Clear Sky Science · nl
DMSCA: dynamische multi-schaal kanaal-ruimtelijke aandacht voor verbeterde kenmerkrepresentatie in convolutionele neurale netwerken
Computers leren beter aandacht te schenken
Moderne beeldherkenningssystemen kunnen katten, verkeersborden en tumoren in scans herkennen — maar weten niet altijd waar ze in een afbeelding op moeten letten. Dit artikel introduceert een nieuwe manier om deze systemen te helpen zich te concentreren op de belangrijkste delen van een afbeelding, waardoor de nauwkeurigheid verbetert en ze betrouwbaarder worden in de rommelige omstandigheden van het echte leven. De methode, Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), wordt in bestaande convolutionele neurale netwerken ingeplugd en helpt ze zowel het "wat" als het "waar" in een afbeelding intelligenter te zien.
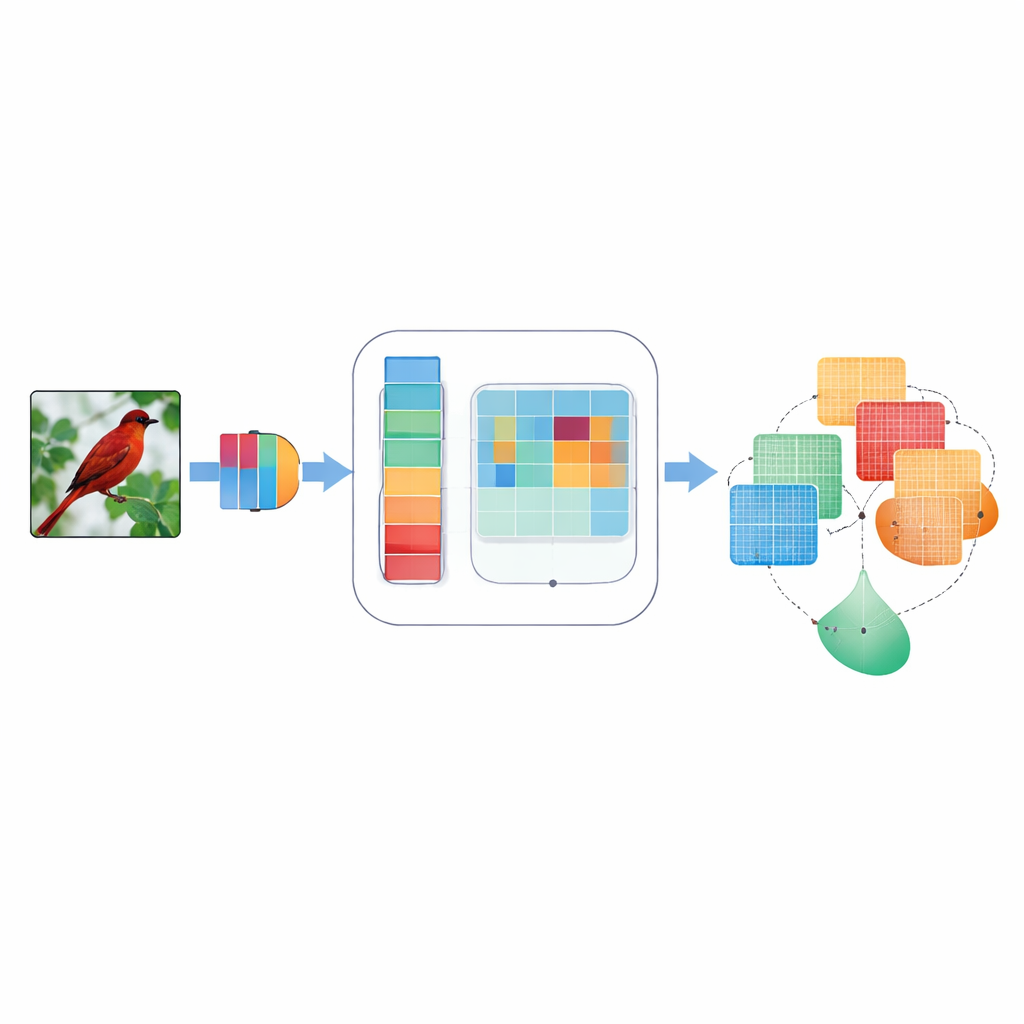
Waarom focus ertoe doet voor machinaal zien
Convolutionele neurale netwerken, de werkpaarden achter veel visietoepassingen, behandelen normaal gesproken elk intern signaal als even belangrijk. Dat betekent dat de vage rand van een vogelvleugel en een stuk lucht vergelijkbare aandacht kunnen krijgen, terwijl slechts één daarvan helpt bij het identificeren van de soort. Eerdere "aandachts"-methoden probeerden dit te verhelpen door sommige interne signalen hoger te wegen dan andere — ofwel over kanaalachtige kleurdimensies of over de tweedimensionale lay-out van een afbeelding. Maar die methoden gebruikten vaak vaste, handmatig ontworpen regels, bekeken slechts één schaal van detail tegelijk, of combineerden informatie op een starre manier die zich niet aan verschillende afbeeldingen kon aanpassen. Daardoor misten ze soms fijne details, negeerden richtingen zoals "horizontaal versus verticaal", of hadden ze moeite wanneer afbeeldingen ruisig of wazig waren.
