Clear Sky Science · nl
Beeldverwerkingspipeline voor AI-gestuurde karakterisering van nanopartikel-megabibliotheken
Waarom kleine deeltjes grote datahulp nodig hebben
De moderne materiaalkunde steunt steeds vaker op het maken en testen van enorme aantallen kleine deeltjes om betere katalysatoren, batterijen en andere geavanceerde materialen te vinden. Nieuwe methoden kunnen inmiddels miljoenen verschillende nanopartikels op één chip laten groeien, maar het controleren van de kwaliteit van elk van die deeltjes met een microscoop levert veel meer beelden op dan een mens redelijke kan beoordelen. Dit artikel beschrijft hoe onderzoekers een geautomatiseerde beeldverwerkings- en AI-pijplijn bouwden die snel “goede” van “slechte” nanopartikelbeelden sorteert, rekenkosten verlaagt en experimenten versnelt terwijl de beslissingen zeer betrouwbaar blijven.
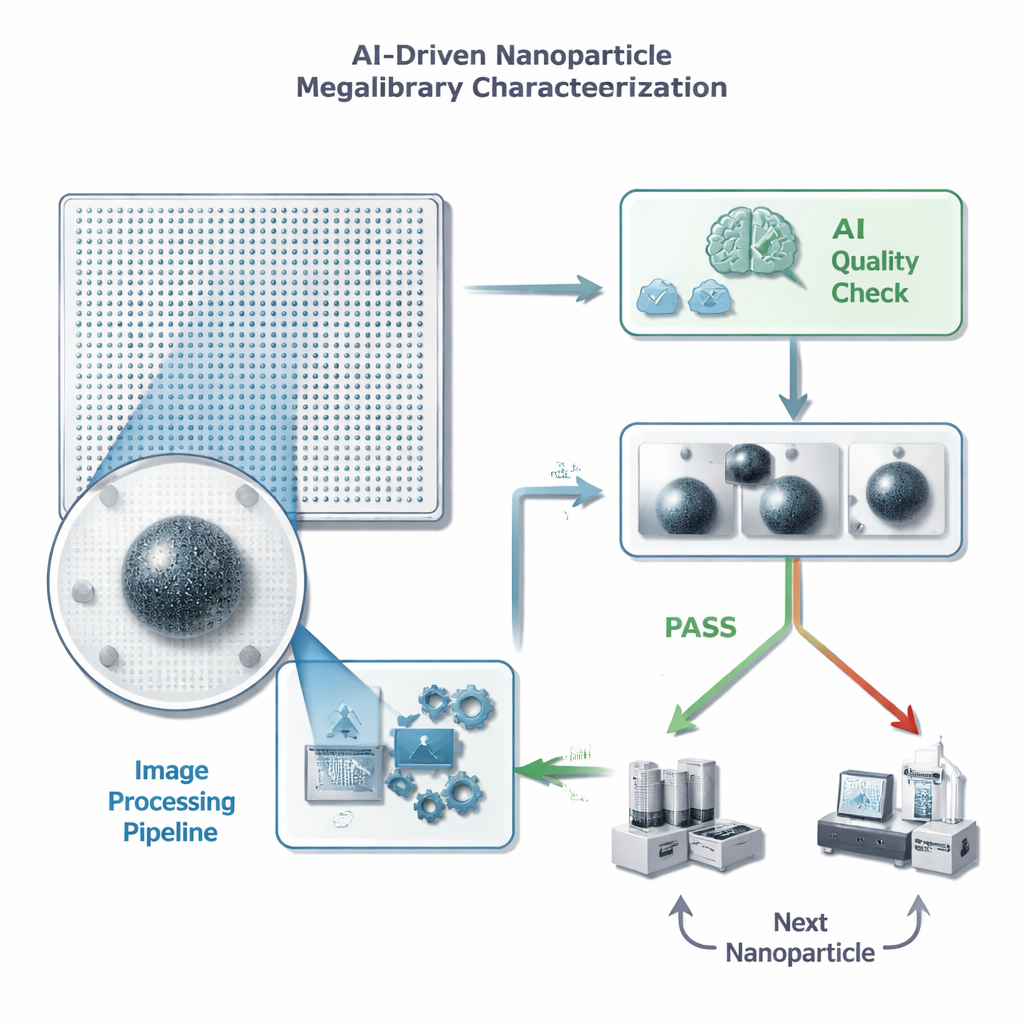
Van eindeloze beelden naar snelle beslissingen
Elk nanopartikel in een "megalibrary"-chip bevindt zich op een bekende positie en kan met een elektronenmicroscoop worden afgebeeld. Voordat wetenschappers tijd en dure vervolgmetingen in één deeltje investeren, hebben ze een snelle kwaliteitscontrole nodig: is er precies één goed gefocust deeltje in kader, zonder storende rommel of artefacten? De auteurs formuleren dit als een eenvoudige slaag-/faaltaak voor een machine-learningmodel, maar met strikte limieten aan de tijd die per afbeelding besteed mag worden—minder dan een halve seconde, omdat één chip miljoenen deeltjes kan bevatten. Ze benadrukken ook dat false positives bijzonder schadelijk zijn: als de AI per ongeluk een slecht beeld doorlaat, verspilt dat tijd en opslag aan nutteloze gedetailleerde metingen, terwijl het af en toe missen van een goed deeltje minder schadelijk is voor de algehele voortgang.
