Clear Sky Science · nl
Verbetering van cross-modale retrieval via labelgrafoptimalisatie en hybride verliesfuncties
Slimmer zoeken tussen beelden en woorden
Dagelijks scrollen we door een oceaan aan foto’s, video’s en tekst. Het precies vinden van wat we willen—bijvoorbeeld alle afbeeldingen die bij een korte bijschrift passen—hangt af van hoe goed computers beelden en taal aan elkaar kunnen koppelen. Dit artikel onderzoekt een nieuwe manier om die koppeling nauwkeuriger te maken, vooral in rommelige, alledaagse scènes waarin veel ideeën en objecten tegelijk voorkomen. Het resultaat zijn slimmere zoekhulpmiddelen die beter “begrijpen” wat we bedoelen, niet alleen wat we intypen.
Waarom meerdere betekenissen in één afbeelding ertoe doen
Een enkele afbeelding toont zelden slechts één ding. Een foto van een walvis die uit het water springt kan tegelijk de oceaan, de lucht, golven, wind en wildlife omvatten. Wanneer we zo’n afbeelding labelen, koppelen we vaak meerdere labels die op subtiele manieren met elkaar verbonden zijn. Bestaande zoeksystemen behandelen deze labels meestal alsof het onafhankelijke vinkvakjes zijn. Die vereenvoudiging gooit nuttige aanwijzingen weg: als “walvis” vaak samen met “zee” voorkomt, zou het voorkomen van het ene de kans op het andere moeten verhogen. Dit werk richt zich op het vastleggen van die verborgen verbanden tussen labels, zodat een zoekopdracht naar één concept ook beelden en teksten vindt die nauw verwante concepten uitdrukken.

Een web van verbonden labels opbouwen
De auteurs introduceren een techniek genaamd een Tweelaagse Graph Convolutional Network, of L2-GCN, om te modelleren hoe labels zich tot elkaar verhouden. In eenvoudige termen wordt elk label (zoals “lucht” of “walvis”) behandeld als een knooppunt in een netwerk, en lijnen tussen knooppunten geven weer hoe vaak die labels samen voorkomen. De methode laat elk label herhaaldelijk "luisteren" naar zijn buren, waarbij informatie van gerelateerde labels wordt vermengd terwijl het label zijn eigen identiteit behoudt. Na dit proces resulteert het systeem in rijkere labelbeschrijvingen die beter vastleggen hoe echte scènes zijn opgebouwd, van parallelle ideeën (“zee” en “strand”) tot meer gelaagde relaties (“dier” en “walvis”).
Beelden en tekst leren een gemeenschappelijke ruimte te delen
Natuurlijk zijn labels maar de helft van het verhaal; het systeem moet ook leren van de beelden en teksten zelf. Het raamwerk gebruikt gevestigde tools om ruwe pixels en woorden om te zetten in numerieke kenmerken, en plaatst vervolgens beide typen data in een gedeelde ruimte waar hun betekenissen direct vergeleken kunnen worden. Een adversariële module—losjes geïnspireerd op het duw-en-trek van generative adversarial networks—ontmoedigt het model ervan zich vast te klampen aan eigenaardigheden van alleen beelden of alleen tekst. Dit helpt de gedeelde ruimte zich op de inhoud in plaats van het formaat te concentreren, zodat een foto van een drukke straat en een korte bijschrift die het beschrijft dicht bij elkaar komen te liggen in deze gemeenschappelijke betekeniskaart.
