Clear Sky Science · nl
Onderzoek naar plug-and-play modules voor het verbeteren van labelcorrelaties in deep multi-label learning
Machines leren omgaan met te veel labels
Webshops, juridische archieven en medische databases zijn afhankelijk van software die nieuwe documenten snel van de juiste labels kan voorzien. Moderne systemen hebben echter vaak te maken met tienduizenden of zelfs miljoenen mogelijke labels—van productcategorieën tot medische onderwerpen—terwijl elk document slechts een handvol labels nodig heeft. Dit artikel introduceert een nieuwe toevoeging, de Label Correlation Enhancement Network (LCENet), die bestaande deep-learningmodellen helpt beter gebruik te maken van de manier waarop labels in echte data samen voorkomen, wat leidt tot nauwkeuriger en sneller taggen van tekst.
Waarom labelen op webschaal zo moeilijk is
Veel toepassingen in de praktijk vallen onder wat onderzoekers extreme multi-label tekstclassificatie noemen: gegeven een korte omschrijving of lang document moet het systeem een klein deel relevante labels kiezen uit een enorme catalogus. Voorbeelden zijn het toekennen van categorieën aan producten op een e-commercesite, het indexeren van biomedische artikelen met MeSH-termen, het matchen van advertenties met webpagina’s of het koppelen van juridische teksten aan gedetailleerde wetsartikelen. Deze situaties delen drie uitdagingen: de lijst met labels is extreem groot, de meeste labels zijn zeldzaam en elk document gebruikt maar een paar labels. Traditionele technieken splitsen het probleem vaak in veel kleine classificatoren of comprimeren labels naar lagere-dimensionale vectoren, maar ze vertrouwen vaak op eenvoudige woordtellingen en kunnen betekenis of relaties tussen labels niet volledig vastleggen.
Wat standaard deep-modellen nog missen
