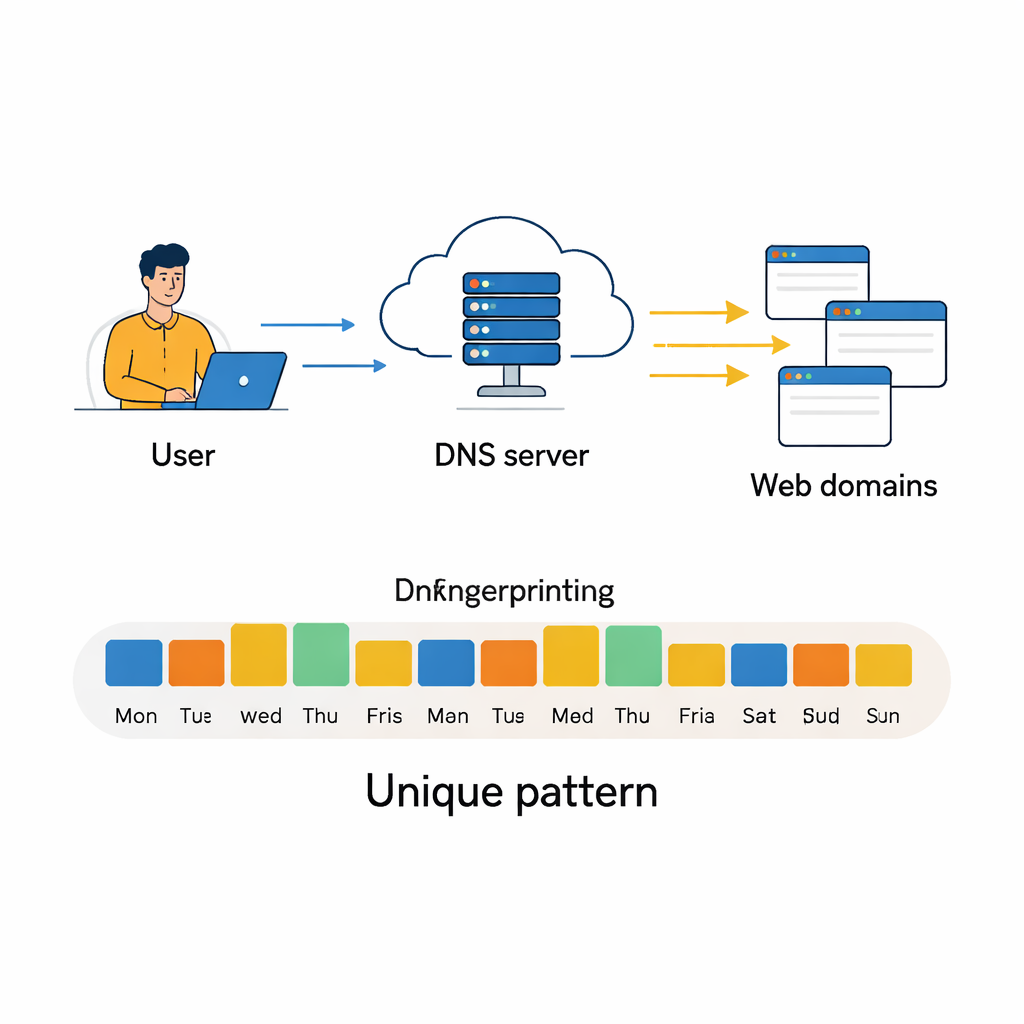
Dagelijkse klikken omzetten in een gedragsvingerafdruk
De auteurs bouwen voort op een grote, openbaar beschikbare DNS‑dataset die gedurende drie maanden is verzameld bij een lokale internetprovider. Elke dag aggregeren zij de DNS‑activiteit voor elk actief IP‑adres tot een compacte samenvatting: aantallen totale queries, hoeveel verschillende domeinen werden geraadpleegd en, cruciaal, hoe die domeinen verdeeld zijn over 75 inhoudscategorieën zoals “Algemene Zaken”, “Software / Hardware” of “Sociale Netwerken.” Ze bewaren alleen IP‑adressen die op minstens 80 procent van de dagen voorkomen, waardoor er voldoende geschiedenis per gebruiker is, en verwijderen zorgvuldig redundante of vrijwel lege kenmerken. Ze passen ook statistische hulpmiddelen toe om sterk gecorreleerde velden te detecteren, filteren extreme uitschieters in query‑volume weg en comprimeren de data vervolgens met hoofdcomponentenanalyse zodat de meeste nuttige variatie behouden blijft in veel minder dimensies. Bij visualisatie van de opgeschoonde data met een techniek genaamd t‑SNE zien ze dat veel IP‑adressen compacte, goed gescheiden clusters vormen — een vroeg teken dat automatische classificatie haalbaar kan zijn.