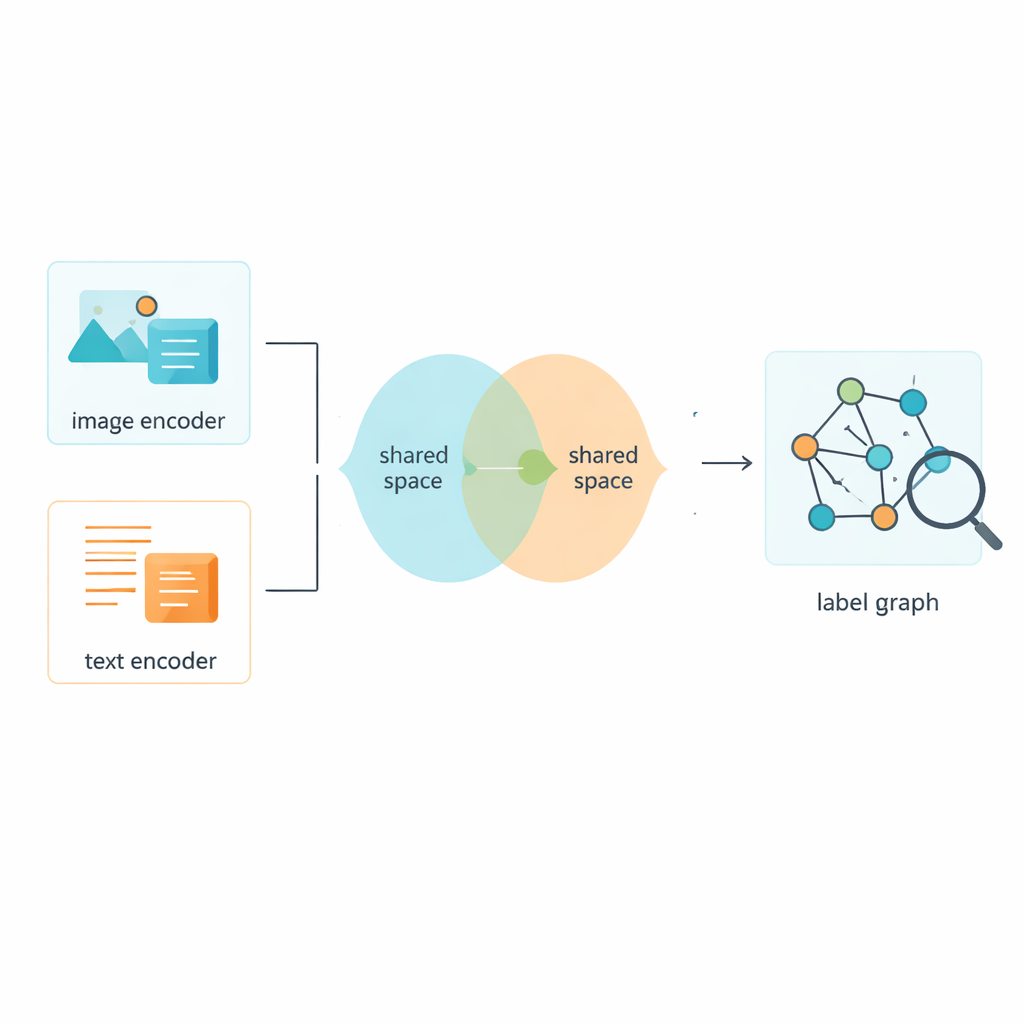
Een hybride trainingsstrategie voor scherpere onderscheidingen
Het trainen van zo’n systeem vereist meer dan één leerregel. De auteurs ontwerpen een gecombineerde verliesfunctie, Circle-Soft genoemd, die twee complementaire ideeën mengt. Het ene deel moedigt voorbeelden uit dezelfde categorie aan om stevig bij elkaar te clusteren terwijl verschillende categorieën op een flexibele, adaptieve manier uit elkaar worden geduwd. Het andere deel richt zich op hoe goed beelden en teksten die dezelfde scène beschrijven over modaliteiten heen uitlijnen. Een instelbaar gewicht balanceert deze twee doelen zodat het model niet overfit op alleen nette categorievormen of alleen cross-modale uitlijning. Extra classificatie- en adversariële verliezen bevorderen verder de consistentie tussen de verfijnde labels en de gedeelde beeld–tekstkenmerken.
Hoeveel beter maakt dit zoeken?
Om te onderzoeken of deze ideeën daadwerkelijk beter zoeken opleveren, testten de auteurs hun methode op drie veelgebruikte verzamelingen van real-world beeld–tekstparen: MIRFlickr, NUS-WIDE en MS-COCO. Deze datasets bevatten duizenden tot honderden duizenden foto’s met bijbehorende tags of bijschriften, en bestrijken alledaagse scènes van stadsstraten tot wildlife. Over alle drie benchmarks heen stak de nieuwe benadering consequent boven een breed scala aan concurrerende methoden uit, inclusief andere geavanceerde systemen die al grafgebaseerde labelmodellering gebruiken. De winst—ongeveer een halve tot een hele procentpunt in een strikte retrievalscore—klinkt misschien bescheiden, maar in volwassen benchmarks duiden zelfs kleine verbeteringen op een preciezer begrip van inhoud. Praktisch betekent dit dat wanneer een gebruiker een korte tekstquery invoert of een afbeelding indient, het systeem meer kans heeft de meest relevante cross-modale matches hoog in de resultatenlijst te tonen.
Wat dit betekent voor dagelijkse gebruikers
Voor niet-specialisten is de kernboodschap dat slimmer omgaan met labels en trainingsregels merkbaar kan verbeteren hoe machines plaatjes en woorden koppelen. Door labels te behandelen als een onderling verbonden web in plaats van geïsoleerde tags, en door zorgvuldig te vormen hoe visuele en tekstuele informatie samenkomen in een gedeelde ruimte, maakt dit raamwerk cross-modale zoekopdrachten betrouwbaarder in complexe, veelonderwerpige scènes. In de loop van de tijd zouden technieken zoals deze kunnen zorgen voor intuïtievere fotobibliotheken, mediaplatforms en intelligente assistenten die vinden wat we bedoelen—zelfs wanneer onze woorden niet perfect overeenkomen met de beelden die we voor ogen hebben.
Bronvermelding: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Trefwoorden: image-text retrieval, multimodale zoekopdracht, graph neural networks, semantische labels, machine learning