Het beeld schoonmaken voordat de AI kijkt
In plaats van ruwe, ruisige microscoopbeelden direct in een groot, complex neuraal netwerk te gooien, ontwierp het team een aangepaste beeldverwerkingspijplijn die de afbeeldingen eerst "opschoont". De pijplijn verwijdert achtergrondruis, verscherpt randen, croppt nauw rond het deeltje en verkleint daarna de afbeelding tot een veel kleinere afmeting. Cruciaal is dat deze voorbewerking vage kenmerken beter zichtbaar maakt en het uiterlijk nabootst van een grotere vergroting zonder het monster opnieuw te hoeven afbeelden. Het resultaat is een compacte, hoogcontrastafbeelding die aan een relatief eenvoudig neuraal netwerk gevoed kan worden, wat zowel trainingstijd als opslagbehoefte vermindert terwijl de relevante details voor kwaliteitsbeoordelingen behouden blijven.
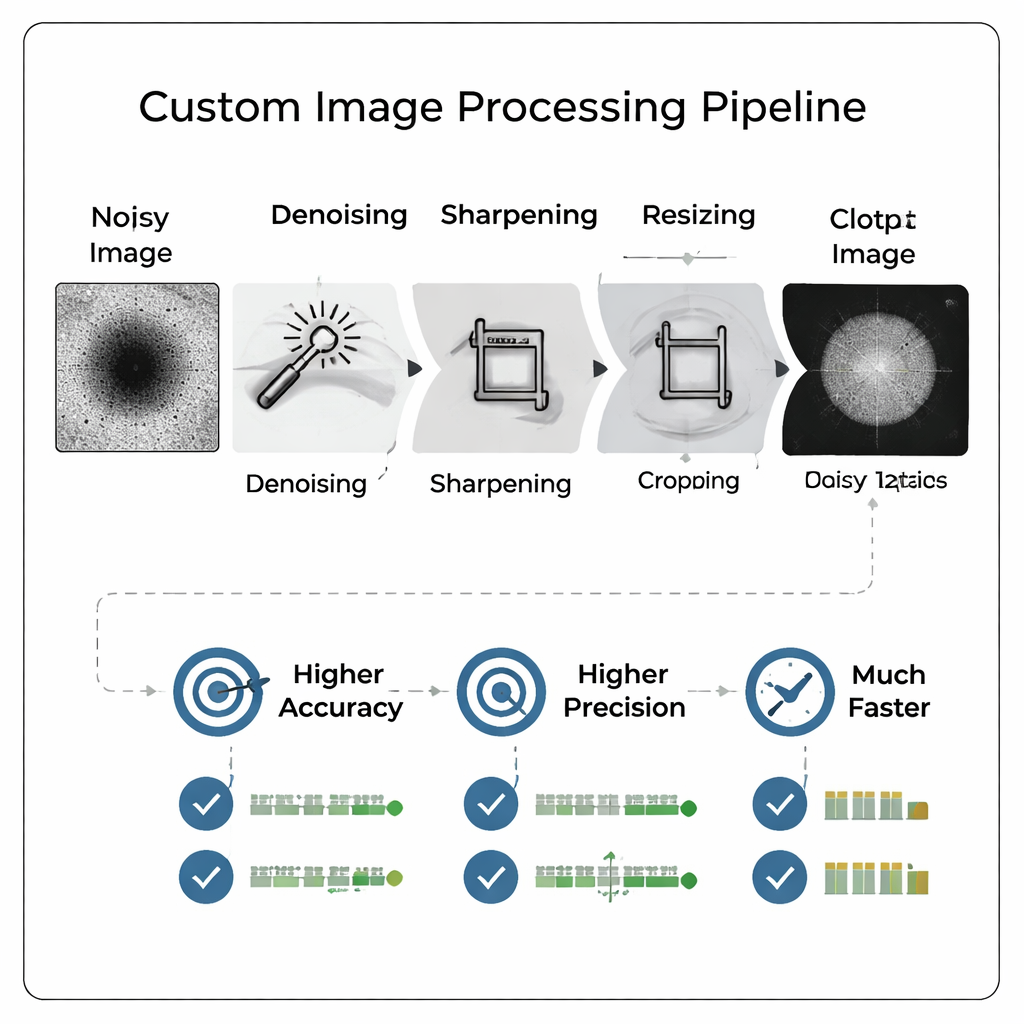
Slimmere afbeeldingen verslaan grotere modellen
De onderzoekers vergeleken systematisch veel pijplijnvarianten en resoluties en trainden uiteindelijk 800 verschillende modellen om te onderzoeken hoe afbeeldingsgrootte en -verwerking de prestaties beïnvloeden. Ze ontdekten dat zorgvuldig verwerkte beelden met bescheiden resoluties (zoals 128×128 pixels) een klein convolutioneel neuraal netwerk lieten presteren beter dan een eerder, veel groter model dat was gevonden door een geautomatiseerde architectuurzoektocht en getraind op volledige 512×512-beelden. De nauwkeurigheid verbeterde met meer dan 13 procentpunten, terwijl recall—het vermogen om goede deeltjes correct te vinden—met meer dan 18 procentpunten toenam. Precision, de belangrijkste maatstaf om verspilde inspanning aan slechte deeltjes te vermijden, bereikte ongeveer 96 procent, en de gecombineerde prestatiemaatstaf die de auteurs prefereren verbeterde eveneens.
Meer doen met veel minder data