Moderne deep-learningbenaderingen, zoals convolutionele netwerken, recurrente netwerken en Transformer-gebaseerde modellen zoals BERT, hebben het tekstbegrip sterk verbeterd door rijke semantische representaties te leren. Toch maken bijna al deze modellen een cruciale vereenvoudiging in de laatste stap: zodra de tekst is gecodeerd als een vector, voorspellen ze elk label onafhankelijk. In de praktijk beïnvloeden labels elkaar echter sterk. Een medisch artikel met het label “diabetes” gaat waarschijnlijk ook over “insulineresistentie”, en een apparaat gelabeld als “smartphone” is meestal gerelateerd aan “elektronica” en “communicatieapparaten.” Door deze patronen te negeren, kunnen modellen hoge-zekerheidslabels niet gebruiken om zwakkere labels te ondersteunen en kunnen ze combinaties geven die inhoudelijk niet kloppen.
Een plug-in die labelrelaties leert
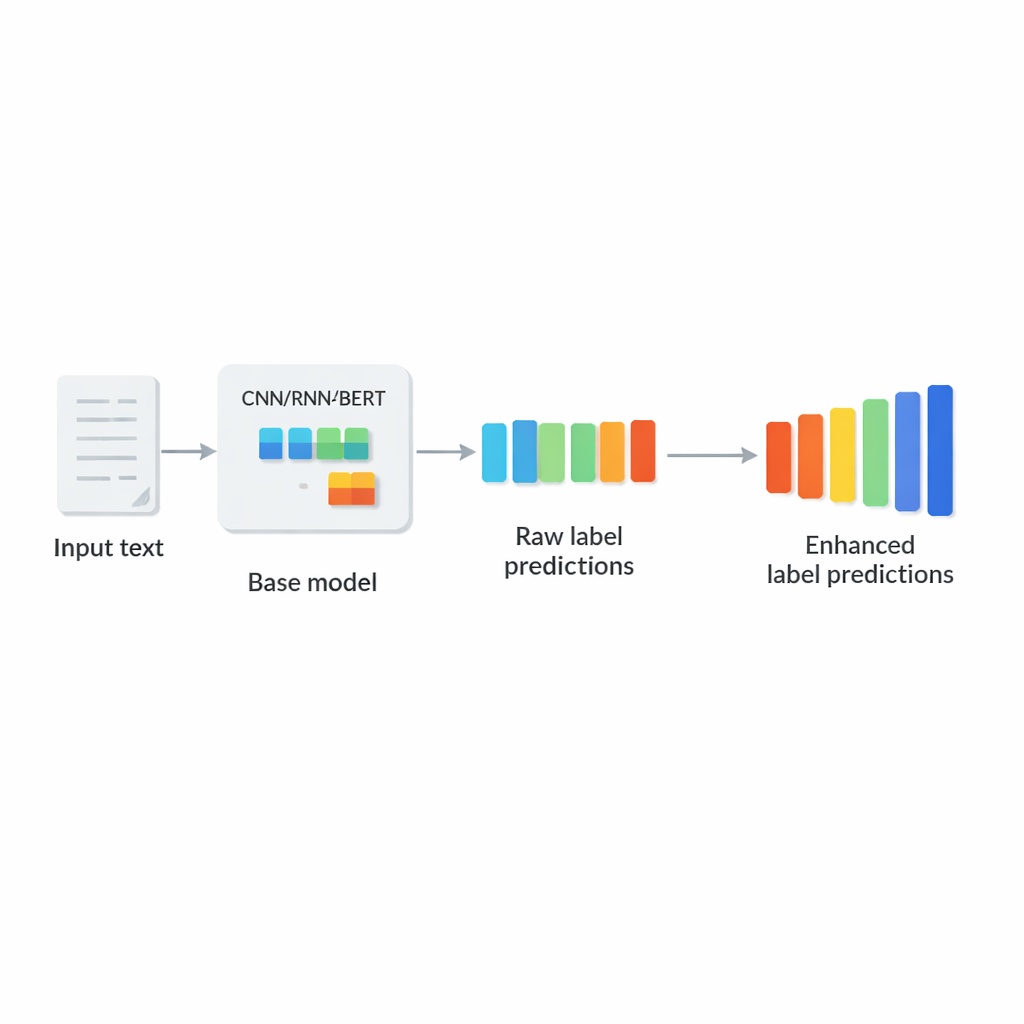
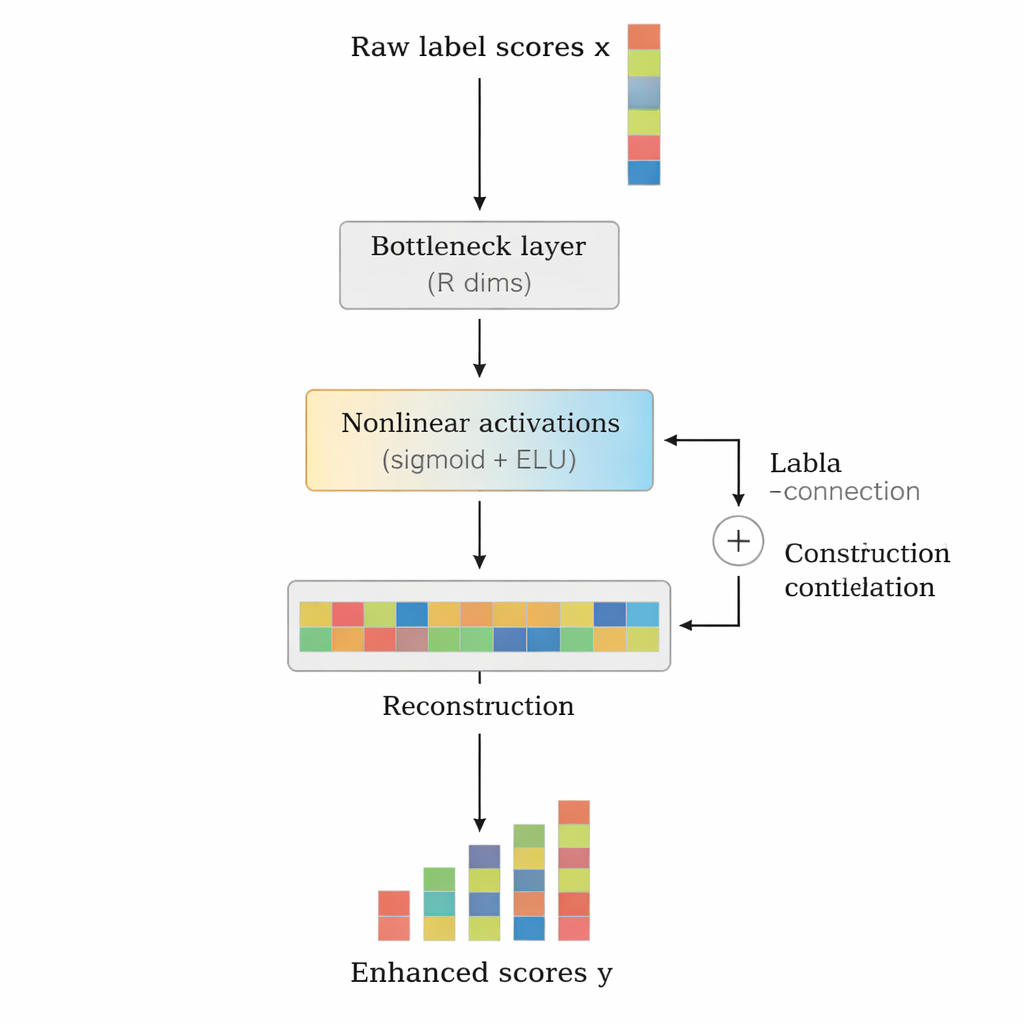
De auteurs stellen LCENet voor als een lichtgewicht, plug-and-play module die achter elke bestaande deep-tekstclassificator geplaatst kan worden. In plaats van te veranderen hoe het basismodel tekst verwerkt, neemt LCENet de ruwe labelscores die het produceert en laat ze door een compact “bottleneck” lopen dat het systeem dwingt een laag-dimensionale representatie te ontdekken waarin gerelateerde labels bij elkaar clusteren. Niet-lineaire activatiefuncties laten de module complexe, hogere-orde associaties vastleggen, niet alleen eenvoudige paargewijze verbanden. Een residuele of skip-verbinding voert de originele scores direct naar de output naast de gecorrigeerde scores, wat de training stabiliseert en voorkomt dat de toevoeging het systeem makkelijk slechter maakt. Cruciaal is dat LCENet het aantal extra parameters reduceert van iets dat kwadratisch zou groeien met het aantal labels tot een veel beter beheersbare lineaire groei, zodat het haalbaar blijft zelfs bij honderdduizenden labels.
De voordelen aantonen over modellen en datasets heen