Machine‑learningmodellen aan de tand voelen
Met deze verwerkte dataset behandelt het team gebruikersidentificatie als een enorme classificatieopgave: gegeven één dag DNS‑statistieken, beslis bij welk van de 1.727 IP‑adressen het hoort. Ze vergelijken een reeks modellen, van klassieke methoden zoals Naive Bayes en Random Forests tot geavanceerdere tools zoals XGBoost en diepe neurale netwerken. Elk model wordt getraind en gevalideerd op verschillende versies van de data (onbewerkt, hergeschaald, gestandaardiseerd of dimensieverkleind) en geëvalueerd op hoe vaak het correct de juiste klasse toewijst, samen met maten voor precisie en recall. Traditionele modellen presteren redelijk goed — Random Forests behalen ongeveer 73 procent nauwkeurigheid, en XGBoost overtreft 81 procent terwijl het meer dan 99 procent van alle klassen correct onderscheidt. Maar de uitschieters zijn de neurale netwerken, vooral een op maat gemaakte convolutionele neurale netwerk (CNN) dat de featurevector behandelt als een eendimensionale afbeelding van dagelijks gedrag.
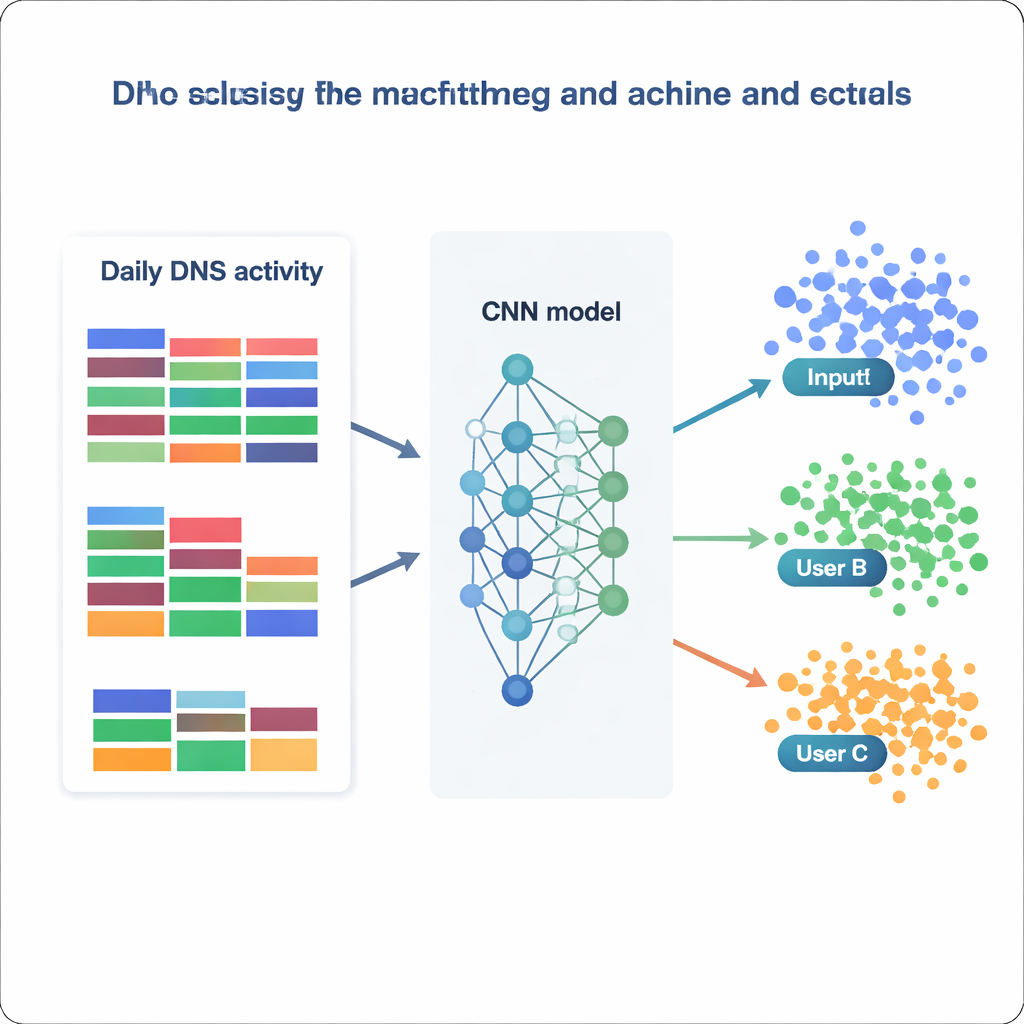
Hoe goed kan een model weten “wie” u bent?
Het beste CNN, getraind op genormaliseerde data, identificeert het bron‑IP correct op bijna 87 procent van de gehouden‑uit dagen en voorspelt succesvol 1.694 van de 1.727 verschillende IP‑adressen. In praktische termen betekent dit dat de meeste gebruikers — of kleine groepen die zich achter een gedeeld IP verbergen — stabiele, herkenbare DNS‑patronen over tijd vertonen. Door te onderzoeken op welke kenmerken de modellen het meest vertrouwen, vinden de auteurs twee aanvullende strategieën. Sommige modellen leunen sterk op zeer algemene categorieën, zoals algemene zakelijke of softwarediensten, en leggen daarmee brede gewoonten vast. Andere modellen, zoals XGBoost, winnen extra kracht uit