Een slimmer aandacht-inzetstuk
DMSCA is ontworpen als een kleine, aan te sluiten module die in bekende neurale netwerken zoals ResNet kan worden geplaatst zonder hun algehele structuur te veranderen. Van binnen coördineert het zes nauw verbonden onderdelen die samenwerken in plaats van geïsoleerd te opereren. Eén onderdeel vat de hele afbeelding samen om te vangen wat er globaal gebeurt, terwijl een ander leert hoe sterk elk intern kanaal moet meetellen, met een regelbare "temperatuur" die beslissingen scherper of zachter kan maken waar nodig. Aan de ruimtelijke kant gebruikt DMSCA gelijktijdig meerdere venstergroottes om zowel fijne texturen als grotere vormen vast te leggen, en het besteedt expliciet aandacht aan horizontale en verticale richtingen zodat lange randen of strepen niet wegvallen. Ten slotte, in plaats van deze signalen simpelweg op te tellen, leert de module per pixel hoeveel vertrouwen te geven aan "wat"-informatie uit kanalen versus "waar"-informatie uit ruimte.
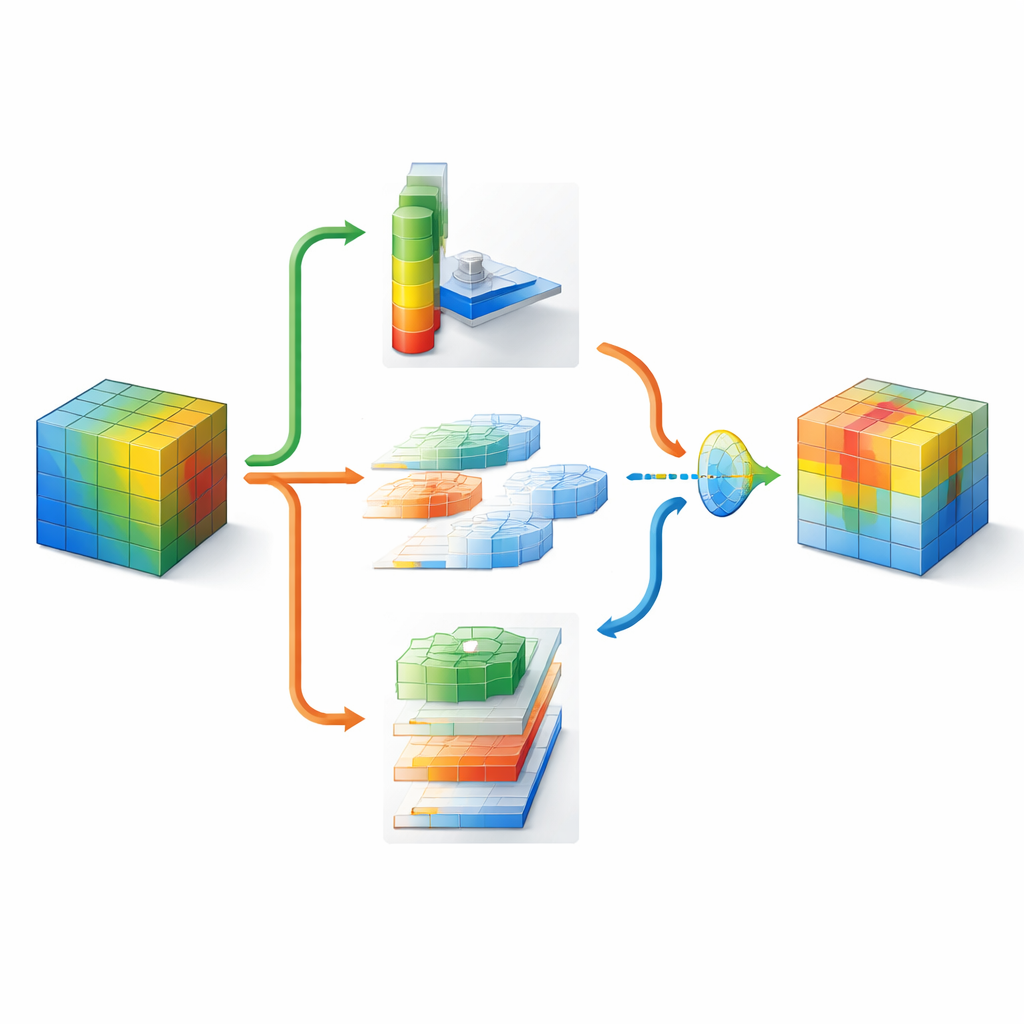
Afbeeldingen bekijken op veel schalen en richtingen
Om te begrijpen waarnaar in een afbeelding gekeken moet worden, comprimeert DMSCA eerst de vele interne kanalen tot een compacte tweelaagse kaart die zowel achtergrondtrends als opvallende kenmerken benadrukt. Vervolgens voert het deze kaart door meerdere parallelle filters van verschillende omvang. Kleine filters zien fijnmazige details zoals vacht of veren, terwijl grotere filters vormen vastleggen zoals hele koppen of lichamen. Parallel daaraan scant een directionele eenheid afzonderlijk langs rijen en kolommen, waarbij de exacte positie van belangrijke structuren behouden blijft. Deze horizontale en verticale beelden mogen vervolgens met elkaar interageren, zodat een sterk verticaal signaal bijvoorbeeld de juiste horizontale locaties kan versterken. Het resultaat is een rijke aandachtskaart die het netwerk niet alleen vertelt dat iets belangrijk is, maar ook waar het zich bevindt en op welke schaal.
Het netwerk laten beslissen wat het meest telt