Om te testen of LCENet echt algemeen toepasbaar is, koppelden de auteurs het aan vier zeer verschillende deep-modellen, waaronder CNN- en BERT-gebaseerde architecturen, evenals systemen die specifiek zijn ontworpen voor biomedische en extreme-labelomgevingen. Ze evalueerden deze combinaties op drie openbare benchmarkdatasets: een Europese juridische corpus (EUR-Lex), een Amazon-productdataset (AmazonCat-13K) en een enorme Wikipedia-collectie met meer dan een half miljoen labels (Wiki-500K). Over alle modellen, datasets en zes metrieken gericht op rangschikking verbeterde LCENet consistent de prestaties, soms met meer dan vijf procentpunten in top-1 precisie op de grootste dataset. Trainingscurves laten bovendien zien dat LCENet vaak het aantal trainingsstappen dat nodig is om een bepaalde nauwkeurigheid te bereiken bijna halveert, omdat de toegevoegde labelcorrelaties vanaf het begin duidelijkere leersignalen geven.
Waarom dit belangrijk is voor alledaagse systemen
Voor praktijkmensen die al vertrouwen op deep-modellen om tekst te labelen, biedt LCENet een praktische manier om nauwkeurigheid en traingsnelheid te verbeteren zonder hun systemen te herontwerpen of nieuwe soorten annotaties te verzamelen. Het behandelt de labelruimte zelf als een bron van kennis, leert welke tags geneigd zijn samen voor te komen of elkaar uit te sluiten, en stuurt voorspellingen dienovereenkomstig bij. Hoewel ontwikkeld voor tekst, kan hetzelfde idee om voorspellingen te verbeteren met geleerde relaties tussen outputs ook toegepast worden op afbeeldingen, multimodale data en andere gestructureerde predictietaken. Simpel gezegd helpt LCENet machines te “herinneren” hoe labels zich tot elkaar verhouden, zodat ze minder raden als losse vakjes en meer als een deskundige die begrijpt hoe concepten samenhangen.
Bronvermelding: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Trefwoorden: extreme multi-label tekstclassificatie, labelcorrelatie, deep learning, tekstclassificatie, neurale netwerken