Een van de meest opvallende resultaten is dat verwerking belangrijker blijkt dan ruwe afbeeldingsgrootte. Wanneer het team modellen vergeleek die getraind waren op eenvoudigweg "alleen verkleinde" beelden versus beelden die door de volledige aangepaste pijplijn waren gegaan, wonnen de verwerkte beelden consequent—zelfs wanneer ze werden verkleind tot extreem kleine afmetingen zoals 16×16 pixels. In feite versloeg het beste model dat verwerkte 16×16-beelden gebruikte het beste model dat onbewerkte 128×128-beelden gebruikte op bijna alle maatstaven. De pijplijn hielp ook het meest bij lagere microscoopvergrotingen, waar beelden normaal gesproken moeilijker te interpreteren zijn. Omdat beelden bij lagere vergroting sneller te maken zijn, kunnen labs chips sneller scannen zonder in te boeten op de kwaliteit van beslissingen.
Snellere beslissingen voor zelfsturende laboratoria
Door slimme beeldverwerking te combineren met een slank AI-model verkortten de auteurs de trainingstijden van vele uren op een supercomputer naar minder dan een minuut op één grafische processor. Eenmaal getraind kan het systeem een nieuwe afbeelding verwerken en classificeren in ongeveer 75 milliseconden, ruim onder de 500-millisecundedoelstelling en veel sneller dan een menselijke beoordelaar. In praktische termen vertaalt dit zich naar snelle, betrouwbare screening van nanopartikel-megabibliotheken, waardoor onderzoekers dure instrumenten op de veelbelovendste kandidaten kunnen richten. Nu labs steeds meer richting geautomatiseerde, "zelfsturende" ontdekkingssystemen gaan, bieden benaderingen als deze—schoon eerst de data, en pas dan gestroomlijnde AI toe—een krachtige manier om overweldigende stroom aan beelden om te zetten in bruikbare wetenschappelijke inzichten.
Bronvermelding: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Trefwoorden: nanodeeltjes, beeldverwerking, machine learning, materiaalontdekking, elektronenmicroscopie