Aangezien verschillende delen van een afbeelding verschillende strategieën kunnen vereisen, legt DMSCA geen vast recept op voor het combineren van kanaal- en ruimtelijke informatie. In plaats daarvan bouwt het een klein "sluisje" dat beide onderzoekt en — onafhankelijk voor elke pixel — beslist hoeveel gewicht aan elk type te geven. In een rommelige achtergrond kan het systeem meer vertrouwen op welke kanalen opvallen, terwijl het rondom scherpe objectranden ruimtelijke signalen kan benadrukken. Een laatste adaptieve activatiefase werkt vervolgens als een aangeleerde dimmer, die echt informatieve regio's versterkt en resterende ruis dempt. Dit gefaseerde proces helpt de aandacht van het netwerk te richten op coherente, objectgerelateerde regio's, zoals bevestigd door visuele hittekaarten en kwantitatieve maten voor hoe goed de gemarkeerde gebieden overeenkomen met grondwaarheidsobjecten.
Scherper zicht met geringe extra inspanning
De auteurs testten DMSCA op verschillende standaardbenchmarks, van kleine verzamelingen tiny images tot de grootschalige ImageNet-dataset. Wanneer toegevoegd aan populaire ResNet-modellen verbeterde DMSCA consequent de classificatienauwkeurigheid — met tot ongeveer 2 procentpunt op kleine sets en 1,5 procentpunt op ImageNet — en overtrof het een reeks bestaande aandachtmethoden. Het maakte modellen ook robuuster tegen veelvoorkomende beelddegradaties zoals ruis, onscherpte en zware compressie, en verbeterde de prestaties bij gerelateerde taken zoals objectdetectie en scene-annotatie. Deze winst ging gepaard met slechts een bescheiden toename in reken- en geheugenbelasting. Simpel gezegd geeft DMSCA convolutionele netwerken een flexibeler en contextbewuster middel om te beslissen waarnaar te kijken en wat te negeren, waarmee machinaal zien een stap dichter bij de selectieve focus van het menselijk zicht komt.
Bronvermelding: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Trefwoorden: aandachtmechanismen, beeldherkenning, convolutionele neurale netwerken, kenmerkrepresentatie, robuuste computervisie