zeldzame maar veelzeggende categorieën die verband houden met beveiliging, politiek of niche‑interesses. Gezamenlijk tonen deze resultaten aan dat zelfs simpele, geaggregeerde statistieken — zonder naar de volledige lijst met domeinnamen te kijken — voldoende structuur kunnen coderen om gebruikers met opvallende betrouwbaarheid te heridentificeren.
Belofte, beperkingen en privacybelangen
Voor wetshandhaving en netwerkverdedigers kunnen DNS‑vingerafdrukken een waardevol instrument worden om recidivisten op te sporen, gecompromitteerde machines te detecteren of botnets te identificeren die van IP‑adres wisselen om blokkering te ontlopen. Tegelijkertijd benadrukt de studie duidelijke beperkingen: DNS‑vingerafdrukken zijn het meest stabiel wanneer een publiek IP aan een enkele gebruiker is gekoppeld, wat realistischer is in moderne IPv6‑netwerken dan in het huidige IPv4‑landschap waar veel gebruikers één adres delen via NAT. Regelmatig wisselen van DNS‑servers of gebruik van openbaar Wi‑Fi verzwakt het signaal eveneens. Het belangrijkste is dat het werk een privacyrisico onderstreept dat voor gewone gebruikers moeilijk te zien is. Omdat DNS‑logging grotendeels onzichtbaar en passief is, kan gedragsmatige tracking plaatsvinden zonder cookies te installeren of indringende scripts. De auteurs publiceren hun dataset en modellen openlijk en betogen dat transparant onderzoek nodig is, zodat de samenleving de beveiligingsvoordelen van DNS‑gebaseerde vingerafdrukken kan afwegen tegen hun potentieel voor stille surveillance en kan beslissen welke beschermingen en beleidsregels deze krachtige nieuwe vorm van online identificatie moeten reguleren.
Bronvermelding: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Trefwoorden: DNS‑vingerafdrukken, gebruikerstracking, internetprivacy, netwerkbeveiliging, machine learning